Page 1
M á s t e r O f i c i a l d e E s t a d í s t i c a A p l i c a d a
Autor:
Laura Delgado Antequera
Tutores del trabajo:
José Antonio Roldán Nofuentes
Miguel Ángel Montero Alonso
Departamento de Estadística e Investigación Operativa, Universidad de Granada.
2015
Page 2
Evaluación y comparación de Test Diagnósticos Binarios
1
Page 3
Evaluación y comparación de Test Diagnósticos Binarios
2
Índice
1. Test Diagnóstico Binario ................................................................................................ 3
1.1. Introducción .............................................................................................................. 3
1.2. Parámetros de un test diagnóstico ........................................................................... 5
2. Estimación para un Test Diagnóstico Binario ................................................................ 9
2.1. Introducción .............................................................................................................. 9
2.2. Estimación bajo un muestreo transversal. ................................................................ 9
2.3. Estimación bajo un muestreo caso-control. ............................................................ 11
2.4. Programa en R. ........................................................................................................ 13
2.5. Ejemplo. ................................................................................................................... 14
3. Comparación de dos Test Diagnósticos Binarios......................................................... 17
3.1. Introducción. ........................................................................................................... 17
3.2. Comparación bajo un diseño apareado. ................................................................. 17
3.3. Comparación bajo un diseño caso-control. ............................................................. 22
3.4. Programa en R ......................................................................................................... 26
3.5. Ejemplo. ................................................................................................................... 27
4. Conclusiones................................................................................................................ 30
5. Bibliografía .................................................................................................................. 31
Anexo I ............................................................................................................................... 34
Anexo II .............................................................................................................................. 38
Page 4
Evaluación y comparación de Test Diagnósticos Binarios
3
1. Test Diagnóstico Binario
1.1. Introducción
El diagnóstico de una enfermedad puede ser considerado la base de la práctica
médica, pues es la clave que conduce al médico a elegir uno u otro tratamiento para
lograr su propósito. Un test diagnóstico es aquella prueba que, aplicada sobre un
individuo, determina si éste padece o no una determinada enfermedad.
A menudo, los profesionales sanitarios se cuestionan ¿qué tratamiento será más
efectivo para una determinada enfermedad?, ¿es mejor un tratamiento que otro?, ¿en
qué medida?, ¿sobrevivirá el paciente los próximos 3 años?, etc. Las respuestas a estos
interrogantes, nos conducen a la Estadística. Por la información y experiencia que
posee, el profesional puede tomar decisiones, aunque es conveniente que éstas se
fundamenten objetivamente a través de los métodos estadísticos más apropiados a cada
situación. La estadística es el único método científico adecuado para validar los
razonamientos inductivos que se llevan a cabo en las Ciencias de la Salud.
En palabras de la Organización Mundial de la Salud “En todos los dominios de las
ciencias de la salud, en su vertiente clínica, administrativa o de la investigación, es
indispensable conocer los principios estadísticos para comprender bien los problemas y
el profesional de la salud necesita de los datos estadísticos para tomar decisiones
válidas”.
Las pruebas diagnósticas son fundamentales en la práctica de la medicina moderna.
Estas, como ya hemos mencionado, consisten en aplicar una prueba médica para
confirmar o no la presencia de una determinada enfermedad, con tres propósitos básicos
(McNeil y Adelstein, (1976); Sox et al., (1989)):
- Proveer una información fiable sobre la condición del paciente.
- Influenciar en el plan de cuidado del paciente.
- Entender los mecanismos de la enfermedad y su historia natural a través
de la investigación.
La utilidad de un test diagnóstico reside en que nos permite diferenciar dos
(binarios) o más condiciones, que podrían ser confundidas. Por ejemplo, para
Page 5
Evaluación y comparación de Test Diagnósticos Binarios
4
diferenciar entre distintas enfermedades o la condición de sano y enfermo. Los test
diagnósticos se clasifican en:
- Binarios: Son aquellos que tienen 2 posibles resultados: uno positivo, que
indica la presencia provisional de la enfermedad, y otro resultado negativo, que
indicaría la ausencia provisional de la enfermedad. Por ejemplo, un test de
embarazo.
- Cuantitativos o continuos: Este tipo de test devuelve un valor numérico
que permite al profesional evaluar la condición en la que se encuentra el
paciente. Por ejemplo, un análisis de sangre.
- Ordinales: son aquellos que devuelven valores ordinales, los cuales nos
permiten, por ejemplo, clasificar la presencia de la enfermedad en
“definitivamente no”, “probablemente no”, “probablemente sí”,
“definitivamente sí”.
En la interpretación de un test diagnóstico se deben tener en cuenta tres factores
principales: su habilidad para distinguir entre enfermos y sanos, las características
específicas de cada individuo y el ambiente en el que se lleva a cabo el test diagnóstico.
En los estudios sobre test diagnósticos, el primer paso consiste en evaluar su validez,
es decir, la probabilidad de que exista sesgo por características del diseño del estudio.
Una vez hemos confirmado la validez del estudio, se analiza la correcta interpretación
de los resultados, pues si éstos no son capaces de discriminar entre las condiciones bajo
estudio, el test diagnóstico carecerá de utilidad. Es importante ser consciente de que la
certeza absoluta del diagnóstico es inalcanzable, independientemente del número de
observaciones o pruebas diagnósticas que se realicen, ya que se apoya en
probabilidades, por lo que el objetivo del médico no residirá en alcanzar la certeza, sino
en reducir el nivel de incertidumbre lo suficiente como para tomar una decisión
terapéutica fiable (Kassirer, (1989)).
Como venimos comentando, en el campo de la medicina, uno de los factores que
intervienen en el diagnóstico es medir la exactitud de dos test diagnósticos. Para ello, se
debe disponer de un estimador insesgado de la exactitud del test, por lo que es
conveniente conocer el estado de la enfermedad en cada paciente, independientemente
del resultado del test diagnóstico. Un procedimiento del tipo conocido como GOLD
ESTÁNDAR nos revela el estado real del individuo. Sin embargo, en la práctica, no es
Page 6
Evaluación y comparación de Test Diagnósticos Binarios
5
común aplicar este procedimiento a todos los individuos de una muestra, pues suele
tratarse de técnicas invasivas y ocasionaría un riesgo para el paciente, por lo que
algunos de los estados de la muestra serán desconocidos. Esto se conoce como el
problema de la verificación parcial de la enfermedad. En lo que recoge el presente
documento, supondremos que todos los problemas son de verificación completa de la
enfermedad mediante un Gold Estándar.
1.2. Parámetros de un test diagnóstico
La calidad de un test diagnóstico binario se mide por su habilidad para discriminar
una de dos condiciones (sano o enfermo) en la que se encuentra el individuo. El
potencial del test se puede cuantificar con distintas medidas como: la sensibilidad y
especificidad, los valores predictivos, razones de verosimilitud (LR), el área bajo la
curva ROC (AUC), el índice de Youden y odds-ratio (OR). Diferentes medidas de la
calidad del diagnóstico se relacionan con aspectos distintos del procedimiento del
diagnóstico, es decir, algunas medidas se usan para evaluar la propiedad discriminatoria
del test -utilizada en el ámbito de la salud- y otras para evaluar su habilidad predictiva
con intención de predecir la probabilidad de que un individuo padezca una enfermedad.
Además, hay que tener en cuenta que estas medidas que hemos mencionado no son
indicadores fijos de la calidad del test, sino que hemos de recordar que son sensibles a
las características de la población, así como muchas también dependen de la
prevalencia1 de la enfermedad. Por tanto, se considera especialmente importante
conocer cómo interpretar los resultados y bajo qué condiciones se realiza el estudio.
Consideraremos los resultados organizados en una Tabla 2x2:
Resultado del test
T �̅�
Estado D 𝑠1 𝑠0 s
�̅� 𝑟1 𝑟0 r
𝑠1 + 𝑟1 𝑠0 + 𝑟0 n
En la cual los datos de la verdadera condición del individuo, conocida mediante la
aplicación de un test diagnóstico Gold Estándar, (D:= enfermo; �̅�:= no enfermo) se
1 La prevalencia es la probabilidad de que el individuo padezca la enfermedad. La denotaremos
𝑝 = 𝑃(𝐷)
Page 7
Evaluación y comparación de Test Diagnósticos Binarios
6
recoge en las filas mientras las columnas indican los resultados del test diagnóstico
binario (T:= test positivo; �̅�:= test negativo).
A continuación procedemos con la definición de algunos conceptos básicos para el
desarrollo del tema.
Sensibilidad y especificidad
Las probabilidades de acierto del test diagnóstico vienen recogidas en dos medidas
como son la sensibilidad y la especificidad. Las cuales definimos a continuación:
La sensibilidad (Se) de un test es la probabilidad de que el resultado del
test sea positivo cuando el individuo está enfermo. Esto es:
𝑆𝑒 = 𝑃(𝑇|𝐷).
Al acierto al que hace referencia la sensibilidad se le denomina Verdadero Positivo
(TP).
La especificidad (Sp) es la probabilidad de que el resultado del test sea
negativo cuando el individuo no está enfermo. Esto es:
𝑆𝑝 = 𝑃(�̅�|�̅�).
Al acierto al que hace referencia la especificidad se le denomina Verdadero
Negativo (TN).
Por otro lado, la probabilidad de fallo del test se “traduce”, en términos de las
probabilidades condicionadas, en las denominadas probabilidad de Falso Positivo (FP)
y probabilidad de Falso Negativo (FN), las cuales vienen dadas por:
𝑃(𝐹𝑁) = 𝑃(�̅�|𝐷) = 1 − 𝑆𝑒,
Page 8
Evaluación y comparación de Test Diagnósticos Binarios
7
𝑃(𝐹𝑃) = 𝑃(𝑇|�̅�) = 1 − 𝑆𝑝.
Según estas definiciones, resulta lógico pensar que un test resultará más útil para
descartar la enfermedad cuanto menor sea la probabilidad de un falso negativo, es decir,
cuanto mayor sea la sensibilidad. Mientras utilizaremos el test para confirmar la
enfermedad cuanto mayor sea la especificidad, lo que indicará una menor probabilidad
de falso positivo.
Valores Predictivos Positivos, Valores Predictivos Negativos. Curva ROC.
Tanto la sensibilidad como la especificidad proporcionan información sobre la
probabilidad de obtener un resultado concreto en función de la verdadera condición del
individuo, sin embargo, en la práctica, no se conoce. Por tanto, nos preguntamos ahora
“si el resultado ha dado positivo (negativo). ¿Cuál es la probabilidad de que realmente
sea la verdadera condición del individuo?”. A este tipo de preguntas nos responderán
los valores predictivos.
El Valor Predictivo Positivo (VPP) es la probabilidad de padecer la
enfermedad si el resultado del test es positivo. Por el Teorema de Bayes, esta
probabilidad se interpreta como la proporción entre los resultados verdaderos
positivos sobre los resultados positivos del test.
𝑉𝑃𝑃 = 𝑃(𝐷|𝑇) =𝑃(𝑇|𝐷) · 𝑃(𝐷)
𝑃(𝑇)=
𝑝𝑆𝑒
𝑝𝑆𝑒 + (1 − 𝑝)(1 − 𝑆𝑝).
El Valor Predictivo Negativo (VPN) es la probabilidad de que un sujeto
cuyo test ha resultado negativo, esté realmente sano. De nuevo por el teorema de
Bayes, obtenemos el valor de esta probabilidad:
𝑉𝑃𝑃 = 𝑃(𝐷|�̅�) =𝑃(�̅�|𝐷) · 𝑃(𝐷)
𝑃(�̅�)=
(1 − 𝑝)𝑆𝑝
(1 − 𝑆𝑒)𝑝 + (1 − 𝑝)𝑆𝑝.
Ambas medidas dependen de la prevalencia de la enfermedad.
Page 9
Evaluación y comparación de Test Diagnósticos Binarios
8
Razones de verosimilitud
La prevalencia es un factor determinante en los valores predictivos de un test, por lo
que no es recomendable usarlos para comparar dos métodos diagnósticos. Es por esto
que se hace necesario determinar unos índices que no dependan de la prevalencia de la
enfermedad, los conocidos como Razones de verosimilitud, que miden cuánto es más
probable un resultado positivo (negativo) según la presencia o ausencia de la
enfermedad.
𝐿𝑅+ =𝑆𝑒
1−𝑆𝑝 es el cociente entre la probabilidad de que el resultado del
test sea positivo en pacientes enfermos y la probabilidad de que el resultado sea
positivo en pacientes sanos.
𝐿𝑅− =1−𝑆𝑒
𝑆𝑝 es el cociente entre la probabilidad de que el resultado del
test sea negativo en pacientes enfermos y la probabilidad de que el resultado sea
negativo en pacientes sanos.
Esta medida relaciona la sensibilidad y especificidad, y como no depende de la
prevalencia, se puede utilizar para la comparación de pruebas en un mismo diagnóstico.
Índice de Youden
El índice de Youden es la suma de la sensibilidad y especificidad menos la unidad,
esto es,
𝐽 = 𝑆𝑒 + 𝑆𝑝 − 1.
A todo test diagnóstico hay que exigirle que su índice de Youden sea mayor que 0. Si
vale 0 entonces la sensibilidad y la especificidad son complementarias, y si su valor es
menor que 0 entonces los resultados del test deben intercambiarse (el resultado positivo
es en realidad el negativo y viceversa).
En el desarrollo de este trabajo, nos centraremos en los parámetros Sensibilidad y
Especificidad, por ser los más importantes (los restantes se obtienen a partir de estos).
Page 10
Evaluación y comparación de Test Diagnósticos Binarios
9
2. Estimación para un Test Diagnóstico Binario
2.1. Introducción
Un test diagnóstico binario, como ya se ha definido, es una prueba médica que da
lugar a dos posibles resultados que nos indica la presencia (si el resultado es positivo) o
ausencia (si es negativo) de una determinada enfermedad.
El problema con el que se encuentran los test diagnósticos, en general y en particular
el caso binario, es que pueden aportar resultados erróneos. Por tanto, conviene conocer
su grado de exactitud que viene expresada en términos de probabilidades o funciones de
probabilidad. Para evaluar el grado de exactitud de un test diagnóstico, es preciso
conocer la condición en la que se encuentra cada individuo respecto a la enfermedad, es
decir, si la padece o no. El procedimiento que nos determina de forma objetiva si el
individuo realmente padece la enfermedad es el gold estándar.
Por tanto, según la exactitud de los resultados, tenemos 2 formas de abordar el
diagnóstico de una determinada enfermedad: el test diagnóstico binario y el gold
estándar. Sin embargo, el gold estándar suele ser un test costoso, arriesgado, pues
muchas veces requiere de técnicas invasivas, y además hay casos, como en el campo de
la psiquiatría, que no existe tal prueba.
A continuación se presenta la estimación de la sensibilidad y la especificidad bajo un
muestreo transversal y un muestreo de caso control.
2.2. Estimación bajo un muestreo transversal.
Uno de los muestreos más usuales es el muestreo transversal, en el que aplicamos el
test diagnóstico binario y el gold estándar independientemente a cada uno de los
individuos que forman una muestra aleatoria de tamaño n. En lo que sigue, supongamos
que tenemos una población de n individuos que pueden padecer o no una determinada
enfermedad. Imaginemos que tenemos un test Gold Estándar que nos permite conocer,
mediante la variable D, el estado verdadero del individuo. De esta forma, la variable
binaria D se define:
𝐷 = {1 𝑠𝑖 𝑒𝑙 𝑖𝑛𝑑𝑖𝑣𝑖𝑑𝑢𝑜 𝑝𝑎𝑑𝑒𝑐𝑒 𝑙𝑎 𝑒𝑛𝑓𝑒𝑟𝑚𝑒𝑑𝑎𝑑
0 𝑠𝑖 𝑒𝑙 𝑖𝑛𝑑𝑖𝑣𝑖𝑑𝑢𝑜 𝑛𝑜 𝑝𝑎𝑑𝑒𝑐𝑒 𝑙𝑎 𝑒𝑛𝑓𝑒𝑟𝑚𝑒𝑑𝑎𝑑
Page 11
Evaluación y comparación de Test Diagnósticos Binarios
10
Por otra parte, se define prevalencia, y se denota por una p, como la probabilidad de
que un individuo de la población elegido al azar, padezca la enfermedad, es decir:
𝑝 = 𝑃(𝐷 = 1).
Consideremos un test diagnóstico binario cuya exactitud se puede evaluar con
respecto al gold estándar. Se define una variable aleatoria T como:
𝑇 = {1 𝑠𝑖 𝑒𝑙 𝑡𝑒𝑠𝑡 𝑑𝑖𝑎𝑔𝑛ó𝑠𝑡𝑖𝑐𝑜 𝑏𝑖𝑛𝑎𝑟𝑖𝑜 𝑑𝑎 𝑝𝑜𝑠𝑖𝑡𝑖𝑣𝑜0 𝑠𝑖 𝑒𝑙 𝑡𝑒𝑠𝑡 𝑑𝑖𝑎𝑔𝑛ó𝑠𝑡𝑖𝑐𝑜 𝑏𝑖𝑛𝑎𝑟𝑖𝑜 𝑒𝑠 𝑛𝑒𝑔𝑎𝑡𝑖𝑣𝑜
En la siguiente tabla recogemos las frecuencias absolutas observadas en la muestra
según los resultados de haber aplicado el test diagnóstico Binario (TDB) o el gold
estándar (GS).
Tabla 1: frecuencias absolutas de un test diagnóstico binario
Resultado del TDB
T=1 T=0
Verdadero estado (G.S)
D=1 𝑠1 𝑠0 𝑠 D=0 𝑟1 𝑟0 𝑟
𝑠1 + 𝑟1 𝑠0 + 𝑟0 𝑛
Si condicionamos las frecuencias de la tabla a las frecuencias marginales del gold
estándar, se deduce que las frecuencias 𝑠1 y 𝑟0 siguen una distribución binomial:
𝑠1~𝐵(𝑠, 𝑆𝑒) y 𝑟0~𝐵𝑖(𝑟, 𝑆𝑝). Esto nos permite definir estimadores puntuales, que son
estimadores de proporciones binomiales, para los parámetros de la sensibilidad y
especificidad:
𝑆�̂� =𝑠1
𝑠; 𝑆�̂� =
𝑟0
𝑟.
Page 12
Evaluación y comparación de Test Diagnósticos Binarios
11
Además, se conocen sus varianzas estimadas son:
𝑉𝑎�̂�(𝑆�̂�) =𝑆�̂�(1 − 𝑆�̂�)
𝑠;
𝑉𝑎�̂�(𝑆�̂�) =𝑆�̂�(1 − 𝑆�̂�)
𝑟 .
Estas estimaciones nos permiten definir un intervalo de confianza tanto para la
sensibilidad como para la especificidad, denominado intervalo score modificado (Yu,
W., et al., (2014)). Este intervalo es el intervalo de confianza para una proporción
binomial que presenta un mejor rendimiento:
𝑆𝑒 ∈ 0.5 +𝑠 +
𝑧1−
𝛼2
4
53𝑠 + 𝑧
1−𝛼2
2 (𝑆�̂� − 0.5) ±𝑧
1−𝛼2
𝑠 + 𝑧1−
𝛼2
2√𝑆�̂�(1 − 𝑆�̂�)𝑠 +
𝑧1−
𝛼2
2
4;
𝑆𝑝 ∈ 0.5 +𝑟 +
𝑧1−
𝛼2
4
53𝑟 + 𝑧
1−𝛼2
2 (𝑆�̂� − 0.5) ±𝑧1−𝛼/2
𝑟 + 𝑧1−
𝛼2
2√𝑆�̂�(1 − 𝑆�̂�)𝑟 +
𝑧1−
𝛼2
2
4
Donde 𝑧1−𝛼/2 es el percentil 100(1 − 𝛼)% de la distribución normal de media 0 y
desviación típica 1. Además, estos intervalos sólo son válidos si 𝑟, 𝑠 ≥ 10.
2.3. Estimación bajo un muestreo caso-control.
En un muestreo caso control, se aplica el gold estándar para conocer el verdadero
estado de los individuos. Se toman dos muestras, una de tamaño 𝑛1 sobre los individuos
que padecen la enfermedad bajo estudio y otra de tamaño 𝑛2 de individuos sanos. A
Page 13
Evaluación y comparación de Test Diagnósticos Binarios
12
ambas muestras se les aplica el test diagnóstico binario, para determinar el grado de
exactitud del mismo.
De esta forma, se define D como una variable aleatoria que toma los valores:
𝐷 = {1 𝑠𝑖 𝑒𝑙 𝑖𝑛𝑑𝑖𝑣𝑖𝑑𝑢𝑜 𝑝𝑎𝑑𝑒𝑐𝑒 𝑙𝑎 𝑒𝑛𝑓𝑒𝑟𝑚𝑒𝑑𝑎𝑑
0 𝑠𝑖 𝑒𝑙 𝑖𝑛𝑑𝑖𝑣𝑖𝑑𝑢𝑜 𝑛𝑜 𝑝𝑎𝑑𝑒𝑐𝑒 𝑙𝑎 𝑒𝑛𝑓𝑒𝑟𝑚𝑒𝑑𝑎𝑑
Consideremos un test diagnóstico binario cuya exactitud se quiere evaluar con
respecto al gold estándar. Se define la variable aleatoria T como:
𝑇 = {1 𝑠𝑖 𝑒𝑙 𝑡𝑒𝑠𝑡 𝑑𝑖𝑎𝑔𝑛ó𝑠𝑡𝑖𝑐𝑜 𝑏𝑖𝑛𝑎𝑟𝑖𝑜 𝑑𝑎 𝑝𝑜𝑠𝑖𝑡𝑖𝑣𝑜0 𝑠𝑖 𝑒𝑙 𝑡𝑒𝑠𝑡 𝑑𝑖𝑎𝑔𝑛ó𝑠𝑡𝑖𝑐𝑜 𝑏𝑖𝑛𝑎𝑟𝑖𝑜 𝑒𝑠 𝑛𝑒𝑔𝑎𝑡𝑖𝑣𝑜
En la siguiente tabla recogemos las frecuencias absolutas observadas en la muestra
según los resultados de haber aplicado el test diagnóstico Binario (TDB) o el gold
estándar (GS).
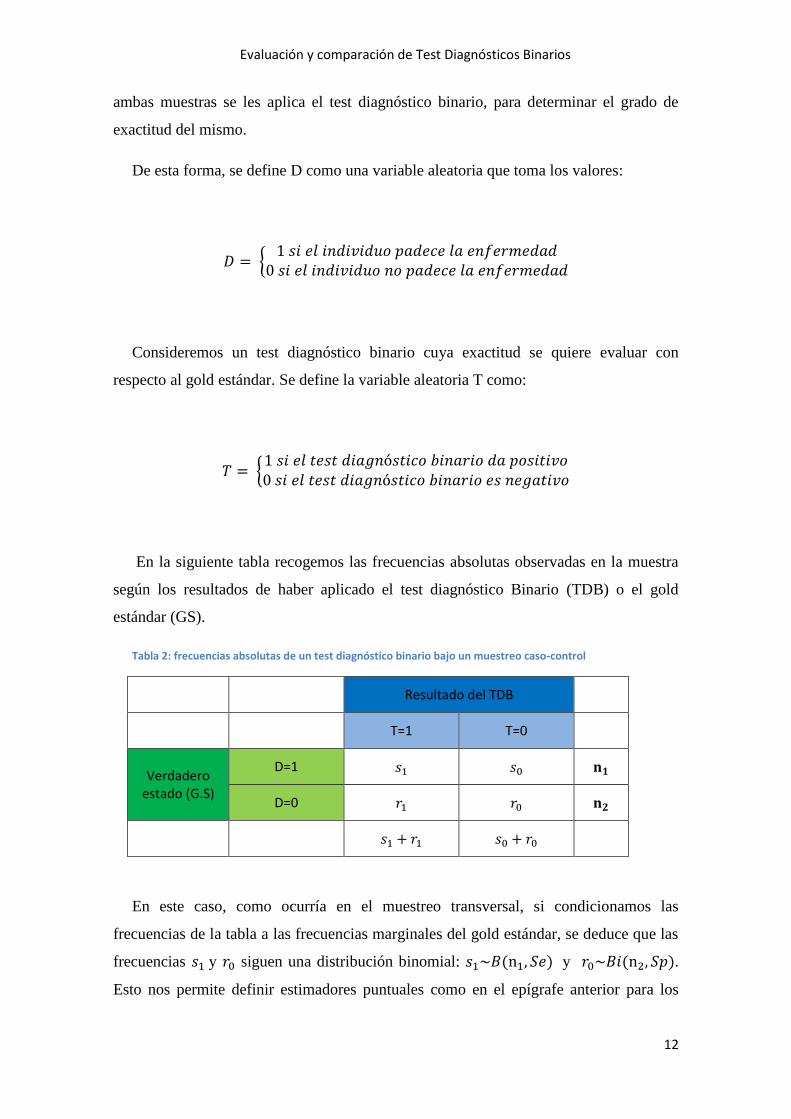
Tabla 2: frecuencias absolutas de un test diagnóstico binario bajo un muestreo caso-control
Resultado del TDB
T=1 T=0
Verdadero estado (G.S)
D=1 𝑠1 𝑠0 𝐧𝟏
D=0 𝑟1 𝑟0 𝐧𝟐
𝑠1 + 𝑟1 𝑠0 + 𝑟0
En este caso, como ocurría en el muestreo transversal, si condicionamos las
frecuencias de la tabla a las frecuencias marginales del gold estándar, se deduce que las
frecuencias 𝑠1 y 𝑟0 siguen una distribución binomial: 𝑠1~𝐵(n1, 𝑆𝑒) y 𝑟0~𝐵𝑖(n2, 𝑆𝑝).
Esto nos permite definir estimadores puntuales como en el epígrafe anterior para los
Page 14
Evaluación y comparación de Test Diagnósticos Binarios
13
parámetros de la sensibilidad y especificidad, sin más que sustituyendo r por n2 y s por
n1:
𝑆�̂� =𝑠1
n1; 𝑆�̂� =
𝑟0
n2.
Además, se conocen sus varianzas estimadas:
𝑉𝑎�̂�(𝑆�̂�) =𝑆�̂�(1 − 𝑆�̂�)
n1;
𝑉𝑎�̂�(𝑆�̂�) =𝑆�̂�(1 − 𝑆�̂�)
n2 .
Estas estimaciones nos permiten definir el intervalo score modificado (Yu,W., et al.,
(2014)) para Se y Sp:
𝑆𝑒 ∈ 0.5 +n1+
𝑧1−
𝛼2
4
53
n1+𝑧1−
𝛼2
2 (𝑆�̂� − 0.5) ±𝑧1−𝛼/2
𝑠+𝑧1−
𝛼2
2√𝑆�̂�(1 − 𝑆�̂�)n1 +
𝑧1−
𝛼2
2
4,
𝑆𝑝 ∈ 0.5 +n2+
𝑧1−
𝛼2
4
53
n2+𝑧1−
𝛼2
2 (𝑆�̂� − 0.5) ±𝑧1−𝛼/2
n2+𝑧1−
𝛼2
2√𝑆�̂�(1 − 𝑆�̂�)n2 +
𝑧1−
𝛼2
2
4.
Donde 𝑧1−𝛼/2 es el percentil 100(1 − 𝛼)% de la distribución normal de media 0 y
desviación típica 1. Además, estos intervalos sólo son válidos si n1, n2 ≥ 10.
2.4. Programa en R.
Creamos una función en R que recoge las estimaciones de los parámetros de
sensibilidad y especificidad de un test diagnóstico binario. A esta función la denotamos
Page 15
Evaluación y comparación de Test Diagnósticos Binarios
14
‘eetdb’ (Estimación de la Exactitud de un Test Diagnóstico Binario). Se consideran
como inputs aquellas frecuencias que hemos recogido en la tabla: 𝑠1, 𝑠0, 𝑟1 y 𝑟0.
En primer lugar, se comprueba que los datos son correctos dado que:
- El nivel de confianza considerado debe tomar un valor entre 0 y 1.
- Los parámetros no pueden tomar valores negativos.
- Los parámetros representan frecuencias absolutas, por lo que vienen
dados por valores enteros positivos.
- Los parámetros 𝑟1 y 𝑠0 no pueden ser nulos.
A continuación se definen las variables adicionales que van a ser empleadas en el
cálculo de las estimaciones puntuales e intervalo score modificado para la Sensibilidad
y la Especificidad, como son:
𝑧1−𝛼/2, 𝑛 = 𝑠1 + 𝑠0 + 𝑟1 + 𝑟0, 𝑠𝑠 = 𝑠1 + 𝑠0, 𝑟𝑟 = 𝑟1 + 𝑟0,
𝑝 = 𝑝𝑟𝑒𝑣𝑎𝑙𝑒𝑛𝑐𝑖𝑎.
Finalmente, la función aquí definida devuelve las estimaciones puntuales y el
intervalo score modificado para Se y Sp, apoyándose en las expresiones planteadas en el
epígrafe anterior.
2.5. Ejemplo.
Sobre una muestra de 300 individuos (Yee et al., 2001) se ha evaluado el
rendimiento de la colonografía tomográfica computada, dado por la variable T, en el
diagnóstico de la neoplasia colorectal (variable D). En la siguiente tabla se exponen los
resultados.
Tabla 3: frecuencias del Ejemplo 1
Resultado de colonografía tomográfica computada
T=1 T=0 TOTAL
Resultados colonoscopia
D=1 164 18 182
D=0 33 85 118
TOTAL 197 103 300
Page 16
Evaluación y comparación de Test Diagnósticos Binarios
15
Para ejecutar el programa definido en el apartado anterior, en primer lugar se
identifican los inputs de la función eetdb:
s1 =164 s0 = 18
r1 = 33 r0 = 85
Definimos tales parámetros en R:
> s1<-164
> s0 <- 18
> r1 <- 33
> r0 <- 85
Y por último utilizamos la función con estos inputs:
> eetdb (s1,s0,r1,r0, alpha =0.95)
Cuyo resultado es el siguiente:
SENSIBILIDAD Y ESPECIFICIDAD
La estimación de la sensibilidad es 90.10989 % y su error estándar es 0.02212846
El intervalo de confianza score modificado al 95 % de confianza para la sensibilidad
es: (0.849695; 0.9371227 )
El intervalo de confianza de Agresti y Coull al 95 % de confianza para la
sensibilidad es: (0.8479539; 0.9369924 )
La estimación de la especificidad es 72.0339 % y su error estándar es 0.04131839
El intervalo de confianza score modificado al 95 % de confianza para la
especificidad es: (0.6338977; 0.7938935 )
El intervalo de confianza de Agresti y Coull al 95 % de confianza para la
especificidad es: (0.6328542; 0.7933753 )
Page 17
Evaluación y comparación de Test Diagnósticos Binarios
16
Un test diagnóstico con sensibilidad alta pero baja especificidad conlleva la
responsabilidad de informar erróneamente a pacientes enfermos, por lo cual, este tipo de
test diagnósticos precisan de una segunda prueba que confirme el verdadero estado del
paciente o bien que corrija el error. La situación ideal sería un test diagnóstico con el
100% de acierto, pero la falta de realidad de este tipo de resultado nos lleva a aplicar un
segundo test diagnóstico cuyas características sean opuestas al primero, es decir, baja
sensibilidad y alta especificidad. De esta forma, se consigue corregir los falsos positivos
e informar de manera fiable al individuo.
A la vista de los resultados del estudio presentado, los parámetros toman valores
elevados, superando el 70% tanto la sensibilidad como la especificidad. Este hecho
informa sobre la validez de la Colonografía por Tomografía Computarizada
(Colonoscopia Virtual) como test diagnóstico para el diagnóstico de la neoplasia
colorectal.
Page 18
Evaluación y comparación de Test Diagnósticos Binarios
17
3. Comparación de dos Test Diagnósticos Binarios.
3.1. Introducción.
Una vez expuesta la evaluación de los resultados para un test diagnóstico binario,
procedemos a la comparación de la exactitud de 2 o más test diagnósticos binarios
diferentes. Este es un paso muy importante en el diagnóstico de un individuo y la
evaluación de nuevas pruebas diagnósticas. Esta comparación se lleva a cabo de forma
que se aplican dos test diagnósticos binarios y un gold estándar a una muestra de
individuos de la población bajo estudio.
Para este proceso se tendrá en cuenta si el diseño del estudio es apareado o de caso-
control. Además, continuamos con el análisis mediante los parámetros de Sensibilidad y
Especificidad.
En la línea del presente trabajo, consideraremos que todos los individuos han sido
verificados por gold estándar, es decir, nos encontramos en una situación de verificación
completa, lo cual nos permite definir la sensibilidad y especificidad de cada uno de los
test aplicados como una proporción binomial. Por tanto, la comparación se reduce a
aplicar un test de hipótesis para comparar dos proporciones binomiales.
3.2. Comparación bajo un diseño apareado.
Un diseño es apareado cuando se aplican todos los test diagnósticos binarios bajo
estudio, además del gold estándar, a cada uno de los individuos de la muestra de tamaño
n.
Con esto, obtenemos una tabla 2x4, organizada como sigue:
Tabla 4: frecuencias absolutas para comparar 2 TDB bajo un diseño apareado
T1=1 T1=0
T2=1 T2=0 T2=1 T2=0 Total
Resultado Gold
Standard
D=1 𝑠11 𝑠10 𝑠01 𝑠00 s
D=0 𝑟11 𝑟10 𝑟01 𝑟00 r
TOTAL 𝑛11 𝑛10 𝑛01 𝑛00 n
Page 19
Evaluación y comparación de Test Diagnósticos Binarios
18
Las frecuencias que se resumen en esta tabla, siguen una distribución multinomial.
Las probabilidades teóricas que resultan al aplicar dos test binarios a una muestra se
presentan en la siguiente tabla:
Tabla 5: probabilidades al aplicar 2 TDB a una muestra apareada
T1=1 T1=0
T2=1 T2=0 T2=1 T2=0 Total
Resultado Gold
Standard
D=1 𝑝11 𝑝10 𝑝01 𝑝00 p
D=0 𝑞11 𝑞10 𝑞01 𝑞00 q
TOTAL 𝑝11 + 𝑞11 𝑝10 + 𝑞10 𝑝01 + 𝑞01 𝑝00 + 𝑞00 1
A partir de esta tabla se puede hallar los valores de para la sensibilidad y
especificidad del test 1, denotado por su subíndice, y para el test 2 mediante las
siguientes expresiones:
𝑆𝑒1 =𝑝11 + 𝑝10
𝑝; 𝑆𝑝1 =
𝑞11 + 𝑞10
𝑞;
𝑆𝑒2 =𝑝11 + 𝑝01
𝑝; 𝑆𝑝2 =
𝑞00 + 𝑞01
𝑞.
Para contrastar la igualdad de las sensibilidades de ambos test, se considera la
equivalencia entre test de hipótesis:
{𝐻0: 𝑆𝑒1 = 𝑆𝑒2
𝐻1: 𝑆𝑒1 ≠ 𝑆𝑒2↔ {
𝐻0: 𝑝11 + 𝑝10 = 𝑝11 + 𝑝01
𝐻1: 𝑝11 + 𝑝10 ≠ 𝑝11 + 𝑝01↔ {
𝐻0: 𝑝10 = 𝑝01
𝐻1: 𝑝10 ≠ 𝑝01
Por tanto, si se condiciona en los pares discordantes, se tiene
Page 20
Evaluación y comparación de Test Diagnósticos Binarios
19
𝑝10 = 𝑝01 → 𝑝10 = 𝑝01 = 0.5.
Lo cual nos lleva a una última equivalencia para realizar el contraste del test
hipótesis de igualdad de sensibilidades, que no es más que un test de hipótesis para una
proporción binomial:
{𝐻0: 𝑝10 = 0.5𝐻1: 𝑝10 ≠ 0.5
Retomando la tabla de frecuencias, se deduce que bajo la hipótesis nula se verifica
𝑠10~𝐵𝑖(𝑠10 + 𝑠01, 0.5). Es más, si 𝑠10+𝑠01
2> 5, entonces 𝑠10~𝑁(
𝑠10+𝑠01
2, √
𝑠10+𝑠01
4).
Así, si 𝑠10 + 𝑠01 > 10, el estadístico para el contraste es:
𝑧𝑒𝑥𝑝 =|𝑠10 − 𝑠01| − 1
√𝑠10 + 𝑠01
~𝑁(0,1).
Este test de hipótesis se denomina Test de McNemar.
Análogamente, para contrastar la igualdad de las especificidades de los 2 test bajo
estudio, se realiza el test:
{𝐻0: 𝑆𝑝1 = 𝑆𝑝2
𝐻1: 𝑆𝑝1 ≠ 𝑆𝑝2↔ {
𝐻0: 𝑞10 = 0.5𝐻1: 𝑞10 ≠ 0.5
Aplicando el test de McNemar, si 𝑟10 + 𝑟01 > 10, el estadístico de contraste viene
dado por la expresión:
Page 21
Evaluación y comparación de Test Diagnósticos Binarios
20
𝑧𝑒𝑥𝑝 =|𝑟10 − 𝑟01| − 1
√𝑟10 + 𝑟01
~𝑁(0,1).
En este tipo de muestreo, el intervalo de confianza Wald+2 se distingue por tener un
mejor comportamiento asintótico que el resto. Este intervalo de confianza para la
diferencia viene dado por la expresión:
𝑆𝑒1 − 𝑆𝑒2 ∈𝑠10 + 𝑠01
𝑠 + 2± 𝑧
1−𝛼2
√(𝑠10 + 𝑠01 + 1) −(𝑠10 − 𝑠01)2
𝑠 + 2
𝑠 + 2;
𝑆𝑝1 − 𝑆𝑝2 ∈𝑟10 + 𝑟01
𝑟 + 2± 𝑧
1−𝛼2
√(𝑟10 + 𝑟01 + 1) −(𝑟10 − 𝑟01)2
𝑟 + 2
𝑟 + 2.
- Test exacto de Fisher
En el test exacto de Fisher se define la hipótesis nula como independencia en valor
de la proporción que toman 2 variables. Este test se basa en la distribución
hipergeométrica. Dado una muestra de tamaño n, la tabla se organiza de forma que:
𝑎1 = min {𝑠10, 𝑠01}, 𝑎2 = max {𝑠10, 𝑠01} , 𝑏1 = min {𝑟10, 𝑟01} y 𝑏2 = max{𝑟10, 𝑟01}.
Consideremos, a partir de la Tabla 4, las siguientes expresiones para la sensibilidad
y especificidad de los dos test diagnósticos en términos de proporciones:
Page 22
Evaluación y comparación de Test Diagnósticos Binarios
21
𝑆𝑒1 =𝑠11 + 𝑠10
𝑠; 𝑆𝑝1 =
𝑟11 + 𝑟10
𝑟;
𝑆𝑒2 =𝑠11 + 𝑠01
𝑠; 𝑆𝑝2 =
𝑟00 + 𝑟01
𝑟.
Para contrastar la igualdad de las sensibilidades de ambos test, hemos visto que,
apoyándonos en los resultados discordantes, existe equivalencia entre los test de
hipótesis:
{𝐻0: 𝑆𝑒1 = 𝑆𝑒2
𝐻1: 𝑆𝑒1 ≠ 𝑆𝑒2↔ {
𝐻0: 𝑝10 = 𝑝01
𝐻1: 𝑝10 ≠ 𝑝01→ {
𝐻0: 𝑝10 − 𝑝01 = 0𝐻1: 𝑝10 − 𝑝01 ≠ 0
Análogamente para la especificidad se tiene la equivalencia:
{𝐻0: 𝑆𝑝1 = 𝑆𝑝2
𝐻1: 𝑆𝑝1 ≠ 𝑆𝑝2↔ {
𝐻0: 𝑞10 − 𝑞01 = 0𝐻1: 𝑞10 − 𝑞01 ≠ 0
Recordemos que el test de Fisher nos informa del p-valor, el cual es obtenido
sumando todas las probabilidades obtenidas de cada una de las tablas construidas
manteniendo fijos los parámetros 𝑎1, 𝑎2, 𝑏1y 𝑏2 y combinando los otros elementos de la
tabla. La probabilidad asociada a cada una de esas tablas obtenidas, se calcula mediante
la siguiente fórmula:
𝑝 =𝑎1! 𝑎2! 𝑏1! 𝑏2!
𝑠10! 𝑠01! 𝑠10! 𝑠01! 𝑛!.
De esta forma, el p-valor para el test exacto se obtiene como la suma de todas las
probabilidades menores o iguales que la probabilidad asociada a la tabla del problema.
Page 23
Evaluación y comparación de Test Diagnósticos Binarios
22
3.3. Comparación bajo un diseño caso-control.
Bajo un muestreo caso-control, se toman dos muestras, una de tamaño 𝑛1 sobre los
individuos que padecen la enfermedad bajo estudio y otra de tamaño 𝑛2 de individuos
sanos. Nótese que el estado de los individuos se conoce gracias a la aplicación de un
gold estándar. A ambas muestras se les aplica ambos test diagnósticos binarios, para
determinar su grado de exactitud.
De esta forma, se define D como una variable aleatoria de estado que toma los
valores:
𝐷 = {1 𝑠𝑖 𝑒𝑙 𝑖𝑛𝑑𝑖𝑣𝑖𝑑𝑢𝑜 𝑝𝑎𝑑𝑒𝑐𝑒 𝑙𝑎 𝑒𝑛𝑓𝑒𝑟𝑚𝑒𝑑𝑎𝑑
0 𝑠𝑖 𝑒𝑙 𝑖𝑛𝑑𝑖𝑣𝑖𝑑𝑢𝑜 𝑛𝑜 𝑝𝑎𝑑𝑒𝑐𝑒 𝑙𝑎 𝑒𝑛𝑓𝑒𝑟𝑚𝑒𝑑𝑎𝑑
Para cada uno de los test cuya exactitud se quiere conocer, se define una variable
binaria que determina el resultado binario del test en cuestión. Se define la variable
aleatoria T1 como aquella que recoge los resultados del primer test diagnóstico:
𝑇1 = {1 𝑠𝑖 𝑒𝑙 𝑡𝑒𝑠𝑡 𝑑𝑖𝑎𝑔𝑛ó𝑠𝑡𝑖𝑐𝑜 𝑏𝑖𝑛𝑎𝑟𝑖𝑜 𝑑𝑎 𝑝𝑜𝑠𝑖𝑡𝑖𝑣𝑜0 𝑠𝑖 𝑒𝑙 𝑡𝑒𝑠𝑡 𝑑𝑖𝑎𝑔𝑛ó𝑠𝑡𝑖𝑐𝑜 𝑏𝑖𝑛𝑎𝑟𝑖𝑜 𝑒𝑠 𝑛𝑒𝑔𝑎𝑡𝑖𝑣𝑜
Y, análogamente, T2 como aquella que recoge los resultados del otro test diagnóstico
bajo estudio:
𝑇2 = {1 𝑠𝑖 𝑒𝑙 𝑡𝑒𝑠𝑡 𝑑𝑖𝑎𝑔𝑛ó𝑠𝑡𝑖𝑐𝑜 𝑏𝑖𝑛𝑎𝑟𝑖𝑜 𝑑𝑎 𝑝𝑜𝑠𝑖𝑡𝑖𝑣𝑜0 𝑠𝑖 𝑒𝑙 𝑡𝑒𝑠𝑡 𝑑𝑖𝑎𝑔𝑛ó𝑠𝑡𝑖𝑐𝑜 𝑏𝑖𝑛𝑎𝑟𝑖𝑜 𝑒𝑠 𝑛𝑒𝑔𝑎𝑡𝑖𝑣𝑜
T1=1 T1=0
T2=1 T2=0 T2=1 T2=0 Total
Resultado
Gold
Standard
D=1 𝑠11 𝑠10 𝑠01 𝑠00 𝒏𝟏
D=0 𝑟11 𝑟10 𝑟01 𝑟00 𝒏𝟐
TOTAL 𝑠11 + 𝑟11 𝑠10 + 𝑟10 𝑠01 + 𝑟01 𝑠00 + 𝑟00
Page 24
Evaluación y comparación de Test Diagnósticos Binarios
23
En este caso, como ocurría en el muestreo apareado, si condicionamos las
frecuencias de la tabla a los estados verdaderos de los individuos, se deduce que las
frecuencias 𝑠11 + 𝑠01 y 𝑟10 + 𝑟00 siguen una distribución binomial:
𝑠11 + 𝑠01~𝐵(n1, 𝑆𝑒) y 𝑟10 + 𝑟00~𝐵𝑖(n2, 𝑆𝑝).
Esto nos permite definir estimadores puntuales como en el epígrafe anterior para los
parámetros de la sensibilidad y especificidad, sin más que sustituir r por n2 y s por n1.
Las frecuencias que se resumen en esta tabla, siguen una distribución multinomial.
Las probabilidades teóricas que resultan al aplicar dos test binarios a una muestra se
pueden resumir como sigue:
𝑝𝑖𝑗 =𝑠𝑖𝑗
𝑛1 + 𝑛2,
𝑞𝑖𝑗 =𝑟𝑖𝑗
𝑛1 + 𝑛2.
A partir de estas proporciones se puede hallar los valores de para la sensibilidad y
especificidad del test 1, denotado por su subíndice, y para el test 2 mediante las
siguientes expresiones:
𝑆𝑒1 =𝑝11 + 𝑝10
𝑛1
𝑛1 + 𝑛2
; 𝑆𝑝1 =𝑞11 + 𝑞10
𝑛2
𝑛1 + 𝑛2
;
𝑆𝑒2 =𝑝11 + 𝑝01
𝑛1
𝑛1 + 𝑛2
; 𝑆𝑝2 =𝑞00 + 𝑞01
𝑛2
𝑛1 + 𝑛2
.
Page 25
Evaluación y comparación de Test Diagnósticos Binarios
24
O bien,
𝑆𝑒1 =𝑠11 + 𝑠10
𝑛1; 𝑆𝑝1 =
𝑟11 + 𝑟10
𝑛2;
𝑆𝑒2 =𝑠11 + 𝑠01
𝑛1; 𝑆𝑝2 =
𝑟00 + 𝑟01
𝑛2.
Para contrastar la igualdad de las sensibilidades de ambos test, se consideran las
equivalencias:
{𝐻0: 𝑆𝑒1 = 𝑆𝑒2
𝐻1: 𝑆𝑒1 ≠ 𝑆𝑒2↔ {
𝐻0: 𝑝11 + 𝑝10 = 𝑝11 + 𝑝01
𝐻1: 𝑝11 + 𝑝10 ≠ 𝑝11 + 𝑝01↔ {
𝐻0: 𝑝10 = 𝑝01
𝐻1: 𝑝10 ≠ 𝑝01
De esta forma, condicionando en los pares discordantes, se tiene
𝑝10 = 𝑝01 → 𝑝10 = 𝑝01 = 0.5.
Lo cual nos lleva a una última equivalencia para realizar el contraste del test
hipótesis de igualdad de sensibilidades, que no es más que un test de hipótesis para una
proporción binomial:
{𝐻0: 𝑝10 = 0.5𝐻1: 𝑝10 ≠ 0.5
Volviendo a la tabla de frecuencias, bajo la hipótesis nula se verifica
𝑠10~𝐵𝑖(𝑠10 + 𝑠01, 0.5).
Page 26
Evaluación y comparación de Test Diagnósticos Binarios
25
Es más, si 𝑠10+𝑠01
2> 5, entonces 𝑠10~𝑁(
𝑠10+𝑠01
2, √
𝑠10+𝑠01
4).
Por tanto, si 𝑠10 + 𝑠01 > 10, se tiene que el estadístico para el contraste viene dado
por:
𝑧𝑒𝑥𝑝 =|𝑠10 − 𝑠01| − 1
√𝑠10 + 𝑠01
~𝑁(0,1).
Análogamente, para contrastar la igualdad de las especificidades de los 2 test bajo
estudio, se realiza el test:
{𝐻0: 𝑆𝑝1 = 𝑆𝑝2
𝐻1: 𝑆𝑝1 ≠ 𝑆𝑝2↔ {
𝐻0: 𝑞10 = 0.5𝐻1: 𝑞10 ≠ 0.5
Siguiendo la línea utilizada para deducir el estadístico de contraste para la
sensibilidad se tiene que si 𝑟10 + 𝑟01 > 10, entonces el estadístico de contraste viene
dado por:
𝑧𝑒𝑥𝑝 =|𝑟10 − 𝑟01| − 1
√𝑟10 + 𝑟01
~𝑁(0,1).
El intervalo de confianza Wald+2 para la diferencia viene dado por la expresión:
𝑆𝑒1 − 𝑆𝑒2 ∈𝑠10 + 𝑠01
𝑛1 + 2± 𝑧
1−𝛼2
√(𝑠10 + 𝑠01 + 1) −(𝑠10 − 𝑠01)2
𝑛1 + 2
𝑛1 + 2.
Page 27
Evaluación y comparación de Test Diagnósticos Binarios
26
𝑆𝑝1 − 𝑆𝑝2 ∈𝑟10 + 𝑟01
𝑛2 + 2± 𝑧
1−𝛼2
√(𝑟10 + 𝑟01 + 1) −(𝑟10 − 𝑟01)2
𝑛2 + 2
𝑛2 + 2.
3.4. Programa en R
Creamos una función en R que recoge las estimaciones de los parámetros de
sensibilidad y especificidad de un test diagnóstico binario. A esta función la denotamos
‘ctdb’ (Comparación de la exactitud de dos Test Diagnósticos Binarios). Se consideran
como inputs aquellas frecuencias que hemos recogido en la tabla: 𝑠11, 𝑠10, 𝑠01,
𝑠00, 𝑟11, 𝑟10, 𝑟01, 𝑟00, 𝑎𝑙𝑝ℎ𝑎.
En primer lugar, se comprueba que los datos son correctos dado que:
- El nivel de confianza considerado debe tomar un valor entre 0 y 1.
- Los parámetros no pueden tomar valores negativos.
- Los parámetros representan frecuencias absolutas, por lo que vienen
dados por valores enteros positivos.
- Las sumas s11 + s10 + s01 + s00 o r11 + r10 + r01 + r00 no pueden ser
nulas.
A continuación se definen las variables adicionales que van a ser empleadas en el
cálculo de las estimaciones puntuales e intervalo score modificado para la Sensibilidad
y la Especificidad, como son:
El nivel de confianza, 1-alpha, para conocer el valor de z1−α/2 y ss = s11 +
s10 + s01 + s00, rr = r11 + r10 + r01 + r00 . Además se reorganiza la taba
de forma que a1=min(s10, s01), a2 = max(s10, s01), b1 = min(r10, r01) y b2 =
max(r10, r01)
Finalmente, la función aquí definida devuelve las estimaciones puntuales para Se y
Sp de los dos test diagnósticos binarios bajo estudio, apoyándose en las expresiones
planteadas en el epígrafe anterior. Además, para llevar a cabo la comparación entre las
sensibilidades y especificidades de los test diagnósticos, se define el test exacto de
Page 28
Evaluación y comparación de Test Diagnósticos Binarios
27
Fisher y el test de McNemar como se han expuesto anteriormente, al igual que se
calcula el intervalo de confianza Wald+2 para cada uno de los parámetros en cuestión.
3.5. Ejemplo.
Se ha estudiado el diagnóstico de la enfermedad coronario en 1465 individuos
(Weiner et al., (1979)) aplicando dos tests y un gold estándar. Para ello, se consideran
como tests diagnósticos el test de ejercicio, cuyos resultados se muestran bajo la
variable binaria T1, y la historia clínica, denotada por la variable binaria T2. Además, se
considera como gold estándar la angiografía coronaria, cuyos resultados los recoge la
variable D. En la siguiente tabla se exponen los resultados.
T1=1 T1=0
T2=1 T2=0 T2=1 T2=0 Total
Resultado Gold
Standard
D=1 786 29 183 25 1023
D=0 69 46 176 151 442
TOTAL 855 75 359 176 1465
Para ejecutar el programa definido en el apartado anterior, en primer lugar se
identifican los inputs de la función ctdb:
s11=786 s10=29 s01=183 s00=25
r11=69 r10=46 r01=176 r00=151
Definimos tales parámetros en R:
> s11<-786;
> s10<-29;
> s01<-183;
> s00<-25;
> r11<-69;
> r10<-46;
Page 29
Evaluación y comparación de Test Diagnósticos Binarios
28
> r01<-176;
> r00<-151;
Y por último utilizamos la función con estos inputs:
> ctdb(s11, s10, s01, s00, r11, r10, r01, r00, alpha = 0.05)
Cuyo resultado es el siguiente:
COMPARACIÓN DE LAS SENSIBILIDADES
La sensibilidad estimada del Test 1 es 79.66764 % y su error estándar es 0.01258337
La sensibilidad estimada del Test 2 es 94.7214 % y su error estándar es 0.006991097
Test Exacto de Fisher: El p-valor del test exacto de Fisher a dos colas es 0
Test de McNemar: El valor del estadístico de contraste es 10.50808 y el p-valor a
dos colas es 0
El intervalo de confianza Wald + 2 para la diferencia Se2 - Se1 al 95 % de
confianza es: (0.1238961 ; 0.1765917)
COMPARACIÓN DE LAS ESPECIFICIDADES
La especificidad estimada del Test 1 es 73.9819 % y su error estándar es 0.02086841
La especificidad estimada del Test 2 es 44.57014 % y su error estándar es
0.02364192
Test Exacto de Fisher: El P-valor a dos colas del test exacto de Fisher es 0
Test de McNemar: El valor del estadístico de contraste del test de McNemar es
8.657913 y el P-valor a dos colas es 0
El intervalo de confianza Wald + 2 para la diferencia Sp1 - Sp2 al 95 % de
confianza es: (0.2327616 ; 0.352824 )
Ya hemos visto en el ejemplo anterior que la situación ideal es encontrar un test
diagnóstico con valores altos de especificidad y sensibilidad. En este caso, al comparar
dos test diagnósticos, será preferible aquel que tenga una mayor sensibilidad y
Page 30
Evaluación y comparación de Test Diagnósticos Binarios
29
especificidad. En este caso, nos enfrentamos a 2 test contrapuestos. El primero presenta
sensibilidad y especificidad superiores al 70% mientras el segundo test diagnóstico se
caracteriza por una alta sensibilidad (94, 72%) que se contrapone a una baja
especificidad (44.57%). Al comparar los valores de ambos parámetros entre sí, resulta
que en el caso de la sensibilidad, el test 2 supera al test 1, sin embargo ocurre lo
contrario con los valores alcanzados en cuanto a la especificidad. Por otra parte,
observando los valores que toman ambos parámetros en cada uno de los test
diagnósticos estudiados, nos lleva a tomar el test de ejercicio (T1) como prueba
diagnóstica más fiable que la historia clínica (T2), pues mantiene elevados sus valores
de especificad y sensibilidad.
El p-valor obtenido mediante el test exacto de Fisher en la comparación de la
sensibilidad, (p-valor = 0<0.05) indica que la especificidad del diagnóstico difiere de
forma significativa entre los test diagnósticos: el test de ejercicio y la historia clínica. Lo
mismo ocurre al comparar la especificidad, por lo que se podría concluir que los test
aportan resultados significativamente distintos.
Page 31
Evaluación y comparación de Test Diagnósticos Binarios
30
4. Conclusiones
A lo largo del presente trabajo, se ha presentado una revisión de las técnicas
empleadas para el análisis de test diagnósticos binarios.
En primer lugar se han presentado los distintos parámetros que se utilizan
habitualmente para evaluar la calidad de un test diagnóstico binario. El potencial de un
test se puede cuantificar con distintas medidas como: la sensibilidad y especificidad, los
valores predictivos (VP), razones de verosimilitud (LR), el área bajo la curva ROC
(AUC), el Índice de Youden y odds-ratio (OR). En particular, para el desarrollo del
trabajo, nos hemos basado en la sensibilidad (Se) y la especificidad (Sp).
Para estos dos parámetros, se han expuesto contrastes que permiten evaluar la calidad
de un test diagnóstico binario en base a los valores de la sensibilidad y la especificidad,
en un muestreo transversal y en el caso de un muestreo del tipo caso-control mediante
un intervalo de confianza denominado intervalo score modificado.
Por otra parte, para comparar 2 test diagnósticos binarios, se tendrá en cuenta si el
diseño del estudio es apareado o de caso-control. Para ello, se expone el test de
McNemar, Wald+2 y el test exacto de Fisher para estudios apareados; mientras que para
el diseño de caso-control sólo se presenta el intervalo Wald+2.
En todo caso, se supone que todos los individuos han sido verificados por un test
gold estándar. Además, se han programado en R los distintos intervalos presentados en
cada caso. Estos programas han sido ejecutados para evaluar unos ejemplos a modo de
prueba.
Page 32
Evaluación y comparación de Test Diagnósticos Binarios
31
5. Bibliografía
Agresti, A. (2002). Categorical Data Analysis. Nueva York: John Wiley and Sons.
Kassirer JP. (1989). Our stubborn quest for diagnostic certainty. A cause of excessive
testing. N Engl J Med, 320:1489-91.
Kraemer, HC. (1992). Evaluating Medical Tests. Newburry Park :SAGE Publications.
Martín Andrés, A. y Luna del Castillo, J. de D. (2004). Bioestadística para las Ciencias
de la Salud. Madrid: Capitel.
McNeil, B.J., Hessel, S.J., Branch, W.T., Bjork, L, Adelstein, S.J. (1976). Measures of
clinical efficacy. III. The value of the lung scan in the evaluation of young
patients with pleuritic chest pain. Journal of Nuclear Medicine: Official
Publication, Society of Nuclear Medicine, 17(3): 163-169.
Mehta CR; NR Patel (1980). A network algorithm for the exact treatment of the 2x K
contingency table. Commun Statist, 9: 649-664.
Mehta CR; NR Patel (1986a). FEXACT: a Fortran subroutine for Fisher’s exact test on
unordered rxc contingency tables. ACM Trans Math Software, 12: 154-161.
Mehta CR; NR Patel (1986b). A hybrid algorithm for Fisher’s exact test in unordered
rxc contingency tables. Commun Statist, 15: 387-403.
Pepe, M.S. (2003). The Statistical Evaluation of Medical Tests of Classification and
Prediction. Oxford: Oxford University Press.
Sox, H.C. Jr., Koran, L.M, Sox, C.H., et al. (1989). A medical algorithm for detecting
physical disease in psychiatric patients. Journal of Hospital and Community
Psychiatry, 40:1270-1276.
Weiner DA, Ryan TJ, McCabe, CH, Kennedy JW, Schloss, M, Tristani F, Chaitman
BR, Fisher LD (1979).Exercise stress testing. Correlations among history of
angina, ST-segmant response and prevalence of coronary-artery disease in the
Page 33
Evaluación y comparación de Test Diagnósticos Binarios
32
coronary artery surgery study (CASS). The New England Journal of Medicine
301:230-235.
Yee J, Akerkar GA, Hung RK, Steinauer-Gebauer AM, Wall SD, McQuaid KR (2001).
Colerectal neoplasia: performance characteristics of CT colonography for
detection in 300 patients. Radiology 219: 685-692.
Yu,W., Gou, X., Xu, W.,(2014). An improved score interval with a modified midpoint
for a binomial proportion. Journal of Statistical Computation and Simulation,
84: 1022-1038.
Zhou XH., Obuchowski, N.A., McClish, D.K., (2002). Statistical Methods in
Diagnostic Medicine. New York: John Wiley and Sons.
Page 34
Evaluación y comparación de Test Diagnósticos Binarios
33
Page 35
Evaluación y comparación de Test Diagnósticos Binarios
34
Anexo I
Definición de la función para la evaluación de un test diagnóstico binario:
eetdb <- function (s1, s0, r1, r0, conf = 0.95)
{
if (conf >= 1 | conf <= 0)
{
stop("El nivel de confianza debe estar entre 0 y 1. Introduce un nuevo
valor \n")
}
if (s1 < 0 | s0 < 0 | r1 < 0 | r0 < 0)
{
stop("Las frecuencias observadas no pueden ser valores negativos.
Introduce nuevos valores \n")
}
if (abs(s1 - trunc (s1)) > 0 | abs(s0 - trunc (s0)) > 0 | abs(r1 - trunc (r1)) > 0
| abs(r0 - trunc (r0)) > 0)
{
stop("Las frecuencias observadas tienen que ser valores enteros
positivos. Introduce nuevos valores \n")
}
if (s0 == 0 && r1 == 0)
{
stop("Las frecuencias s0 y r1 no pueden ser 0. Introduce nuevos valores
\n")
}
Page 36
Evaluación y comparación de Test Diagnósticos Binarios
35
z = qnorm (1 - (1-conf) / 2, 0, 1)
n <- s1 + s0 + r1 + r0
ss <- s1 + s0
rr <- r1 + r0
#Estimación de los parámetros
Se <- s1 / ss
Sp <- r0 / rr
Y <- Se + Sp - 1
if (Y <= 0)
{
stop("La estimación del índice de Youden tiene que ser mayor que 0.
Introduce nuevos valores \n")
}
p <- ss / n
#Intervalo score modificado para la sensibilidad
LSe <- 0.5 + ((ss + z^4 / 53) * (Se - 0.5)) / (ss + z^2) - (z / (ss + z^2)) * sqrt(ss
* Se * (1 - Se) + z^2 / 4)
USe <- 0.5 + ((ss + z^4 / 53) * (Se - 0.5)) / (ss + z^2) + (z / (ss + z^2)) *
sqrt(ss * Se * (1 - Se) + z^2 / 4)
#Intervalo Agresti-Coull
Page 37
Evaluación y comparación de Test Diagnósticos Binarios
36
LSeAC <- ((s1 + 2) / (ss + 4)) - (z / (ss + 4)) * sqrt((s1 + 2) * (s0 + 2) / (ss +
4))
USeAC <- ((s1 + 2) / (ss + 4)) + (z / (ss + 4)) * sqrt((s1 + 2) * (s0 + 2) / (ss +
4))
#Intervalo score modificado para la especificidad
LSp <- 0.5 + ((rr + z^4 / 53) * (Sp - 0.5)) / (rr + z^2) - (z / (rr + z^2)) *
sqrt(rr * Sp * (1 - Sp) + z^2 / 4)
USp <- 0.5 + ((rr + z^4 / 53) * (Sp - 0.5)) / (rr + z^2) + (z / (rr + z^2)) *
sqrt(rr * Sp * (1 - Sp) + z^2 / 4)
#Intervalo Agresti-Coull
LSpAC <- ((r0 + 2) / (rr + 4)) - (z / (rr + 4)) * sqrt((r0 + 2) * (r1 + 2) / (rr +
4))
USpAC <- ((r0 + 2) / (rr + 4)) + (z / (rr + 4)) * sqrt((r0 + 2) * (r1 + 2) / (rr +
4))
#Resultados
cat("\n")
cat(" SENSIBILIDAD Y ESPECIFICIDAD \n")
cat("\n")
cat("La estimación de la sensibilidad es ",100 * Se,"% y su error estándar
es ", sqrt(VarSe), "\n")
cat("\n")
cat("El intervalo de confianza score modificado al ",100 * conf,"% de
confianza para la sensibilidad es: (", LSe," ; ", USe,") \n")
cat("\n")
cat("El intervalo de confianza de Agresti y Coull al ",100 * conf,"% de
confianza para la sensibilidad es: (", LSeAC," ; ", USeAC,") \n")
cat("\n")
Page 38
Evaluación y comparación de Test Diagnósticos Binarios
37
cat("La estimación de la especificidad es ",100 * Sp,"% y su error estándar
es ", sqrt(VarSp), "\n")
cat("\n")
cat("El intervalo de confianza score modificado al ",100 * conf,"% de
confianza para la especificidad es: (", LSp," ; ", USp,") \n")
cat("\n")
cat("El intervalo de confianza de Agresti y Coull al ",100 * conf,"% de
confianza para la especificidad es: (", LSpAC," ; ", USpAC,") \n")
cat("\n")
}
Page 39
Evaluación y comparación de Test Diagnósticos Binarios
38
Anexo II
Definimos la función para la comparación de 2 test diagnósticos Binarios:
cetdbda <- function(s11, s10, s01, s00, r11, r10, r01, r00, alpha = 0.05)
{
if (s11 < 0 | s10 < 0 | s01 < 0 | s00 < 0 | r11 < 0 | r10 < 0 | r01 < 0 | r00 < 0)
{
cat("\n")
stop("Ninguna frecuencia puede ser negativa. Introduce nuevos valores
\n")
cat("\n")
}
if (abs(s00 - trunc (s00)) > 0 | abs(s01 - trunc (s01)) > 0 | abs(s10 - trunc
(s10)) > 0 | abs(s11 - trunc (s11)) > 0 | abs(r00 - trunc (r00)) > 0 | abs(r01 -
trunc (r01)) > 0 | abs(r10 - trunc (r10)) > 0 | abs(r11 - trunc (r11)) > 0)
{
cat("\n")
stop("Las frecuencias observadas no pueden tener decimales. Introduce
nuevos valores \n")
cat("\n")
}
if (alpha >= 1 | alpha <= 0)
{
cat("\n")
stop("El error alpha debe ser mayor que 0 y menor que 1. Introduce un
nuevo valor \n")
Page 40
Evaluación y comparación de Test Diagnósticos Binarios
39
cat("\n")
}
if ((s11 + s10 + s01 + s00) == 0 | (r11 + r10 + r01 + r00) == 0)
{
cat("\n")
stop("La exactitud del test diagnóstico no se puede estimar. Hay
demasiadas frecuencias iguales a 0. Introduce nuevos valores \n")
cat("\n")
}
z <- qnorm(1 - alpha / 2, 0, 1)
conf <- 1 - alpha
ss <- s11 + s10 + s01 + s00
rr <- r11 + r10 + r01 + r00
Se1 <- (s11 + s10) / ss
VarSe1 <- Se1 * (1 - Se1) / ss
Se2 <- (s11 + s01) / ss
VarSe2 <- Se2 * (1 - Se2) / ss
Sp1 <- (r01 + r00) / rr
VarSp1 <- Sp1 * (1 - Sp1) / rr
Sp2 <- (r10 + r00) / rr
Page 41
Evaluación y comparación de Test Diagnósticos Binarios
40
VarSp2 <- Sp2 * (1 - Sp2) / rr
Y1 <- Se1 + Sp1 - 1
Y2 <- Se2 + Sp2 - 1
if (Y1 <= 0)
{
cat("\n")
cat("El índice de Youden estimado del Test 1 es ",Y1, "\n")
cat("\n")
}
if (Y2 <= 0)
{
cat("\n")
cat("El índice de Youden estimado del Test 2 es ",Y2, "\n")
cat("\n")
}
if (Y1 <= 0 | Y2 <= 0)
{
cat("\n")
stop("El índice de Youden estimado de un Test Diagnóstico Binario debe
ser mayor que 0. Introduce nuevos valores \n")
cat("\n")
}
a1 <- min(s10, s01)
Page 42
Evaluación y comparación de Test Diagnósticos Binarios
41
a2 <- max(s10, s01)
b1 <- min(r10, r01)
b2 <- max(r10, r01)
#Comparación de las dos sensibilidades
#Test exacto de Fisher
if (s10 - s01 == 0)
{
pvalor1 <- 1
}
else
{
pvalor1 <- sum (dbinom(0:a1, s10 + s01, 0.5)) + 1 – sum (dbinom(0:a2-1,
s10 + s01, 0.5))
}
#Test de McNemar
z1 <- (abs(s10 - s01) - 1) / sqrt(s10 + s01)
pvalor2 <- 2 * (1 - pnorm(z1, 0, 1))
#Intervalo de confianza Wald + 2
LSe <- (s10 - s01) / (ss + 2) - z * sqrt((s10 + s01 +1) - ((s10 - s01)^2 / (ss +
2))) / (ss + 2)
if (LSe < -1) {LSe <- -1}
USe <- (s10 - s01) / (ss + 2) + z * sqrt((s10 + s01 +1) - ((s10 - s01)^2 / (ss +
2))) / (ss + 2)
Page 43
Evaluación y comparación de Test Diagnósticos Binarios
42
if (USe > 1) {USe <- 1}
#Comparación de las dos especificidades
#Test exacto de Fisher
if (r10 - r01 == 0)
{
pvalor3 <- 1
}
else
{
pvalor3 <- sum(dbinom(0:b1, r10 + r01, 0.5)) + 1 - sum(dbinom(0:b2-1,
r10 + r01, 0.5))
}
#Test de McNemar
z2 <- (abs(r01 - r10) - 1) / sqrt(r01 + r10)
pvalor4 <- 2 * (1 - pnorm(z2, 0, 1))
#Intervalo de confianza Wald + 2
LSp <- (r01 - r10) / (rr + 2) - z * sqrt((r01 + r10 +1) - ((r01 - r10)^2 / (rr +
2))) / (rr + 2)
if (LSp < -1) {LSp <- -1}
USp <- (r01 - r10) / (rr + 2) + z * sqrt((r01 + r10 +1) - ((r01 - r10)^2 / (rr +
2))) / (rr + 2)
if (USp > 1) {USp <- 1}
#Resultados
Page 44
Evaluación y comparación de Test Diagnósticos Binarios
43
cat("\n")
cat(" COMPARACIÓN DE LAS SENSIBILIDADES \n")
cat("\n")
cat("La sensibilidad estimada del Test 1 es ",100 * Se1,"% y su error
estándar es", sqrt(VarSe1), "\n")
cat("\n")
cat("La sensibilidad estimada del Test 2 es ",100 * Se2,"% y su error
estándar es", sqrt(VarSe2), "\n")
cat("\n")
cat("Test Exacto de Fisher. El P-valor a dos colas del test exacto de Fisher
es ", pvalor1,"\n")
cat("\n")
if (s10 + s01 > 10)
{
cat("Test de McNemar. El valor del estadístico de contraste del test de
McNemar es ",z1," y el P-valor a dos colas es ", pvalor2,"\n")
}
cat("\n")
if (Se1 >= Se2)
{
cat("El IC Wald + 2 para Se1 - Se2 al ",100 * conf,"% de confianza es:
(", LSe," ; ", USe,") \n")
}
else
{
cat("El IC Wald + 2 para Se2 - Se1 al ",100 * conf,"% de confianza es:
(", -USe," ; ", -LSe,") \n")
}
cat("\n")
cat(" COMPARACIÓN DE LAS ESPECIFICIDADES \n")
cat("\n")
cat("La especificidad estimada del Test 1 es ",100 * Sp1,"% y su error
estándar es", sqrt(VarSp1), "\n")
cat("\n")
Page 45
Evaluación y comparación de Test Diagnósticos Binarios
44
cat("La especificidad estimada del Test 2 es ",100 * Sp2,"% y su error
estándar es", sqrt(VarSp2), "\n")
cat("\n")
cat("Test Exacto de Fisher. El P-valor a dos colas del test exacto de Fisher
es ", pvalor3,"\n")
cat("\n")
if (r10 + r01 > 10)
{
cat("Test de McNemar. El valor del estadístico de contraste del test de
McNemar es ",z2," y el P-valor a dos colas es ", pvalor4,"\n")
}
cat("\n")
if (Sp1 >= Sp2)
{
cat("El IC Wald + 2 para Sp1 - Sp2 al ",100 * conf,"% de confianza es:
(", LSp," ; ", USp,") \n")
}
else
{
cat("El IC Wald + 2 para Sp2 - Sp1 al ",100 * conf,"% de confianza es:
(", -USp," ; ", -LSp,") \n")
}
cat("\n")
}