ANÁLISIS DE EFECTIVIDAD AL IMPLEMENTAR LA TÉCNICA DE ÁRBOLES DE DECISIÓN DEL ENFOQUE DE APRENDIZAJE DE MÁQUINA PARA LA DETERMINACIÓN DE AVALÚOS MASIVOS PARA LAS UPZ 79 CALANDAIMA, 65 ARBORIZADORA Y 73 GARCÉS NAVAS Adriana del Pilar Albancando Robles Universidad Distrital Francisco José de Caldas Facultad de Ingeniería, Ingeniería Catastral y Geodesia Bogotá D.C. 2017
Transcript
ANÁLISIS DE EFECTIVIDAD AL
IMPLEMENTAR LA TÉCNICA DE ÁRBOLES
DE DECISIÓN DEL ENFOQUE DE
APRENDIZAJE DE MÁQUINA PARA LA
DETERMINACIÓN DE AVALÚOS MASIVOS
PARA LAS UPZ 79 CALANDAIMA, 65
ARBORIZADORA Y 73 GARCÉS NAVAS
Adriana del Pilar Albancando Robles
Universidad Distrital Francisco José de Caldas
Facultad de Ingeniería, Ingeniería Catastral y Geodesia
Bogotá D.C.
2017
ANÁLISIS DE EFECTIVIDAD AL
IMPLEMENTAR LA TÉCNICA DE ÁRBOLES
DE DECISIÓN DEL ENFOQUE DE
APRENDIZAJE DE MÁQUINA PARA LA
DETERMINACIÓN DE AVALÚOS MASIVOS
PARA LAS UPZ 79 CALANDAIMA, 65
ARBORIZADORA Y 73 GARCÉS NAVAS
Adriana del Pilar Albancando Robles
Monografía de grado presentado como requisito parcial para optar el título de:
Ingeniera Catastral y Geodesta
Director:
Ingeniero Edwin Robert Pérez Carvajal
Universidad Distrital Francisco José de Caldas
Facultad de Ingeniería, Ingeniería Catastral y Geodesia
Bogotá D.C.
2017
III
Dedicatoria
A mi Padre Celestial, a mi mamá
Adriana Robles Salazar, mi papá Edwin
Albancando Cushcagua, mis hermanas
Diana Margarita, Liz Alejandra, Karol
Daniela y mis hermanos Edwin Hared y
José David, quienes han sido el motor y
apoyo constante en cada logro que he
conseguido, así como a cada familiar y
amigo que ha hecho parte de este
proceso.
Adriana del Pilar Albancando Robles
IV
Agradecimientos
De manera solemne expreso gratitud a todos los que estuvieron involucrados en este
proyecto que ahora llega a su culminación.
A Mi Padre Celestial, a quien debo cada fortaleza, a los miembros de mi familia, mis
padres y hermanos, que fueron participantes activos en este proceso, su ejemplo, apoyo,
dedicación y sacrificio dieron paso a que haya sido posible llevar a cabo este cometido,
reconozco su paciencia y confianza, que me llevaron a perseverar en esta labor cada
momento.
A la Universidad Distrital Francisco José de Caldas por haberme permitido participar de
este proyecto curricular y darme las herramientas mediante sus docentes y programas para
desarrollarme como profesional en Ingeniería Catastral y Geodesia.
De manera especial agradezco a mi director, el Ingeniero Edwin Robert Pérez, quien
estuvo al tanto de cada parte del desarrollo de este trabajo, prestando un dedicado apoyo,
constante atención e instrucción oportuna.
Finalmente agradezco a la Unidad Administrativa Especial de Catastro Distrital (UAECD)
y al Observatorio Técnico Catastral por suministrarme la información correspondiente a
las bases de datos para el desarrollo de este proyecto.
V
Resumen
El presente proyecto tiene como fin desarrollar la aplicación del aprendizaje de máquina,
específicamente el método de árboles de decisión, para verificar su efectividad como parte
fundamental del estudio que constituyen los avalúos masivos y mostrar una comparación
con valores observados y el método tradicionalmente empleado, a saber, la regresión
lineal.
Para cumplir con los objetivos propuestos se emplearon métodos de clasificación para
datos numéricos, el M5P, y para datos nominales, el ID3 y el J48, los cuales se evaluaron
por variaciones de los Test Cross Validation (validación cruzada) y Percentage Split
(División de porcentaje), por medio de los que se verificó el clasificador de árboles de
decisión más acertado al obtener resultados semejantes a los observados.
Con el propósito de verificar la efectividad de la aplicación del aprendizaje de máquina en
procesos como los avalúos, se hizo uso de datos proporcionados por la Unidad
Administrativa Especial de Catastro Distrital (UAECD) y el Observatorio Técnico
Catastral, correspondientes a las Unidades de Planeamiento Zonal (UPZ) 65
Arborizadora, 73 Calandaima y 79 Garcés Navas, adicionalmente, para el tratamiento de
los datos se empleó el software libre Weka con sus aplicaciones y opciones para visualizar,
procesar y observar resultados.
Como resultado del análisis realizado, se obtuvo que el aprendizaje de máquina por medio
del método de árboles de decisión es una herramienta útil y efectiva para aplicar dentro del
proceso de los avalúos, su aplicación a los datos es más específica al compararla con el
método de regresión lineal, la claridad de los resultados permite entender cada regla que se
VI
aplica a los grupos de datos y hacer un análisis más específico de las clasificaciones
finales.
Palabras clave: Aprendizaje de Máquina, Árboles de decisión, Unidad de Planeamiento
Agradecimientos ................................................................................................................................ IV
Lista de figuras .....................................................................................................................................5
Lista de tablas ......................................................................................................................................8
Lista de ecuaciones ........................................................................................................................... 12
Lista de anexos .................................................................................................................................. 13
Anexo 78. Calandaima – NO_PH, Comparación Valor m2 de Construcción Observado,
método Árbol de Decisión – M5P Split 80 y Regresión Lineal – Cross 20...................... 262
18
Introducción
La Inteligencia artificial, según Marvin Minsky, considerado el padre de la inteligencia
artificial (Bernardo, 2016), se define como la ciencia de construir máquinas que hagan
cosas que, si las hicieran los humanos requerirían inteligencia (Cazorla,M, Alfonso, M,
Escolano, F, Colomina, O, & Lozano, M, 2003). De esta ciencia, se derivan diferentes
campos, entre los cuales se encuentra el aprendizaje de máquina, este consiste en un
conjunto de métodos por los cuales las máquinas pueden detectar automáticamente patrones
en los datos, y luego usar los patrones descubiertos para realizar predicciones (Murphy,K,
2012), uno de estos métodos es el de árbol de decisión, que es de los más populares entre
los algoritmos de inferencia inductiva, en el que por reglas de si – entonces, realiza la
clasificación de los datos (Mitchell, T, 1997).
Valuar consiste en la aplicación de los diferentes enfoques y herramientas para la
estimación del valor de un bien, al relacionarlo con los bienes inmuebles se hace necesario
buscar la forma y herramientas que permitan llegar, de manera técnica y precisa, al
conocimiento del valor del bien, ya sea que se trate de uno, o de varios predios, según
corresponda el caso.
En las técnicas que se requieren en la valuación, se emplean diferentes variables que
identifican el inmueble, por lo que al requerir avalúos de un gran volumen de predios, es
necesario realizar una clasificación, esta se puede desarrollar mediante diversos métodos,
entre los que se encuentran la comparación o el mercado, la capitalización de rentas o
ingresos, costo de reposición y la técnica de desarrollo potencial o método involutivo.
Mediante cada uno de estos métodos, se hace un exhaustivo trabajo y se llega finalmente a
19
determinar el valor de un bien inmueble; en caso de tratarse de varios predios, en Colombia
se ha popularizado el uso de modelos de regresión lineal, no obstante, dadas las
características de algunas variables inherentes a los predios es necesario hacer procesos
para poder identificarlas e instrumentalizarlas en la regresión, o simplemente no
emplearlas.
En este trabajo se presenta una herramienta más a partir de la implementación del algoritmo
de árboles de decisión, del enfoque del aprendizaje de máquina, a los procesos valuatorios
de los bienes inmuebles, mostrando otra alternativa para emplear un proceso de esta índole
en la investigación que involucra un avalúo y verificar su efectividad.
20
1. Antecedentes
Diferentes técnicas derivadas del aprendizaje de máquina han sido implementadas con el
fin de facilitar procesos, entre estas técnicas se encuentran las redes neuronales, algoritmos
genéticos, arboles de decisión, entre otros. Recientemente se han desarrollado proyectos
aplicados a campos empresariales, de inversión y, aunque no en gran cantidad, al
componente “geo” de una comunidad.
A continuación se presentan tres trabajos que se han realizado empleando técnicas de
aprendizaje de máquina para cumplir con sus respectivos objetivos.
Figura 1. 1 Procedimiento para construir una base de conocimiento para implementar el método de
aprendizaje Fuente: (Huang,X & Jensen,J.R, 1997)
En primer lugar, en el año de 1997 se realizó un paper titulado A Machine-Learning
Approach to Automated Knowledge-Base Building for Remote Sensing Image Analysis
with GIs Data (Una evaluación de aprendizaje mecanizado de construcción basado en
21
conocimiento automatizado para el análisis de imágenes de sensor remoto con datos SIG)
por Xueqiao Huang y John R. Jensen.
Al realizar este artículo científico, el objetivo de los autores fue presentar la manera en que
se podía aplicar el enfoque de aprendizaje de máquina, para la clasificación de imágenes
obtenidas mediante sensores remotos.
Figura 1. 2 Ejemplo de capas de una imagen para el conjunto de datos de entrenamiento y el flujo de
datos en el subsistema
Fuente: (Huang,X & Jensen,J.R, 1997)
El proceso que se siguió se dividio entre el trabajo realizado por los humanos expertos y el
trabajo realizado por el aprendizaje de máquina o del programa, como se muestra en la
Figura 1.1, en la parte superior del gráfico (a) se puede apreciar que se parte de una base de
un sistema de información geográfica, seguido a eso los humanos expertos realizan los
procedimientos necesarios para las debidas clasificaciones que conformaran el conjunto de
entrenamiento. Luego, en la parte inferior de la gráfica (b), se presenta, lo que se considera
22
el aprendizaje, mediante el software y la máquina se genera el árbol de decisión y las
respectivas reglas, para obtener finalmente una base de conocimiento.
Este proyecto se desarrolló con imágenes obtenidas de sensores remotos con el fin de hacer
un análisis multitemporal de un área de humedales localizada a los alrededores del rio
Savannah localizado en la frontera entre los estados de Carolina del Sur y Georgia en los
Estados Unidos.
Ilustrado en la Figura 1.2, se explica gráficamente como el pixel de una sola imagen tiene
varios componentes, seis para el ejemplo, que serán los valores que conformarán el
conjunto de datos de entrenamiento para la generación del árbol de decisión y las reglas a
aplicar para finalmente tener una clasificación como resultado.
Como conclusiones del trabajo los autores obtuvieron que el uso del aprendizaje de
máquina facilita en gran manera el proceso de clasificación de las imágenes a comparación
del método empleado convencionalmente, al hacer una selección adecuada del conjunto de
datos de entrenamiento se obtienen resultados de calidad y destacan la facilidad de entender
e interpretar los resultados obtenidos mediante los árboles y las reglas para la posterior
aplicación a los datos de validación (Huang,X & Jensen,J.R, 1997).
En segundo lugar, en el año 2008, se publicó para la Revista Colombiana de Estadística, el
artículo titulado Aplicación de árboles de decisión en modelos de riesgo crediticio por
Paola Andrea Cardona Hernández.
Mediante este trabajo, la autora muestra un marco general de la normatividad del sistema
de administración de riesgo crediticio y la importancia del papel de la estadística en estos
23
estudios, específicamente el método de árboles de decisión para el cálculo de
incumplimiento en crédito presentando sus ventajas y desventajas.
Entendiendo por riesgo de crédito la pérdida potencial para una entidad financiera debido a
la incapacidad del cliente de cumplir con sus obligaciones de pago, se hace necesario, de
parte de las entidades financieras realizar estudios que les permitan conocer si sus clientes
son deudores potenciales, para estos se establece un tiempo de doce meses a futuro y se
estudia la capacidad de pago de los mismos, comúnmente se hace con clientes que
anteriormente han estado en mora, no obstante, mediante otros métodos estadísticos es
posible realizarlo para clientes que no han estado en mora y prever en escenarios futuros su
posible comportamiento respecto sus deudas.
Figura 1. 3 Esquema de la definición de las variables Fuente: (Cardona, A, 2004)
Como se muestra en la Figura 1.3, se establecen como clientes buenos aquellos que no han
estado en mora en los primeros doce meses y como clientes malos aquellos que antes de los
doce meses se han encontrado en estado de mora, y es con esas variables que se generará el
24
árbol de decisión y posteriormente las reglas que permitirán aplicar el modelo generado de
datos de entrenamiento a datos de los posibles clientes.
Figura 1. 4 Ejemplo de árbol de decisión para iniciación Fuente: (Cardona, A, 2004)
Como se observa en este ejemplo de la Figura 1.4, al emplear el método de árboles de
decisión, para este caso se obtienen seis nodos terminales, es decir, 6 categorías con sus
respectivas probabilidades que permiten identificar seis perfiles de riesgo para tomar
decisiones respecto a otorgar o no el crédito a las personas en los diferentes escenarios.
Los requerimientos para el uso de modelos están asociados a tres factores:
Simplicidad: A fin de que diferentes empleados de la entidad financiera puedan
entender el modelo y sus resultados.
Potencia: Mostrando en sus resultados la elegibilidad correcta entre clientes
buenos y clientes malos.
Estabilidad: Que con el paso del tiempo el modelo continúe siendo aplicable.
25
Teniendo en cuenta que el modelo de árboles de decisión cumple con estos requerimientos,
la autora presenta la forma en que se aplican pruebas estadísticas para evaluar la capacidad
del modelo como la prueba F, Kolmogorov-Smirnov para dos muestras (K-S), la curva
ROC (Recive Operative Curve) y el coeficiente Gini y como estas dan buenos resultados.
Concluyendo, la autora se refiere a los árboles de decisión como una herramienta efectiva
al evaluar el riesgo de que exista incumplimiento en las responsabilidades de los posibles
clientes, es estable en el tiempo y útil para planeación de estrategias comerciales, métodos
de cobranza, entre otras. Se aclara que la importancia de un buen modelo radica en que
según las decisiones que se tomen al aceptar o no un cliente afectará directamente las
utilidades de la entidad financiera, permitiéndole aumentar en capital o llegar a la
insolvencia (Cardona, A, 2004).
Para finalizar, en tercer lugar, en el año 2011 fue presentada en la facultad de minas de
Ingeniería de sistemas en la Universidad Nacional, sede Medellín, Colombia, la tesis
titulada Modelo Basado en Aprendizaje de Máquinas para el Manejo de Riesgo de Falla
Durante la Composición de Servicios Web por Byron Enrique Portilla Rosero como
requisito para optar al título de magister en ingeniería de sistemas.
El objetivo de este trabajo estuvo en proponer un modelo basado en el método de
aprendizaje de máquina que permitiera “aprender al sistema” los riesgos que puede
presentar en el servicio web a fin de disminuir el riesgo de falla del mismo.
Para lograr esto el autor estudio las siguientes técnicas:
Arboles de decisión
Programación lógica inductiva (ILP)
26
Razonamiento basado en Casos(CBR)
Aprendizaje por refuerzo
Aprendizaje bayesiano
De estas revisó las ventajas y desventajas de cuatro características específicas, a saber:
Manejo de recursos de memoria, almacenamiento y tiempo de ejecución
Información requerida
Representación
Facilidad de interpretar el resultado por el humano
Figura 1. 5 Comportamiento del error (ECM)
Nota: Comportamiento del ECM del cálculo del riesgo en la métrica de disponibilidad por parte del
aprendizaje para el servicio GetItemInformation para el día martes 11am.
Fuente: (Portilla,B.E., 2011)
27
Llegando a la conclusión que las técnicas que describían mejor estas características y se
aplicaban al objetivo de su proyecto, de adquirir información referente a riesgos de falla de
los servicios durante composiciones web, fueron los árboles de decisión y la programación
lógica inductiva, dado que estas dos técnicas se fusionan en el marco de árboles de
decisión lógicos.
Como se muestra en la Figura 1.5, el comportamiento de los servicios es aprendido de
forma satisfactoria por el modelo de aprendizaje, permitiendo hacer una mejor selección de
los servicios y disminución de las fallas.
Al finalizar el proyecto, se obtuvo que el modelo sugerido muestra solides en el
aprendizaje, capacidad para encontrar asociaciones correctas y el incremento de esa
capacidad mientras existan más observaciones (Portilla,B.E., 2011).
28
2. Problema de investigación
Conocer el valor de la posesiones es una necesidad que se ha generado desde tiempos
remotos, dado el hecho de que existiera un exceso de determinado bien, se hizo importante
saber el valor que este representaba para alguien que careciera del mismo (Caballero, M,
2002); en un principio se empleó el trueque, haciendo el intercambio entre objetos que se
consideraban de valor equivalente debido a la necesidad que se tenía de los mismos, con el
paso del tiempo, luego de la invención del papel moneda como medio de intercambio, se
estableció una forma “imparcial” de valorar las cosas, no obstante el problema de saber a
cuantas unidades monetarias era equivalente un bien, continuaba siendo una necesidad por
satisfacer en los diferentes campos, incluyendo el de los bienes inmuebles.
A fin de dar solución a esta y otras necesidades relacionadas con el área de catastro,
geodesia, geomática, socioeconomía y planeación, en Colombia se creó el pregrado de
Ingeniería Catastral y Geodesia, teniendo como propósito el estudio del recurso tierra con
énfasis en el manejo social (UDFJC, 2016), enseñando también la investigación necesaria
que se requiere para conocer el valor monetario de un bien inmueble, la cual incluye, que
además de conocer de métodos matemáticos se conozca del entorno y se sepa argumentar
cada una de las decisiones que se tomen respecto al valor del bien valuado, ya que el
dinamismo que se presenta en las ciudades a nivel económico, social, arquitectónico,
estructural, de vetustez, entre otros, será un factor importante en el mercado de los
inmuebles.
Ahora bien, el analizar un bien y realizar toda una investigación involucrando diferentes
estudios y métodos matemáticos a fin de llegar a una conclusión de su valor en el mercado,
29
es una tarea que involucra gran trabajo y dedicación, no obstante, este trabajo se multiplica
al hablar de realizar avalúos masivos, por lo que se hace necesario emplear métodos que
faciliten la labor y funcionen como una herramienta más en la toma de decisiones.
El método enseñado y practicado para los avalúos masivos, en la universidad Distrital
Francisco José de Caldas, consiste en la realización de modelos econométricos, en cuyas
ecuaciones normalmente se tiene como variable dependiente el valor de metro cuadrado de
la construcción y como variables independientes, los valores correspondientes a área, edad
de la construcción, estrato, localización, entre otras, según la información con la que se
cuente y la relevancia que tengan las variables dentro del modelo que se realice, luego de
aplicar las diferentes pruebas a un modelo original; este método funciona bien y arroja,
según la calidad de los datos y del modelo establecido, errores pequeños en las
predicciones, lo que hace de este método una buena herramienta para conocer el valor tanto
de un predio como de un gran conjunto de estos.
Aun cuando el método de los regresores lineales en los modelos econométricos permite
obtener una precisión aceptable, se requiere un trabajo significativo en el momento de
trabajar con variables cualitativas, casos en los que se hace necesario crear variables
dicótomas para solucionar en parte el uso necesario de estas que representan las
características de los predios.
Teniendo en cuenta la importancia de la participación de este tipo de variables en el
proceso de valuar una bien inmueble, así como el ánimo de obtener mejores resultados, se
implementó el uso de los árboles de decisión, procesos derivados de la Inteligencia
30
Artificial del enfoque de aprendizaje de máquina, mediante los cuales es posible realizar
predicciones referentes a los predios, acertadas y con mínimos errores, permiten trabajar
con las diferentes variables inherentes a los predios incluyendo características como su
localización y el manejo de grandes volúmenes de información para el caso de avalúos
masivos.
31
3. Objetivos
3.1 General
Realizar un análisis de la efectividad de implementar los enfoques de aprendizaje de
máquina, específicamente los árboles de decisión, en la determinación de avalúos masivos
para los predios ubicados en la ciudad de Bogotá, en los sectores de la localidad 8 de
Kennedy, Unidad de Planeamiento Zonal 79 Calandaima; localidad 19 de Ciudad Bolívar,
UPZ 65 Arborizadora y localidad 10 de Engativá, UPZ 73 Garcés Navas.
3.2 Específicos
Implementar la técnica de árboles de decisión y sus diferentes variaciones en el proceso de
realizar los avalúos.
Determinar de las técnicas de árboles de decisión usadas las que por sus parámetros
permitan llegar a resultados más acertados.
Establecer una comparación del método seleccionado de la técnica de árboles de decisión
con el método tradicionalmente empleado, regresión lineal, para la realización de avalúos
masivos, a fin de validar el uso de esta técnica para el avalúo de bienes inmuebles.
32
4. Justificación
Los avalúos masivos son desarrollados por entidades privadas y gubernamentales según
diferentes necesidades como obras viales, proyectos de renovación urbana, estudios de
costos, entre otras y se efectúan mediante técnicas de modelos de regresión, en estos
procesos están involucradas variables numéricas y cualitativas, el uso de estos modelos se
ve afectado especialmente al involucrar variables del segundo tipo, debido a que se deben
buscar maneras de organizar y procesar los datos a fin de que todas las técnicas que se
empleen estén debidamente ejecutadas, al implementar este método se obtienen resultados
que al compararlos con la realidad son buenas representaciones de esta, no obstante, debido
a que se generaliza una regresión para una gran cantidad de datos, no siempre se ajusta de
una manera óptima para todos; al brindar un método que permita resultados aún más
ajustados a la realidad, las ventajas para las entidades que emplearían estos métodos serían
representativas y notorias en reducciones de costos y una visión más acertada referente a
los predios estudiados
Considerando la manera en que la tecnología permite el continuo avance en diferentes
entornos se optó por hacer uso de la inteligencia artificial, que tiene como uno de sus
enfoques el aprendizaje de máquina, que busca que mediante un sistema la máquina
aprenda una tarea y sea capaz de utilizar la información aprendida para generar
clasificaciones que funcionen para el pronóstico de datos ingresados posteriormente al
sistema. Este método ha sido implementado en campos financieros y del tratamiento de
imágenes, obteniendo excelentes respuestas.
33
Teniendo en cuenta que estos métodos han sido empleados para predicciones en distintos
campos, se plantea como un método para usar en el proceso de realizar avalúos masivos
mediante la clasificación automática que puede llegar a generarse, lo cual, según la calidad
de los resultados, es un método más sumándose al convencional.
Debido a que la necesidad de realizar avalúos es permanente en una sociedad que está en
constante cambio, crecimiento y modernización, el hecho de tener más herramientas que
aporten, faciliten y brinden mejores resultados, son necesarias constantemente y gracias al
continuo avance de la tecnología y la implementación de esta en los procesos valuatorios,
los beneficios a corto plazo del proyecto se verifican en los resultados obtenidos en el
presente proyecto, brindando una herramienta efectiva por su proximidad a los valores
reales, a mediano plazo, permitiendo aplicar esta técnica con valores de proyecciones de
entidades como el DANE y a largo plazo al posibilitar el uso de esta herramienta en
conjunto con muchas otras que hagan el proceso inicial de selección y clasificación de
datos más ágil para el posterior procesamiento y análisis de datos.
34
5. Marco espacial
El proyecto se desarrolló con los datos de predios localizados en la Ciudad de Bogotá en las
localidades 19 de Ciudad Bolívar, 8 de Kennedy y 10 de Engativá en las Unidades de
Planeamiento Zonal, 65 Arborizadora, 73 Garcés Navas y 79 Calandaima,
respectivamente, elegidas por la variabilidad que presentan en las características de los
predios allí localizados, presentando una información de más provecho para el estudio. A
continuación se presenta una descripción general de cada una de estas zonas.
5.1. UPZ 65 Arborizadora
La UPZ 65 Arborizadora cuenta con las siguientes características principales:
Localización: La UPZ Arborizadora está localizada al nororiente de la localidad 19,
Simón Bolívar, en la Ciudad de Bogotá, con un área de 326.97 hectáreas (Alcaldía
Mayor de Bogotá D.C - SDP, 2008), comprendidas entre los límites especificados
en la Tabla 5.1.1.
Tabla 5.1. 1Límites UPZ 65 Arborizadora
Norte Avenida del Ferrocarril del sur (DG 57c Sur)
Límite con la localidad 7, Bosa
Sur Avenida Villavicencio (AC 61 Sur)
Límite con la UPZ 66, San Francisco
Oriente
Río Tunjuelo
Límite con la localidad 6, Tunjuelito
Límite con la localidad 8, Kennedy
Occidente
Avenida Villavicencio (AC 61 Sur)
Límite con la UPZ 69, Ismael Perdomo
Límite con la UPZ 70, Jerusalén
Límite con la UPZ 66, San Francisco
35
Extensión: Su extensión total está dividida como se muestra en la Tabla 5.1.2.,
mostrando que la mayor parte de la unidad se encuentra urbanizada y no cuenta con
áreas protegidas.
Tabla 5.1. 2 Extensión UPZ 65 Arborizadora
Área Total 326,97 hectáreas
Área Urbanizada 275,12 hectáreas
Área sin Urbanizar 51,85 hectáreas
Áreas Protegidas 0 hectáreas
Sectores catastrales y centralidades: La UPZ 65 Arborizadora está conformada
por 10 sectores catastrales, Guadalupe, Rafael Escamilla, Madalena, El Ensueño,
Atlanta, La Coruña, Verona, Arborizadora Baja, El Chircal Sur y Ronda,
distribuidos como se presenta en la Figura 5.1.1.
Figura 5.1. 1 División por sectores UPZ 65 Arborizadora
36
La UPZ Arborizadora hace parte de la Centralidad Delicias – Ensueño, del eje de
integración Sur, que permite buenas condiciones para comercializar diversos bienes y
servicios de la región (Secretaría Distrital de Planeación, 2009) promoviendo el
desarrollo de suelo urbano al hacerlo adecuado para actividades productivas y servicios
complementarios a diferentes escalas (Secretaría general de la Alcaldía Mayor de
Bogotá, 2005).
Sistema de Equipamientos: La UPZ cuenta con equipamientos de escala urbana1,
zonal2 y vecinal
3, entre los más destacados están los destinados a educación, salud y
bienestar y en menor cantidad se encuentran los destinados a culto como las iglesias
y templos, a cultura como salones comunales y a la prestación de otros servicios
como el Centro de Atención Distrital Especializado CADE (Alcaldía Mayor de
Bogotá D.C - SDP, 2008).
Vías de acceso: Los ejes de la malla vial arterial para comunicar, acceder y permitir
la movilidad a través de la UPZ están conformados por las vías presentadas en la
Tabla 5.1.3.
Tabla 5.1. 3 Vías malla arterial UPZ 65 Arborizadora
1 Equipamientos de escala urbana, son los que atienden a un área importante de la ciudad
2 Equipamientos de escala zonal, son los que atienden a un conjunto de barrios
3 Equipamientos de escala vecinal, son los que atienden un solo barrio (Alcaldía Mayor de Bogotá D.C - SDP,
2008)
Vía Sentido de Comunicación
Avenida Ferrocarril del sur Oriente - Occidente
Avenida (autopista) Sur Oriente - Occidente
Avenida Ciudad de Villavicencio Norte - Sur
Avenida Jorge Gaitán Cortés Oriente – Occidente
Avenida Mariscal Sucre Oriente – Occidente
37
Usos del suelo: La UPZ 65 Arborizadora está reglamentada por el Decreto 241 de
2005 estableciendo los usos del suelo como se muestra en la Tabla 5.1.4 (Secretaría
general de la Alcaldía Mayor de Bogotá, 2005):
Tabla 5.1. 4 Usos del Suelo UPZ 65 Arborizadora
Uso Barrios
Vivienda La Coruña y Ronda
Vivienda con algunas zonas de comercio Madelena, Isla del Sol, La Coruña y El Chircal Sur
Vivienda con locales comerciales Arborizadora Baja y Verona
Grandes almacenes y supermercados Guadalupe
Industria Guadalupe y Rafael Escamilla
Zona para usos mixtos (vivienda, comercio,
equipamientos) Atlanta y El Ensueño
Densificación y estratificación: Referente a densificación, la UPZ 65 Arborizadora
tenía una población de 61850 habitantes para el año 2011 según las proyecciones de
población del DANE y una densidad urbana de 202 habitantes por hectárea.
En la UPZ están localizados predios pertenecientes a los estratos socioeconómicos 2
(bajo) y 3 (medio-bajo) (Secretaria Distrital de Planeación, 2011) con una
distribución de la población como se presenta en la Tabla 5.1.5.
Tabla 5.1. 5 Distribución de la población por estrato en la UPZ 65 Arborizadora
5.2. UPZ 73 Garcés Navas
Ubicación: La UPZ 73 Garcés Navas está localizada al occidente de la localidad 10,
Engativá, en la Ciudad de Bogotá, con un área total de 557.43 hectáreas (Alcaldía
Estrato Cantidad de
Habitantes (%) Cantidad de Hogares
Cantidad de Hogares
(%)
Estrato 2 (Bajo) 68.7 12234 68.7
Estrato 3 (Medio – Bajo) 31.1 5534 31.1
38
Mayor de Bogotá D.C - SDP, 2007) comprendidas entre los límites especificados en
la Tabla 5.2.1.
Tabla 5.2. 1 Límites UPZ 73 Garcés Navas
Norte Avenida Medellín (AC 80)
Límite con la UPZ Bolivia
Sur Calle 66ª y el Humedal Jaboque
Límite con la UPZ Álamos
Oriente Avenida Longitudinal de Occidente
Límite con la UPZ Boyacá Real
Occidente Río Bogotá, Límite del Distrito Capital
Extensión: Su extensión total está dividida como se muestra en la Tabla 5.2.2,
mostrando que la mayor parte de la unidad se encuentra urbanizada y no cuenta con
áreas protegidas.
Tabla 5.2. 2 Extensión UPZ 73 Garcés Navas
Área Total 557,43 hectáreas
Área Urbanizada 382,05 hectáreas
Área sin Urbanizar 118,03 hectáreas
Sectores y Centralidades: La UPZ 73 Garcés Navas está conformada por 23
sectores catastrales: El Gaco, Molinos de Viento, Los ángeles, Álamos, Villas de
Alcalá, El Cedro, Gran Granada, Bolivia, Villas de Granada I, Villas de Granada,
San Antonio, La Riviera, Garcés Navas, Garcés Navas Oriental, Garcés Navas Sur,
Villa Amalia, Florida Blanca, Villa Sagrario, Villa del Mar, El Dorado Industrial, El
Madrigal, Engativá el Dorado, Santa Mónica y Álamos Norte, distribuidos como se
presenta en la Figura 5.2.1.
39
Figura 5.2. 1 División por Sectores UPZ 73 Garcés Navas
La UPZ Garcés navas se beneficia por contener la centralidad4 Álamos, localizada en la
intersección de la Avenida Chile y la Avenida Longitudinal de Occidente (ALO), que
permite actividades comerciales y favorece la integración a la ciudad, por otra parte se
localiza cerca a otras dos, la Centralidad de Quirigua – Bolivia, también con una vocación
comercial, pero enfocada a integrar la ciudad con la región y la Centralidad de Fontibón –
Aeropuerto el Dorado – Engativá en donde se encuentran usos comerciales y equipamientos
como el Aeropuerto el Dorado, que permite la integración del país con el mundo (Alcaldía
Mayor de Bogotá D.C - SDP, 2007).
Sistema de Equipamientos : La UPZ cuenta con equipamientos de escala zonal,
vecinal y algunos a escala urbana, entre los más destacados están los destinados a
4 Las centralidades son espacios que concentran una gran actividad económica y de prestación de servicios
para la población, permitiendo la integración de la zona a escala internacional, nacional, regional o entre sectores (Alcaldía Mayor de Bogotá D.C - SDP, 2007).
40
educación, salud y bienestar entre los que se encuentran el Jardín infantil y Colegio
Fe y Alegría y la estación de bomberos y en menor cantidad se encuentran los
destinados a culto como las iglesias y templos, entre los que se encuentra la
Parroquia San Francisco de Borja en el Barrio Villas de Granada y a cultura como
salones comunales (Alcaldía Mayor de Bogotá D.C - SDP, 2007).
Vías de Acceso: Los ejes de la malla vial arterial para comunicar, acceder y
permitir la movilidad a través de la UPZ están conformados por las vías presentadas
en la Tabla 5.2.3.
Tabla 5.2. 3 Vías Malla Arterial UPZ 73 Garcés Navas
Usos del suelo: La UPZ 65 Garcés Navas está reglamentada por el Decreto 073 de
2006 (Secretaría General de la Alcaldía Mayor de Bogotá D.C, 2006) estableciendo
los usos del suelo como se muestra en la Tabla 5.2.4.
Tabla 5.2. 4 Usos del Suelo UPZ 73 Garcés Navas
Uso Barrios
Vivienda
El Gaco, Engativá El Dorado, El Dorado Industrial, Gran
Granada, Villas de Alcalá, Urbanización San Basilio, Los
Ángeles y Los Álamos
Vivienda con algunas zonas de comercio
Gran Granada, Villas de Granada, Molinos de Viento, Garcés
Navas Oriental, El Madrigal, Plazuelas del Virrey, El Pedregal,
Los Álamos
Vivienda con locales comerciales Barrios Garcés Navas, La perla, Villa Amalia, Bosques de
Mariana, Villas del Dorado
Comercial Zonal de gran actividad El Dorado Industrial
Zona para usos mixtos (vivienda,
comercio, equipamientos) Villas de Alcalá y Urbanización Esparta
Vía Sentido de Comunicación
Avenida Longitudinal de Occidente Borde Oriental de la UPZ
Avenida Bolivia (Carrera 104) Oriente – Occidente
Avenida Chile (Calle72) Oriente – Occidente
Avenida Medellín (Calle 80) Oriente – Occidente
Avenida Gonzalo Ariza (Carrera 110) Norte – Sur
Avenida El Cortijo (Carrera 114) Norte – Sur
Avenida El Salitre (Calle 66) Oriente – Occidente
41
Densificación y estratificación: Referente a densificación, la UPZ 73 Garcés
Navas tenía una población de 156478 habitantes para el año 2011 según las
proyecciones de población del DANE y una densidad urbana de 282 habitantes por
hectárea.
En la UPZ están localizados predios pertenecientes a los estratos socioeconómicos 1
(bajo-bajo), 2 (bajo) y 3 (medio-bajo) (Secretaria Distrital de Planeación, 2011) con
una distribución de la población como se presenta en la Tabla 5.2.5.
Tabla 5.2. 5 Distribución de la población por estrato en la UPZ 73 Garcés Navas
5.3. UPZ 79 Calandaima
La UPZ 79 Calandaima, se distingue por las características que se presentan a continuación:
Localización: La UPZ 79 Calandaima está localizada al centro occidente
(Secretaría distrital de planeación, 2009) de la localidad 8 de Kennedy en la Ciudad
de Bogotá, con un área de 319 hectáreas, comprendidas entre los límites
especificados en la Tabla.5.3.1 (García,W, 2013).
Tabla 5.3. 1 Límites UPZ 79 Calandaima
Norte Avenida las Américas
Limita con la UPZ Tintal Norte
Sur Avenida las Américas (AC 6) y Avenida de los Muiscas (Cl 38 sur)
Limita con la UPZ Patio Bonito
Oriente Avenida Ciudad de Cali y avenida El Tintal
Limita con las UPZ Castilla y Patio Bonito
Occidente Río Bogotá
Limita con el municipio de Mosquera
Estrato Cantidad de
Habitantes (%) Cantidad de Hogares
Cantidad de Hogares
(%)
Estrato 2 (Bajo) 16.6 6,515 22
Estrato 3 (Medio – Bajo) 78.8 23,680 78
42
Extensión: La UPZ Calandaima tiene una extensión de 319 hectáreas que
representan un 8.3% del total de la localidad de Kennedy (García,W, 2013).
Sectores Catastrales y Centralidades: La UPZ 79 Calandaima contiene los barrios
Tintalá, Osorio II, Galán, Galán Rural y Calandaima distribuidos como se muestra
en la Figura 5.3.1, estos sectores están en una etapa de desarrollo mediante la
construcción en PH, que para el año 2012 tuvo un notable incremento del 81.63%
desde el año 2002 (García,W, 2013).
Vías de acceso: Los ejes de la malla vial arterial para comunicar, acceder y permitir
la movilidad a través de la UPZ están conformados por las vías: Avenida Ciudad de
Densificación y estratificación: Esta UPZ cuenta con población perteneciente al
estrato dos y una gran parte sin estratificar (Secretaria Distrital de Planeación,
2011), como se presenta en la tabla 5.3.2.
Tabla 5.3. 2 Distribución de la población por estrato en la UPZ 79 Calandaima
Estrato Cantidad de Habitantes (%) Cantidad de Hogares
Estrato 2 (Bajo) 96.2 19974
Sin estrato 3.8 790
44
6. Marco teórico
Este capítulo contiene la información empleada en las diferentes etapas del desarrollo del
proyecto, teoría relacionada con temas de Ingeniería, matemática y tecnología.
6.1 Inteligencia artificial
Para dar una definición de Inteligencia Artificial (IA), en los documentos, se hace
referencia en primer lugar al significado de inteligencia dado por la RAE, en donde se
describe como la facultad de conocer, de entender o comprender; lo que lleva a pensar
desde una primera instancia en que el termino hará alusión al hecho de poseer las facultades
de la inteligencia de una manera artificial. Al tratar este tema diferentes autores dan su
concepto, unos de los más representativos son los de Marvin Minsky, padre de la
inteligencia artificial (Díaz, I, 2014) y el que aporta la Enciclopedia de la Inteligencia
Artificial, por un lado Minski la define como la ciencia de construir máquinas que hagan
cosas que, si las hicieran los humanos requerirían inteligencia (Cazorla,M, Alfonso, M,
Escolano, F, Colomina, O, & Lozano, M, 2003), y por otro, se afirma que es un campo de
la ciencia y la ingeniería que se ocupa de la comprensión, desde el punto de vista
informático, de lo que denomina comúnmente comportamiento inteligente, también se
ocupa de la creación de artefactos que exhiben este comportamiento (Pino,R, Gómez, A, &
de Abajo, N, 2001),de estas concepciones, se puede concluir, a fin de generalizar, que el
centro de la Inteligencia artificial, como ciencia y tecnología es buscar la manera de emular
las capacidades del ser humano, por lo que se han creado sistemas que se encaminan a
reproducir capacidades específicas.
45
Las áreas en las que la IA (Inteligencia Artificial) ha hecho presencia se clasifican, en
general, en las siguientes:
Tratamiento de lenguajes naturales: También conocido por sus siglas en inglés NLP
(Natural Language Processing) (García, A, 2012) consiste en hacer que un sistema sea
inteligente al permitir su interacción con los usuarios en su mismo lenguaje (Pino,R,
Gómez, A, & de Abajo, N, 2001), esta área de la IA engloba todas aquellas aplicaciones
que realizan traducciones entre idiomas, interfaces hombre – máquina que permiten
interrogar una base de datos o dar órdenes a un sistema operativo, haciendo que la
comunicación sea más amigable con el usuario.
Los productos comerciales que realizan tareas relacionadas con el procesamiento de
lenguaje natural se pueden clasificar, de manera general en:
Sistemas de consulta en lenguaje natural de bases de datos: Sistemas que traducen el
tipo de consultas que se pueden hacer a una base de datos, a la serie de instrucciones
adecuadas en el lenguaje informático de consulta de una base de datos.
Sistemas de búsqueda, reconocimiento y categorización de textos: Empleados para
seleccionar y filtrar la enorme masa de información que en la actualidad reciben y
tienen en sus bases de datos las empresas.
Sistemas de traducción automáticas
Programas de edición de textos: Programas que permiten la corrección ortográfica,
gramatical y de estilo de los textos que se escriben en ordenador.
“Máquinas de escribir” accionadas por la voz: Sistemas que reconocen los textos
que se desean mecanografiar (o los datos que se desean introducir en una hoja de
46
cálculo) y van “transcribiendo” en texto “dictado” a su correspondiente
representación escrita.
Productos de consumo: Productos que permiten un uso más “natural” de
determinados aparatos domésticos o profesionales. Como ejemplo están los
sistemas de programación de videos o teléfonos de coche accionados por la voz.
Razonamiento automático – Sistemas de Expertos: Hacen referencia a los sistemas
diseñados para que las máquinas imiten el comportamiento de los humanos, siendo capaces
de realizar conclusiones lógicas según información presente (Cazorla,M, Alfonso, M,
Escolano, F, Colomina, O, & Lozano, M, 2003).
Aprendizaje automático o de máquina: Son los sistemas que se elaboran mediante
modelos que permiten a la máquina “aprender” mediante una base de información
suministrada.
Representación del conocimiento: Dado que el sistema tiene la capacidad de “razonar y
de aprender”, la representación del conocimiento abarca el hecho de que esa información
que adquiere o infiere autónomamente pueda ser almacenado y recuperado de forma
eficiente, ya que no es útil almacenar datos si luego los sistemas no pueden acceder a estos
para usarlos, sacar conclusiones y obtener nueva información que no poseían de forma
directa.
Visión artificial y robótica: Son todos los sistemas de la IA que hacen posible el
reconocimiento de objetos y del habla, detección de defectos en piezas por medio de visión,
apoyo en diagnósticos médicos, etc.
47
Uno de los problemas con los que cuentan esta clase de procedimientos es el captar e
interpretar las imágenes del entorno que envuelve a un sistema inteligente y le está
enviando cantidades de “píxeles” o elementos de información que son fundamentales para
aprender y predecir acontecimientos.
Los aspectos más estudiados, en general, son de caracteres tipográficos y manuscritos,
interpretación de imágenes, reconocimiento de objetos, visión del color y análisis visual del
movimiento.
Esta área de la visión artificial y la manipulación de objetos, en otras palabras robots
móviles, sistemas para control de brazos, ensamble de piezas, etc. es conocida como
robótica (Pino,R, Gómez, A, & de Abajo, N, 2001).
6.2 Aprendizaje de máquina
La técnica de Inteligencia Artificial hace referencia a la modelización de conductas para su
posterior implementación en computadoras, mediante sistemas se busca hacer que las
máquinas sean capaces de realizar generalizaciones a partir de ejemplos sacados del
entorno, como lo mencionan Daniel y José Luis, (Sontag, E. D & Tesoro, J. L, 1972) en
cierto modo, lo que se desea es obtener máquinas capaces de resolver problemas que
requieran de “ingenio: Procesos de decisión complejos en medios potencialmente infinitos
e incontrolables y sentido común: el poder deducir automáticamente y por cuenta propia
una cantidad amplia de consecuencias inmediatas de lo que se dice y los conocimientos que
ya posee” (McCarthy, J, 1958). Para lograr esto se utilizan técnicas basadas en redes y
métodos probabilísticos como las redes bayesianas o de Markov, simulando el
48
comportamiento del cerebro humano a través de redes neuronales, es así como se establece
que la máquina sea capaz de “aprender” cosas nuevas, adaptarse al medio y generar una
respuesta, condición exigible a cualquier ser dotado de inteligencia (García, A, 2012), como
se muestra en la Figura 6.2.1. Existen cinco pasos generales en el proceso que constituye el
aprendizaje de máquina, distribuidos en dos etapas esenciales.
Figura 6.2. 1 Esquema de la técnica de Aprendizaje de máquina
Etapa 1: Etapa de Aprendizaje (Entrenamiento).
1. El componente humano del proceso aporta la información base5 o conjunto de datos
inicial.
2. Los datos son procesados mediante el algoritmo que genera el aprendizaje de la
máquina.
3. Generación de un modelo.
5 Información Base: Es la que se emite en el origen y no ha sufrido ningún tratamiento por el ordenador.
49
Etapa 2: Etapa de validación
4. El componente humano aporta una nueva información base o conjunto de datos.
5. (3) El conjunto de datos pasa a través del modelo.
6. (5) Se genera la información de resultados6
o la respuesta final, así como
información de la valides del modelo para ser empleado con datos de pronóstico.
La Inteligencia artificial comprende cinco enfoques principales en el aprendizaje
automático o aprendizaje de máquina, las redes neuronales artificiales, los algoritmos
genéticos, los métodos empíricos de inducción de reglas y árboles de decisión, el
aprendizaje analítico y los métodos basados en casos o por analogía.
Las Redes Neuronales Artificiales, ANN (Artificial Neural Netwoks) reciben su nombre
debido a la semejanza con las redes neuronales del cerebro humano, teniendo las
capacidades de aprender, generalizar y abstraer; así como las neuronas humanas cuentan
con el axón (salida) y se conecta con otras por medio de dendritas (entrada), una neurona
artificial como elemento procesador cuenta con entradas combinadas por medio de una
suma básica que se modifica a través de una función de transferencia y el valor resultante
de la función pasa a la salida del procesador, que a la vez se puede conectar con las
entradas de otros procesadores, formando de esta manera una red neuronal, en donde lo más
importante es la forma en que se conectan los elementos procesadores en niveles o capas
consecutivas (Bosogain, X, 2014).
6 Información de resultados: Es la que ha sido tratada completamente por el ordenador. A su vez puede ser:
Fija: Que permanece constante a través de los distintos tratamientos, o Variable: Que es susceptible de tomar valores diferentes de un proceso a otro (Cuevas, A, 1975).
50
Los algoritmos genéticos son una familia de métodos de búsqueda adaptativa de soluciones,
deben su nombre por su analogía con el cambio genético que se produce en las poblaciones
naturales y que está en la base de la selección natural y la evolución. Para esto se representa
la experiencia como una lista de propiedades o características binarias, en el sentido de que
puede estar presente o no en un determinado individuo o ejemplo que incrementa la
experiencia del sistema al estudiarlo.
Los procedimientos de aprendizaje analítico se especializan más en mejorar el rendimiento
de sistemas de resolución de problemas, transformando el conocimiento que contiene el
sistema en una estructura más eficiente para conseguir el objetivo perseguido.
Otro enfoque del tema de aprendizaje consiste en incluir en el programa de razonamiento
basado en casos descritos anteriormente, por el cual el programa, de forma análoga a como
lo hacen muchos especialistas humanos, es capaz de memorizar y recuperar fácilmente
casos en los que se ha tenido éxito en la resolución de un problema y adaptarlos a nuevas
situaciones similares.
6.3 Árboles de decisión
La técnica de árboles de decisión, hace parte del enfoque del aprendizaje de máquina, cuya
implementación en el campo de proyectos actuales recién se está implementando (Suárez, J,
2000). Esta técnica forma parte de los métodos de inferencia inductiva, dado que de
información particular se llega a deducir información general (Mitchell, T, 1997).
Los árboles de decisión son una agrupación de reglas organizadas en una estructura
jerárquica, de tal forma que la decisión final se puede determinar al hacer un seguimiento a
51
las condiciones que se cumplen, desde la raíz hasta alguna de las hojas (Vizcaino, P. A,
2008).
Como se presenta en la Figura 6.3.1, la estructura de un árbol de decisión se compone por:
Raíz o nodo Inicial: Es representada por un óvalo, está localizada en la parte
superior del árbol y contiene el atributo seleccionado para dar inicio a la
clasificación.
Ramas: Son representadas con líneas, se encuentran localizadas al interior del árbol
desprendiéndose de la raíz y de los nodos internos y contienen las reglas que
permitiran las clasificaciones para aplicar a los valores del atributo del nodo del cual
se desprenden.
Nodos internos: Son representados con óvalos, están localizados dentro del árbol y
contienen los atributos seleccionados para guiar la clasificación.
Nodos finales o nodos Hoja: Son representados con rectángulos, están localizados en los
extremos finales del árbol de decisión y contienen la regla que permitirá la clasificación
final.
52
Figura 6.3. 1 Ejemplo de árbol de decisión
Para hacer la clasificación el método de árboles de decisión empieza por identificar el
atributo que será el punto de partida y llevarlo a través de los componentes del árbol,
iniciando por la raíz y pasando por distintos nodos hasta llegar a una hoja o nodo final, este
árbol puede continuar aprendiendo de nuevos pares de datos valor/atributo que el agente
humano anexe al sistema para enriquecerlo y generar mejores respuestas (Vicente, C,
2004).
De manera práctica, se presenta parte de un árbol de decisión en la Figura 6.3.2, el ejemplo
muestra la clasificación del elemento Metro Cuadrado de Construcción.
1. Se selecciona el atributo Puntaje y se localiza en la raíz e inicia a recorrer las ramas.
2. Al recorrer las ramas, se verifica si el atributo Puntaje es mayor a 30.5 puntos o
menor o igual a 30.5 puntos.
3. Si el atributo es menor o igual a 30.5 puntos, se pasa a revisar el siguiente nodo que
contiene el atributo Edad.
53
4. De las ramas que se desprenden del nodo Edad, se revisa si el atributo es menor o
igual a 12.5 años o mayor a 12.5 años.
5. Si el atributo es menor o igual a 12.5 años, entonces seguirá la rama correspondiente
y finalizará el recorrido por el árbol en el nodo final o nodo hoja que contiene la
regla 1.
6. Si el atributo es mayor a 12.5 años, seguirá la rama correspondiente y pasará al
nodo que contiene el atributo Puntaje.
7. Si el atributo es menor o igual a 26.5 puntos, seguirá la rama correspondiente y
finalizará el recorrido en el nodo hoja que contiene la regla 2.
8. Si el atributo es mayor a 26.5 puntos, entonces continuará el recorrido a los
siguientes nodos hasta recorrer todo el árbol.
El algoritmo de árboles de decisión permite solucionar problemas que contengan
características como las siguientes:
Instancias representadas por pares valor / atributo: Para algunos casos, los
atributos, que son fijos como estrato y número de pisos, los valores pueden ser
Figura 6.3. 2 Ejemplo de reglas generadas por un Árbol de Decisión
54
también fijos como bajo-Bajo, Medio, etc. y 1, 2, o 3, pero también hay casos como
el área de terreno, para ambos casos el algoritmos es útil.
La función objetivo tiene valores de salida discretos: Para algunos trabajos, la
función de salida puede constituirse por valores booleanos, no obstante, el método
se extiende a funciones con más de dos valores de salida.
Cuando se requiere una separación de descripciones: Como se presenta en el
ejemplo, en los árboles de decisión siempre se presentan expresiones separadas.
Los datos de entrenamiento pueden tener errores: Los métodos de aprendizaje
de árboles de decisión presentan una significativa resistencia a los errores que
puedan tener los atributos de los datos empleados en el entrenamiento.
Los datos de entrenamiento no contienen los valores de los atributos
completos: El algoritmo de árboles de decisión se puede emplear incluso cuando en
los ejemplos de formación hayan valores desconocidos.
Existen muchas situaciones en el medio cotidiano que presentan estás características y para
las que han sido útiles emplear los algoritmos de árboles de decisión, entre esas está la
clasificación de pacientes clínicos, de solicitantes de créditos, del mal funcionamiento de
equipos, de imágenes de sensores remotos, entre otras, en donde es necesario que a partir de
un conjunto de datos se genere un aprendizaje para generalizar esa clasificación a datos
nuevos (Mitchell, T, 1997).
55
6.4 Entropía de la información
El término entropía procede del griego em, que significa sobre, en y cerca de; y sqopg, que
significa giro, alternativa, cambio, evolución o transformación. En termodinámica es una
magnitud física que mide el grado de desorden que tiene un sistema (Arnheim, R, 1995),
recibió este nombre por Rudolf Clausius en 1850 y Ludwig Boltzmann quien lo expresó
matemáticamente mediante probabilidades en el año de 1877 (Clausius, R, 1865).
De manera semejante, la Entropía de la información o Entropía de Shannon es una medida
de la incertidumbre de información suministrada y se considera como la cantidad promedio
que contienen los elementos empleados en un experimento (Cuevas, A, 1975). Recibe este
nombre en honor a Claude E. Shanon, que junto con Warren Weaver elaboraron, en 1948,
una teoría de la información basada en los fenómenos de la comunicación en la cibernética,
en donde estudiaba la capacidad de información de un mensaje en función de la capacidad
del medio por el que se transmitía, esta capacidad es medida en un sistema binario (0 y 1)
en bits (binary digits) relacionados con la velocidad de transmisión del mensaje, la cual
puede aumentar o disminuir según la cantidad de ruido (Rodrigo, M, 2011), como afirma
Norbert Wiener “Por su naturaleza, los mensajes son una forma y una organización.
Efectivamente es posible considerar que su conjunto tiene una entropía como la que tienen
los conjuntos de los estados particulares del universo exterior. Así como la entropía es una
medida de desorganización, la información que suministra un conjunto de mensajes, es una
medida de organización. De hecho puede estimarse la información que aporta uno de ellos
como el negativo de su entropía cuanto más probable es el mensaje, menos información
contiene”. (Wiener, N, 1988)
56
Actualmente esta medida se emplea para medir la incertidumbre de información de
diferentes experimentos, brindando una base fuerte para la toma de decisiones dentro de los
mismos.
La entropía está dada por la Ecuación 6.4.1:
𝐸𝑛𝑡𝑟𝑜𝑝í𝑎(𝑆) = −𝑝+𝑙𝑜𝑔2𝑝+ − 𝑝−𝑙𝑜𝑔2𝑝−
Ecuación (6.4. 1) Entropía (S)
En dónde:
𝑝+ = Promedio de ejemplos positivos en S.
𝑝− = Promedio de ejemplos negativos en S.
Como primer ejemplo ilustrativo, se tiene un experimento en el que se cuenta con 19
ejemplos, de los cuales 13 son positivos y 6 negativos.
Según los resultados obtenidos, el mejor clasificador para este experimento será el atributo
Puntaje, con una ganancia de información de 0.5576, como se observa en la Figura 6.5.1,
atributo que se localizará en la raíz del árbol como base para continuar el proceso.
6.6 Método ID3
Dentro de los métodos de árboles de decisión los sistemas que se han destacado son los de
J. Ross Quinlan, de 1979, 1983, 1986, 1988 y 1993, entre otros (Suárez, J, 2000). En
especial sobresale su modelo de 1979, por presentar buenas características, como el menor
número de preguntas posible para encontrar respuesta en cada caso, para llegar a este
modelo empleó la teoría de la Información dada por C. Shannon en 1948. Este primer
programa clasificador, que en su versión más perfeccionada fue denominado ID3 (Iterative
Dichotomizer - Dicotomizador Iterativo) ha sido frecuentemente empleado y mejorado por
Quinlan y otros autores (Sancho, F, 2016).
PU
NT
AJ
E G
=0
.55
76
PUNTAJE4 0
PUNTAJE7 0.9852
PUNTAJE12 0
ED
AD
G=
0.1
65
9
EDAD 3 E=0
EDAD 4 E=0.94
VA
LO
R_
M2
TE
RR
EN
O
G=
0.0
93
5
VAL_M2TERR8 E=0.9182
VAL_M2TERR15 E=0.8812
Figura 6.5. 1 Comparación de resultados de Ganancia de información
65
El método de aprendizaje inductivo ID3 es empleado para la clasificación de clases y
atributos de valores discretos (Kirkby, R, 2003), consiste en crear de forma automática un
árbol de decisión a partir de los datos de entrada para el entrenamiento, cumpliendo con las
siguientes características:
Crearlo iniciando por la raíz y terminando con las hojas.
De forma directa.
Sin realizar backtracking o búsqueda hacia atrás, en otras palabras, no hace una
segunda revisión de los ejemplos que ya han sido evaluados.
En su entrenamiento emplea específicamente los ejemplos suministrados.
Para construir el árbol de decisión, el método ID3 emplea la Ganancia de
Información con el fin de elegir el atributo más útil en cada paso y colocarlo en el
nodo correspondiente a medida que crece, el proceso continúa hasta que se haga una
clasificación completa de los ejemplos que conforman el conjunto de entrenamiento
o hasta que se hayan empleado todos los atributos (Mitchell, T, 1997).
6.7 Método J48 o C4.5
El algoritmo J48 es una implementación libre del algoritmo C4.5 de Quinlan en Java
(Antonelli, S, 2012) con el que cuenta el software Weka.
El método C4.5 es un algoritmo de inducción desarrollado por Ross Quinlan como una
extensión, debido a algunas mejoras, del algoritmo ID3, por lo que sus desarrollos serán
semejantes.
Para llegar a crear un árbol de decisión por medio del algoritmo C4.5 en primer lugar se
determinará un conjunto de datos de entrenamiento, estos serán divididos en subconjuntos
66
que serán evaluados mediante la ganancia de información para determinar el que será el
atributo con mayor ganancia y actuará como parámetro de decisión en la clasificación, este
será el que ocupe el nodo raíz. Para continuar con la clasificación, el algoritmo se vale de
dos herramientas llamadas “info” y “gain”, mediante la regla representada en las ramas se
calcula la información que aporta al proceso y por la herramienta “gain” calcula la mejora
global que genera la regla, por medio de estos dos criterios se decide de una manera certera
el recorrido a seguir en el árbol, tomando como punto de partida los resultados del ciclo
anterior, calculando la precisión del modelo según la totalidad de los datos y obteniendo en
la salida una variable categórica (Vizcaino, P. A, 2008).
Dado que el algoritmo C4.5 es una mejora del algoritmo ID3, algunos de los avances con
los que cuenta son:
1. Manejo de atributos continuos y discretos: Para trabajar en el proceso con
atributos continuos, el algoritmo genera un límite y divide los valores de los
atributos entre los que son mayores y los que son menores, o iguales al límite.
2. Manejo de los datos del conjunto de ejemplos con información faltante: Todos
los atributos son incluidos aun cuando no tengan la información completa,
omitiéndola en los cálculos de entropía y ganancia de información.
3. Eliminación de ramas que no aportan información: El proceso de poda o
Pruning puede ser implementado en dos ocasiones, mientras está creciendo el árbol
o cuando está completo, en el primer caso es llamado prepruning, proceso que se
lleva a cabo en el momento en que no se encuentran suficientes datos para tomar
decisiones confiables para que el árbol continúe creciendo y en el segundo caso,
67
llamado postpruning, se deja crecer por completo el árbol y se eliminan los sub-
árboles que no aportan suficiente información. Luego de que se ha creado el árbol,
el algoritmo se devuelve a buscar las ramas que no aportan suficiente información
en el proceso, poda7, para reemplazarlas por nodos finales o nodos hoja. Entre los
métodos empleados para determinar los sub-árboles a podar se encuentra:
La validación cruzada, en donde se reservan datos del entrenamiento
(validation set – tuning set) para evaluar la utilidad de los sub-árboles.
Los test estadísticos, empleados en los conjuntos de entrenamiento para
determinar información que se puede eliminar.
Longitud mínima de descripción - MDL (Minimum description length), que
permite determinar si la hipótesis del árbol completo es más compleja que
la del árbol resultante del recorte (Quilan, J, 1996).
4. Evitar el sobreajuste de datos: A diferencia del ID3, el algoritmo C4.5 realiza una
búsqueda de las hipótesis o conjunto de árboles de decisión para ajustar los datos de
entrenamiento, el conjunto de hipótesis está conformado desde el árbol vacío, hasta
los árboles más elaborados, de los cuales se selecciona el que clasifica
correctamente los datos de entrada, dentro de este proceso se tiene en cuenta el
sesgo inductivo, que hace referencia al principio de la navaja de Ockham8
,
prefiriendo los árboles cortos a los más grandes, debido a que los árboles más cortos
7 La poda consiste en eliminar el subárbol con raíz en un nodo interno, esto ocurre sólo cuando el árbol
podado es mejor al árbol original, según el conjunto de validación (Mitchell, T, 1997) 8 El principio atribuido a Guillermo de Ockham establece que “En igualdad de condiciones, la explicación más
sencilla suele ser la más probable” , cabe resaltar que en igualdad de condiciones, ya que en caso diferente “La explicación más simple y suficiente es la más probable, más no necesariamente la verdadera”, entonces en caso de que existan mayores pruebas para una hipótesis compleja, esta será preferida a una segunda, que aunque sea simple no tenga pruebas suficientes (Cambridge University, 1995).
68
contarán con una mayor información cerca a la raíz, generalicen mejor y contengan
menos atributos irrelevantes (Mitchell, T, 1997).
6.8 Método M5P
El método M5P 9es un algoritmo de aprendizaje de máquina inductivo mediante árboles de
decisión, es una reconstrucción del algoritmo M5 creado por Quinlan y mejorado por Yong
Wang (Borao, D, 2013). .El M5P es aplicable a modelos con atributos cuyos valores sean
numéricos y combina el árbol de decisión con funciones de regresión lineal (Calleja, A,J,
2010).
La manera en que trabaja este atributo es construyendo un árbol de decisión, no obstante,
en lugar de maximizar la información obtenida en cada nodo, minimiza la variación interna
de los subconjuntos para los valores de cada rama, este proceso de división se detiene
cuando los valores de todos los atributos varían ligeramente, o solo permanecen algunas
instancias. Luego de este primer proceso, el árbol es recortado, de tal manera que al cortar
un nodo interno, este pasa a ser una hoja que contiene un modelo de regresión lineal
(Bellogín, A, 2008). Finalmente, para evitar discontinuidades entre los sub – árboles, se
hace una revisión desde las hojas hasta la raíz, haciendo más preciso el valor de los nodos
al combinarlos con el valor predicho por el modelo de regresión lineal para cada nodo de
forma respectiva.
Como resultado del algoritmo M5P, se obtienen reglas que son aplicadas si los datos
cumplen o no con determinadas condiciones (Calleja, A,J, 2010).
9 Siglas de M5Prime (Principal).
69
Algunas condiciones que existen para la implementación de este algoritmo son:
No maneja instancias ponderadas por pesos.
No permite que se actualice de forma incremental.
Cuando el valor de un atributo no está determinado, este algoritmo lo reemplaza con
la media global o la moda del conjunto de datos de entrenamiento antes de que se
construyera el árbol.
Al ejecutar el algoritmo M5P en WEKA, este hace un proceso de suavizado
automático que se puede desactivar, adicionalmente también es posible decirle la
profundidad del podado y la cantidad de información en la salida. (Kirkby, R, 2003)
6.9 Métodos de validación
Al trabajar en aprendizaje de máquina y obtener árboles de decisión, existe una etapa que es
la validación, en esta parte lo que hace el algoritmo es revisar la efectividad del modelo
desarrollado, entre los métodos de validación se encuentran los siguientes:
Cross Validation - Validación Cruzada: La validación cruzada consiste en
proporcionar un número n de particiones (folds), este será el número en el que se
dividirá el conjunto de datos, posteriormente se construirá un clasificador con los n-
1 sub-conjuntos , estos serán entonces los datos de entrenamiento y los datos
restantes serán los datos de prueba, este procesos se repetirá con las n particiones,
hasta que todos los datos hayan sido de entrenamiento y de prueba en las respectivas
iteraciones, como se representa en la Figura 14, para un conjunto de 20 datos y n=5.
70
Una validación cruzada es estratificada cuando una de las particiones o
subconjuntos conserva las propiedades de la muestra original respecto al porcentaje
de elementos de cada clase (Corso, C, 2009).
Datos de Datos de
Prueba Entrenamiento
Iteración 1 A B C D E F G H I J K L M N O P Q R S T
Iteración 2 A B C D E F G H I J K L M N O P Q R S T
Iteración 3 A B C D E F G H I J K L M N O P Q R S T
Iteración 4 A B C D E F G H I J K L M N O P Q R S T
… … … … … … … … … … … … … … … … … … … …
Iteración n=5 A B C D E F G H I J K L M N O P Q R S T
Total de datos
Figura 6.9. 1 Ejemplo de Validación Cruzada - Cross Validation
.Percentage Split - División de Porcentajes: Mediante esta validación se elige un
porcentaje del conjunto de datos para el entrenamiento del modelo y el porcentaje
de datos restante será el empleado para realizar la prueba de calidad de la
clasificación (García, F, 2013).
Supplied test set - Conjunto de prueba suministrado: Este método de validación
permite realizar el entrenamiento del modelo con el conjunto completo de los datos
y la prueba con un conjunto diferente de datos (Hernández, J, 2006).
6.10 WEKA
WEKA10
(Waikato Enviroment for Knowledge Analysis) es un Software libre desarrollado
en Java por la universidad de Waikato en Nueva Zelanda.
10
Sitio para descargar WEKA: http://www.cs.waikato.ac.nz/~ml/weka/
71
Figura 6.10. 1 Ventana de Inicio. Weka, Versión 3.6.13
Como se puede observar en la Figura 6.10.1, en la ventana principal del software, este
cuenta con 4 entornos de trabajo, Explorer, Experimenter, KnowledgeFlow y Simple CLI,
cada uno para desarrollar tareas específicas.
Explorer: Entorno empleado para hacer uso de los paquetes de WEKA con datos
proporcionados por el usuario.
Experimenter: Entorno diseñado para facilitar la automatización del trabajo con
experimentos a gran escala
KnowledgeFlow: Espacio diseñado para la creación de proyectos de minería de
datos por medio de la generación de flujos de información.
Simple CLI: Como entorno de consola permite llamar directamente desde Java los
paquetes disponibles en WEKA (Hernández, J, 2006).
72
Figura 6.10. 2 Entorno Explorer del Software WEKA
El entorno más empleado por contener la mayor funcionalidad de WEKA es el Explorer,
presentado en la Figura 6.10.2.
Los seis sub-entornos de ejecución, visibles en las pestañas del Explorer son los descritos
en la Tabla 6.10.1.
WEKA trabaja con archivos tipo .arff, por lo que es importante conocer la estructura que
deben tener los datos para que los conjuntos de información puedan recibir el tratamiento
adecuado, además de que el programa los lea correctamente (Morate, D, 2000).
73
Tabla 6.10. 1 Descripción de las opciones presentes en el entorno Explorer del Software WEKA
Herramienta Visualización Descripción
Classify
Acceso mediante las diversas herramientas a los
algoritmos de clasificación y regresión.
Cluster
Visualización de diversos métodos de agrupación
para los datos.
Associate
Generación de algunas reglas de asociación entre
las clases y atributos del conjunto de datos.
Select Attributes
Mediante diferentes técnicas se encuentran los
atributos más representativos del modelo.
Visualize
Visualización del comportamiento del conjunto
de datos por clases y atributos.
La estructura de los archivos debe ser la siguiente:
1. Encabezado: Para iniciar el archivo se escribe @relation y en seguida el Nombre
con el que se identificará el conjunto de datos.
74
2. Declaración de atributos: En segundo lugar se declaran los atributos, teniendo en
cuenta si son nominales o numéricos.
a. Declaración de atributos nominales: @attribute, seguido por el nombre del
atributo y entre corchetes {} los nombres de las clases, separados por comas.
Supplied test set Conjunto de datos diferentes a fin de realizar el
pronóstico
7.4 Estructura preliminar del experimento, clasificación de los datos para el
procesamiento en el software WEKA
Con el fin de procesar los datos y obtener los resultados de los árboles de decisión, es
necesario verificar las bases de datos para determinar la información que será necesaria,
eliminar la que no se requiere y conformar los diferentes grupos en que se procesarán los
datos.
De acuerdo con el proceso presentado en la Figura 7.4.1, luego de tener el conjunto de
datos de cada UPZ, el siguiente paso es depurar la información y contar estrictamente con
los datos necesarios para el experimento.
Al realizar este primer proceso los conjuntos de datos quedaron conformados de la manera
que se muestra en la Tabla 7.4.1.
Tabla 7.4. 1 Comparación de cantidad de datos por UPZ luego de la depuración
UPZ Cantidad de datos
Suministrados
Cantidad de datos después de la
depuración
UPZ 73 Garcés Navas 38712 34073
UPZ 65 Arborizadora 18903 16736
UPZ 79 Calandaima 33294 33157
92
Figura 7.4. 1 Proceso de conformar los conjuntos de datos del experimento
Al tener el conjunto de datos de cada UPZ depurado, se realizó una división en PH y
No_PH, ya que se tuvieron en cuenta características diferentes para cada uno de los grupos,
de donde se extrajeron 20 datos aleatorios del conjunto de PH y 20 del conjunto No_PH
designados para pruebas finales, quedando el conjunto para entrenamiento, validación y
pronóstico con las cantidades de datos descritas en la Tabla 7.4.2 y conformados con los
atributos contenidos en la Tabla 7.4.3.
93
Tabla 7.4. 2 Cantidad de datos para entrenamiento, validación y pronóstico según PH y NO_ PH
UPZ
Cantidad de datos
Conjunto para entrenamiento,
validación y pronostico PH
Cantidad de datos
Conjunto para entrenamiento,
validación y pronostico NO_PH
UPZ 73 Garcés Navas 15217 18816
UPZ 65 Arborizadora 9935 6761
UPZ 79 Calandaima 30341 2775
Debido a que se desarrollarán los experimentos con métodos de árboles de decisión
empleando conjuntos de datos numéricos y nominales por aparte para que sean procesados
por el software, fue necesario realizar clasificaciones de los datos y expresarlos de forma
nominal y numérica, generando dos expresiones de cada dato.
Para el caso de los atributos numéricos con grandes rangos que se debían pasar a
nominales, se realizaron divisiones de grandes grupos, de manera arbitraria y
posteriormente, una clasificación empleando la creación de intervalos mediante la regla de
Sturges.
Luego de tener la expresión de los datos de forma nominal y numérica para el conjunto de
PH y No_PH, se seleccionó de manera aleatoria un 5% de cada conjunto de datos a fin de
dejarlos para realizar el pronóstico, como se muestra al final de la Figura 7.4.1 y quedando
con las cantidades de datos presentadas en la Tabla 7.4.4.
94
Tabla 7.4. 3 Atributos seleccionados para procesar
UPZ Atributos PH Atributos No_PH
UPZ 73 Garcés Navas
Sector
Edad
Puntaje
Estrato
Actividad
Tratamiento
Área construida
Valor m2 de construcción
Sector
Pisos
Edad
Puntaje
Estrato
Actividad
Tratamiento
Área de terreno
Valor m2 de Terreno
Área de construcción
Valor m2 de construcción
UPZ 65 Arborizadora
Sector
Uso
Edad
Puntaje
Estrato
Actividad
Tratamiento
Área construida
Valor m2 de construcción
Sector
Uso
Pisos
Edad
Puntaje
Estrato
Actividad
Tratamiento
Área terreno
Valor m2 de terreno
Área de construcción
Valor m2 de construcción
UPZ 79 Calandaima
Sector
Uso
Edad
Puntaje
Estrato
Actividad
Área construida
Valor m2 de construcción
Sector
Uso
Pisos
Edad
Puntaje
Estrato
Actividad
Tratamiento
Área terreno
Valor m2 terreno
Área construida
Valor m2 de construcción
Tabla 7.4. 4 Cantidad de datos para conjunto de entrenamiento y validación y conjunto de pronóstico
UPZ
PH NO_PH
Cantidad de datos
Entrenamiento y
Validación
Cantidad de datos
Conjunto Pronóstico
Cantidad de datos
Conjunto para
Entrenamiento y
Validación
Cantidad de
datos
Conjunto
Pronóstico
UPZ 73 Garcés
Navas 14456 761 17875 941
UPZ 65
Arborizadora 9438 497 6423 338
UPZ 79
Calandaima 28824 1517 2636 139
95
7.4.1 Atributo sector
Este atributo está presentado de forma numérica y nominal en la base de datos original,
debido a algunas inconsistencias que se verificaron, el trabajo que requirió este atributo fue
la corrección de algunos nombres. Su representación numérica corresponde al código que
identifica al sector catastral dentro de la ciudad de Bogotá D.C en el que está localizado el
predio. Su representación numérica en la base de datos recibe el nombre de SECTOR y su
representación nominal fue nombrada como CLAS_SECTOR. La presentación11
del
atributo sector para cada UPZ se presenta en la tabla 7.4.1.1.
UPZ SECTOR CLAS_SECTOR
UPZ 73 Garcés Navas
5643 ALAMOS
5675 BOLIVIA
5629 EL_CEDRO
5663 EL_DORADO_INDUSTRIAL
5669 EL_GACO
5635 EL_MADRIGAL
5627 GARCES_NAVAS
5628 GARCES_NAVAS_ORIENTAL
5655 GARCES_NAVAS_SUR
5654 GRAN_GRANADA
5623 LOS_ANGELES
5641 SANTA_MONICA
5648 VILLA_AMALIA
5658 VILLA _SAGRARIO
5668 VILLAS_DE_ALCALÁ
5647 VILLAS_DE_GRANADA
5649 VILLAS_DE_GRANADA_I
UPZ 65 Arborizadora
2432 ARBORIZADORA_BAJA
2422 ATLANTA
2435 EL_CHIRCAL_SUR
4563 GUADALUPE
2420 LA_CORUNA
2415 MADELENA
2421 RAFAEL_ESCAMILLA
UPZ 79 Calandaima
4601 CALANDAIMA
4627 GALAN
6518 OSORIO_III
6516 TINTALA
11
la manera en que están escritos los nombres de los atributos y sectores corresponde a la forma en que se introdujeron en el archivo .arff para que fuera procesado por el software WEKA.
96
7.4.2 Atributo uso
El atributo uso está presentado de forma numérica en la base de datos original, razón por la
que se procedio a buscar el significado de cada uno de los códigos de uso de los inmuebles
para tener su presentación nominal. Este atributo corresponde a la actividad económica que
se le da a la construcción en un predio al momento de su reconocimiento, el uso de la
construcción está definido para predios en Propiedad horizontal y en No Propiedad
Horizontal (Unidad Administrativa Especial de Catastro Distrital, 2005).
Tabla 7.4.2. 1 Atributo uso para predios No PH
CODIGO_USO USO CLAS_USO
1 HABITACIONAL MENORES O IGUALES A 3 PISOS HAB_ME3P
2 HABITACIONAL MAYORES O IGUALES A 4 PISOS HAB_ME4P
3 COMERCIO PUNTUAL CP
4 COMERCIO EN CORREDOR COMERCIAL CCC
5 OFICINAS OPERATIVAS OO
9 ACTIVIDAD ARTESANAL AA
10 INDUSTRIA MEDIANA IND_M
11 INDUSTRIA GRANDE IND_G
12 INSTITUCIONAL PUNTUAL INS_P
13 COLEGIOS Y UNIVERSIDADES DE 1 A 3 PISOS CYU_3P
14 IGLESIAS IGL
15 OFICINAS Y CONSULTORIOS DOTACIONAL OFICIAL OYC_DO
16 COLEGIOS Y UNIVERSIDADES DE 4 PISOS O MAS CYU_MA4P
20 OFICINAS Y CONSULTORIOS OYC
22 DEPOSITO DE ALMACENAMIENTO DA
25 BODEGAS DE ALMACENAMIENTO BA
33 BODEGA ECONOMICA BE
70 ENRAMADAS- COBERTIZOS- CANEYES ECC
80 OFICINAS EN BODEGA Y/O INDUSTRIAS OBYOI
En la base de datos, se designa como CODIGO_USO, para su presentación numérica y
CLAS_USO, para su presentación nominal, debido a lo extendido de los nombres, se
97
emplearon abreviaturas descritas en la Tabla 7.4.2.1 para los predios en No PH y en la
Tabla 7.4.2.2 para los predios en PH.
Tabla 7.4.2. 2 Atributo uso para predios PH
CODIGO_USO USO CLAS_USO
37 HABITACIONAL MENOR O IGUAL A 3 PISOS HAB_ME3P_PH
38 HABITACIONAL MAYOR O IGUAL A 4 PISOS HAB_MA4P_PH
39 COMERCIO PUNTUAL LOCAL COMERCIAL CP_LC_PH
40 COMERCIO EN CORREDOR COMERCIAL CCC_PH
42 CENTRO COMERCIAL GRANDE CCG_PH
44 INSTITUCIONAL PUNTUAL IP_PH
45 OFICINAS Y CONSULTORIOS PROPIEDAD PARTICULAR OYC_PP_PH
90 PREDIOS SIN CONSTRUIR EN PH PSC_PH
95 CENTRO COMERCIAL PEQUEÑO CCP_PH
7.4.3 Atributo pisos
El atributo pisos se encuentra en la base de datos expresado como un atributo numérico,
está contenido únicamente en los conjuntos de datos de los predios que no están bajo el
régimen de propiedad horizontal (No_PH) y hace referencia a la cantidad de pisos
construidos en altura. Es presentado como NUM_PISOS para los valores numéricos y
CLAS_PISOS para los valores nominales, para realizar su clasificación se realizaron los
rangos presentados en la Tabla7.4.3.1.
Tabla 7.4.3. 1 Atributo pisos
NUM_PISOS CLAS_PISOS
0 P0
1 A 2 P1
3 A 4 P2
5 A 6 P3
7 A 14 P4
15 A 25 P5
98
7.4.4 Atributo edad
El atributo edad se encuentra expresado en la base de datos como un atributo numérico, es
presentado como EDAD para los valores numéricos y CLAS_EDAD para los valores
nominales. Para su presentación nominal se realizó una clasificación por medio del método
de sturges teniendo para los intervalos las características presentadas en la Tabla 7.4.4.1 y
obteniendo los conjuntos de clasificación como se muestran en la Tabla 7.4.4.2.
Tabla 7.4.4.1 Características de la clasificación: atributo edad
L 5
K 14
X MIN 0
XMAX 70
Tabla 7.4.4.2 Clasificación atributo edad
Límite inferior Límite superior CLAS_EDAD
0 5 EDAD1
5 10 EDAD2
10 15 EDAD3
15 20 EDAD4
20 25 EDAD5
25 30 EDAD6
30 35 EDAD7
35 40 EDAD8
40 45 EDAD9
45 50 EDAD10
50 55 EDAD11
55 60 EDAD12
60 65 EDAD13
65 70 EDAD14
99
7.4.5 Atributo puntaje
El atributo puntaje se encuentra expresado en la base de datos como un atributo numérico,
es presentado como PUNTAJE para los valores numéricos y CLAS_PUNTAJE para los
valores nominales. Para su presentación nominal se realizaron tres subconjuntos y las
respectivas clasificaciones por medio del método de sturges teniendo para los intervalos las
características presentadas en la Tabla 7.4.5.1 y obteniendo los conjuntos de clasificación
como se muestran en las Tablas 7.4.5.2, 7.4.5.3 y 7.4.5.4.
Tabla 7.4.5.1 Características de la clasificación: atributo puntaje
Grupos Características Valores
Grupo 1 Valor único 0
Grupo 2
L 6.6
K 15
XMIN 1
XMAX 100
Grupo 3
L 37.375
K 8
XMIN 101
XMAX 400
Tabla 7.4.5. 2 Clasificación atributo puntaje, grupo1
Valor CLAS_PUNTAJE
0 1PUNTAJE0
100
Tabla 7.4.5. 3 Clasificación atributo puntaje, grupo 2
Límite inferior Límite superior Aproximación
Límite inferior
Aproximación
Límite superior CLAS_PUNTAJE
1 7.6 1 8 2PUNTAJE1
7.6 14.2 8 14 2PUNTAJE2
14.2 20.8 14 21 2PUNTAJE3
20.8 27.4 21 27 2PUNTAJE4
27.4 34 27 34 2PUNTAJE5
34 40.6 34 41 2PUNTAJE6
40.6 47.2 41 47 2PUNTAJE7
47.2 53.8 47 54 2PUNTAJE8
53.8 60.4 54 60 2PUNTAJE9
60.4 67 60 67 2PUNTAJE10
67 73.6 67 74 2PUNTAJE11
73.6 80.2 74 80 2PUNTAJE12
80.2 86.8 80 87 2PUNTAJE13
86.8 93.4 87 93 2PUNTAJE14
93.4 100 93 100 2PUNTAJE15
Tabla 7.4.5. 4 Clasificación atributo puntaje, grupo 3
Límite inferior Límite superior Aproximación
Límite inferior
Aproximación
Límite superior CLAS_PUNTAJE
101 138.375 101 138 3PUNTAJE1
138.375 175.75 138 176 3PUNTAJE2
175.75 213.125 176 213 3PUNTAJE3
213.125 250.5 213 251 3PUNTAJE4
250.5 287.875 251 288 3PUNTAJE5
287.875 325.25 288 325 3PUNTAJE6
325.25 362.625 325 363 3PUNTAJE7
362.625 400 363 400 3PUNTAJE8
7.4.6 Atributo estrato
El atributo estrato hace referencia a la clasificación de los inmuebles residenciales a los
cuales se proveen servicios públicos y son clasificados en seis rangos: 1. Bajo-bajo, 2. Bajo,
3. Medio-bajo, 4. Medio, 5. Medio-alto y 6. Alto. (Congreso de Colombia, 1994). En la
base de datos se encuentra expresado como un atributo numérico, es presentado como
101
ESTRATO para los valores numéricos y CLAS_ESTRATO para los valores nominales. Su
presentación numérica y nominal para los valores presentes en las bases de datos son los
contenidos en la Tabla 7.4.6.1.
Tabla 7.4.6. 1 Clasificación atributo estrato
ESTRATO CLAS_ESTRATO
0 SIN ESTRATO
2 BAJO
3 MEDIO_BAJO
7.4.7 Atributo actividad
El atributo actividad hace referencia a las áreas de actividad, que según el POT (Plan de
Ordenamiento Territorial) establece como usos más adecuados en las diferentes zonas de la
ciudad (Alcaldía Mayor de Bogotá D.C - SDP, 2008), En la base de datos se encuentra
expresado como un atributo nominal, es presentado como ACTIVIDAD para los valores
numéricos y CLAS_ACT para los valores nominales. Su presentación numérica y nominal
para los valores presentes en las bases de datos son los contenidos en la Tabla 7.4.7.1.
Tabla 7.4.7. 1 Clasificación atributo actividad
ACTIVIDAD CLAS_ACT
1 AREA_URBANA_INT
2 COMERCIO
4 INDUSTRIAL
5 RESIDENCIAL
7.4.8 Atributo tratamiento
El atributo tratamiento hace referencia al tipo de intervención que más conviene de acuerdo
con el desarrollo del sector y los propósitos del POT (Alcaldía Mayor de Bogotá D.C -
102
SDP, 2007). En la base de datos se encuentra expresado como un atributo nominal, es
presentado como TRATAMIENTO para los valores numéricos y CLAS_TRATAM para
los valores nominales. Su presentación numérica y nominal para los valores presentes en las
bases de datos son los contenidos en la Tabla 7.4.8.1.
Tabla 7.4.8. 1 Clasificación atributo tratamiento
TRATAMIENTO CLAS_TRATAM
2 CONSOLIDACION
3 DESARROLLO
4 MEJORAMIENTO INT
5 RENOVACION_URB
7.4.9 Atributo área de terreno
El atributo área terreno se encuentra en la base de datos expresado como un atributo
numérico, está contenido únicamente en los conjuntos de datos de los predios que no están
bajo el régimen de propiedad horizontal (No_PH). Es presentado como
AREA_DE_TERRENO para los valores numéricos y CLAS_ATERRENO para los valores
nominales. Para su presentación nominal se realizaron cuatro subconjuntos y las respectivas
clasificaciones por medio del método de sturges teniendo para los intervalos las
características presentadas en la Tabla 7.4.9.1 y obteniendo los conjuntos de clasificación
como se muestran en las Tablas 7.4.9.2, 7.4.9.3 , 7.4.9.4 y 7.4.9.5.
103
Tabla 7.4.9. 1Características de la clasificación: atributo área de terreno
Grupos Características Valores
Grupo 1
L 6.92
K 14
XMIN 3
XMAX 100
Grupo 2
L 99.98
K 9
XMIN 100.1
XMAX 1000
Grupo 3
L 1499.98
K 6
XMIN 1000.1
XMAX 10000
Grupo 4
L 47499.97
K 4
XMIN 10000.1
XMAX 200000
Tabla 7.4.9. 2 Clasificación atributo área de terreno, grupo 1
Límite inferior Límite superior CLAS_ATERRENO
3 9.93 11TERR1
9.92 16.86 11TERR2
16.85 23.79 11TERR3
23.78 30.71 11TERR4
30.71 37.64 11TERR5
37.64 44.57 11TERR6
44.57 51.50 11TERR7
51.5 58.43 11TERR8
58.43 65.36 11TERR9
65.35 72.29 11TERR10
72.28 79.21 11TERR11
79.21 86.14 11TERR12
86.14 93.07 11TERR13
93.07 100.00 11TERR14
104
Tabla 7.4.9. 3 Clasificación atributo área de terreno, grupo 2
Límite inferior Límite superior CLAS_ATERRENO
100.1 200.08 12TERR1
200.08 300.07 12TERR2
300.07 400.06 12TERR3
400.06 500.05 12TERR4
500.05 600.04 12TERR5
600.04 700.03 12TERR6
700.03 800.02 12TERR7
800.02 900.01 12TERR8
900.01 1000 12TERR9
Tabla 7.4.9. 4 Clasificación atributo área de terreno, grupo 3
Límite inferior Límite superior CLAS_ATERRENO
1000.1 2500.08 13TERR1
2500.08 4000.06 13TERR2
4000.06 5500.05 13TERR3
5500.05 7000.03 13TERR4
7000.03 8500.01 13TERR5
8500.01 10000 13TERR6
Tabla 7.4.9. 5 Clasificación atributo área de terreno, grupo 4
Límite inferior Límite superior CLAS_ATERRENO
10000.1 57500.075 14TERR1
57500.075 105000.05 14TERR2
105000.05 152500.025 14TERR3
152500.025 200000 14TERR4
7.4.10 Atributo valor metro cuadrado de terreno
El atributo valor metro cuadrado de terreno se encuentra en la base de datos expresado
como un atributo numérico, está contenido únicamente en los conjuntos de datos de los
105
predios que no están bajo el régimen de propiedad horizontal (No_PH). Es presentado
como VALOR_M2_TERRENO para los valores numéricos y CLAS_VALM2TERRENO
para los valores nominales. Para su presentación nominal se clasificó por medio del método
de sturges teniendo para los intervalos las características presentadas en la Tabla 7.4.10.1 y
obteniendo el conjunto de clasificación como se muestran en las Tablas 7.4.10.2.
Tabla 7.4.10. 1 Características de la clasificación: atributo valor metro cuadrado de terreno
Características Valores
L 60000
K 15
XMIN 100000
XMAX 1000000
Tabla 7.4.10. 2 Clasificación atributo valor metro cuadrado de terreno
Límite inferior Límite superior CLAS_VALM2TERRENO
100000 160000 11VAL_M2TERR1
160000 220000 11VAL_M2TERR2
220000 280000 11VAL_M2TERR3
280000 340000 11VAL_M2TERR4
340000 400000 11VAL_M2TERR5
400000 460000 11VAL_M2TERR6
460000 520000 11VAL_M2TERR7
520000 580000 11VAL_M2TERR8
580000 640000 11VAL_M2TERR9
640000 700000 11VAL_M2TERR10
700000 760000 11VAL_M2TERR11
760000 820000 11VAL_M2TERR12
820000 880000 11VAL_M2TERR13
880000 940000 11VAL_M2TERR14
940000 1000000 11VAL_M2TERR15
106
7.4.11 Atributo área construida
El atributo área construida se encuentra en la base de datos expresado como un atributo
numérico. Es presentado como AREA_CONSTRUIDA para los valores numéricos y
CLAS_ACONS para los valores nominales. Para su presentación nominal se realizaron
cuatro subconjuntos y las respectivas clasificaciones por medio del método de sturges
teniendo para los intervalos las características presentadas en la Tabla 7.4.11.1 y obteniendo
los conjuntos de clasificación como se muestran en las Tablas 7.4.11.2, 7.4.11.3, 7.4.11.4 y
7.4.11.5.
Tabla 7.4.11. 1 Características de la clasificación: atributo área construida
Grupos Características Valores
Grupo 1 Valor único 0
Grupo 2
L 66.6
K 15
XMIN 1
XMAX 1000
Grupo 3
L 1499.83
K 6
XMIN 1001
XMAX 10000
Grupo 4
L 4666.33
K 3
XMIN 10001
XMAX 24000
Tabla 7.4.11. 2 Clasificación atributo área construida, grupo 1
Valor CLAS_ACONS
0 11ACONS0
107
Tabla 7.4.11. 3 Clasificación atributo área construida, grupo 2
Límite inferior Límite superior CLAS_ACONS
1.0 67.6 12ACONS1
67.6 134.2 12ACONS2
134.2 200.8 12ACONS3
200.8 267.4 12ACONS4
267.4 334.0 12ACONS5
334.0 400.6 12ACONS6
400.6 467.2 12ACONS7
467.2 533.8 12ACONS8
533.8 600.4 12ACONS9
600.4 667.0 12ACONS10
667.0 733.6 12ACONS11
733.6 800.2 12ACONS12
800.2 866.8 12ACONS13
866.8 933.4 12ACONS14
933.4 1000.0 12ACONS15
Tabla 7.4.11. 4 Clasificación atributo área construida, grupo 3
Límite inferior Límite superior CLAS_ACONS
1001 2500.83 13ACONS1
2500.83 4000.66 13ACONS2
4000.66 5500.5 13ACONS3
5500.5 7000.33 13ACONS4
7000.33 8500.16 13ACONS5
8500.16 10000 13ACONS6
Tabla 7.4.11. 5 Clasificación atributo área construida, grupo 4
Límite inferior Límite superior CLAS_ACONS
10001 14667.33 14ACONS1
14667.33 19333.66 14ACONS2
19333.66 24000 14ACONS3
108
7.4.12 Atributo valor metro cuadrado de construcción
El atributo valor metro cuadrado de construcción se encuentra en la base de datos
expresado como un atributo numérico. Es presentado como
VALOR_M2_CONSTRUCCION para los valores numéricos y CLAS_VAL_M2CONS
para los valores nominales. Para su presentación nominal se realizaron dos clasificaciones,
una de ellas por medio del método de sturges teniendo para el intervalo las características
presentadas en la Tabla 7.4.12.1 y obteniendo dos conjuntos de clasificación como se
muestran en la Tabla 7.4.12.2 y 7.4.12.3.
Tabla 7.4.12. 1 Características de la clasificación: valor metro cuadrado de construcción
Grupos Características Valores
Grupo 1 Valor único 0
Grupo 2
L 130666.66
K 15
XMIN 40000
XMAX 2000000
Tabla 7.4.12. 2 Clasificación atributo valor metro cuadrado de construcción, grupo 1
Valor CLAS_ACONS
0 11VAL_M2CONS0
109
Tabla 7.4.12. 3 Clasificación atributo valor metro cuadrado de construcción, grupo 2
Límite inferior Límite superior CLAS_ACONS
40000.00 170666.67 12VAL_M2CONS1
170666.67 301333.33 12VAL_M2CONS2
301333.33 432000.00 12VAL_M2CONS3
432000.00 562666.67 12VAL_M2CONS4
562666.67 693333.33 12VAL_M2CONS5
693333.33 824000.00 12VAL_M2CONS6
824000.00 954666.67 12VAL_M2CONS7
954666.67 1085333.33 12VAL_M2CONS8
1085333.33 1216000.00 12VAL_M2CONS9
1216000.00 1346666.67 12VAL_M2CONS10
1346666.67 1477333.33 12VAL_M2CONS11
1477333.33 1608000.00 12VAL_M2CONS12
1608000.00 1738666.67 12VAL_M2CONS13
1738666.67 1869333.33 12VAL_M2CONS14
1869333.33 2000000.00 12VAL_M2CONS15
7.4.13 Generación archivos weka
Con el fin de procesar las bases de datos, luego de ser divididas por el atributo de
pertenecer o no al régimen de propiedad horizontal (PH) y organizar cada conjunto de
atributos para contar con expresiones numéricas y nominales de cada uno, se procedio a
organizar cada conjunto de datos en formato .arff obteniendo en total 8 conjuntos de datos
por cada UPZ, tal como se presenta en la figura 7.4.1, denominados conjuntos de datos para
entrenamiento y validación y conjunto de datos para pronóstico, tanto para PH como para
No PH y de cada uno nominales y numéricos. Los archivos son nombrados y cuentan con
las cantidades de datos como se presenta en las Tablas 7.4.13.1, 7.4.13.2 y 7.4.13.3.


































































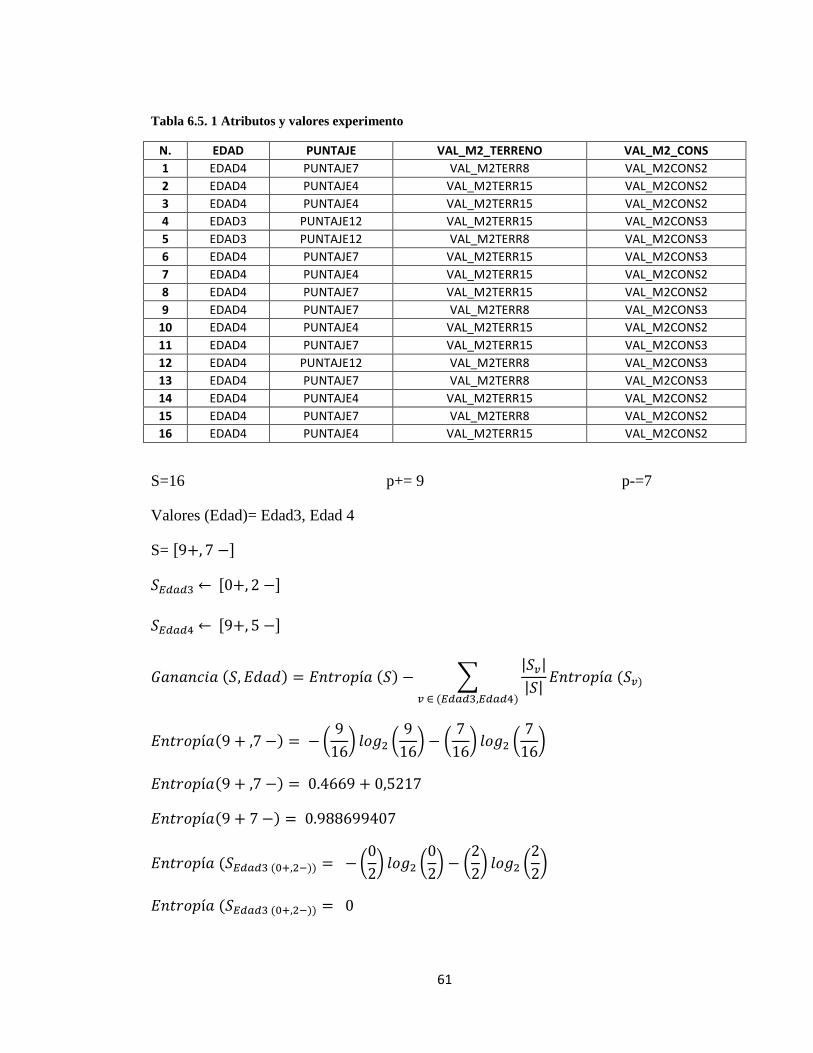

























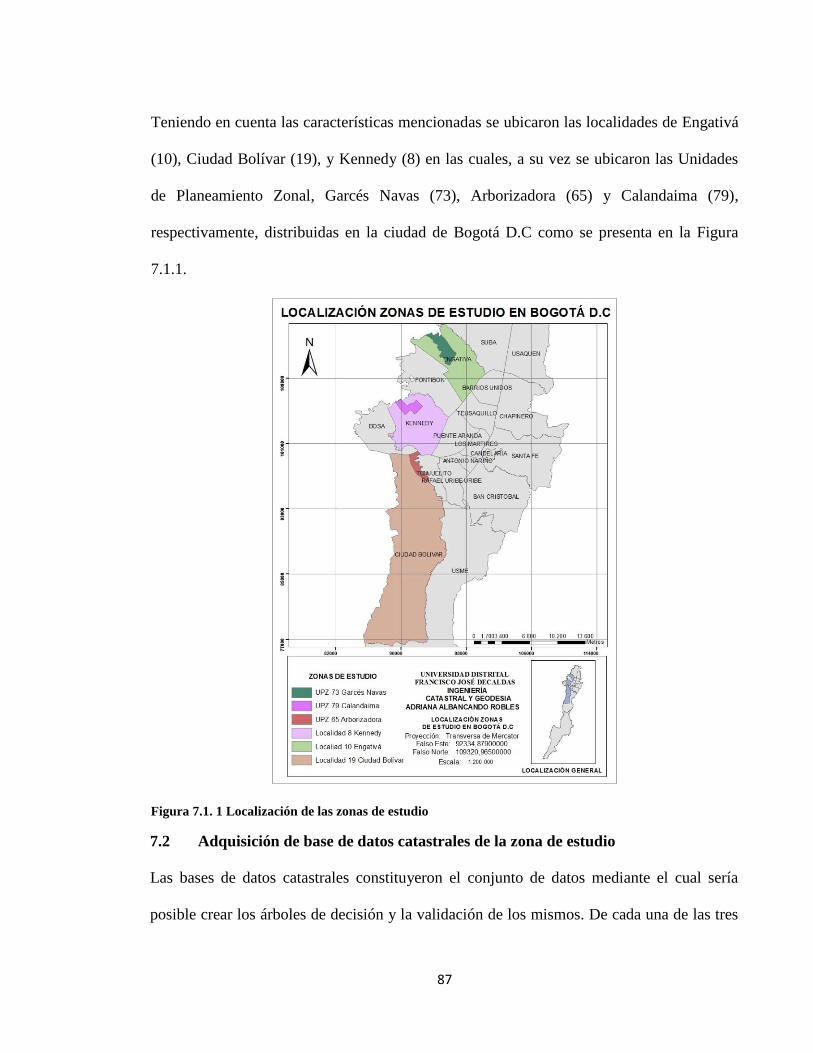























































































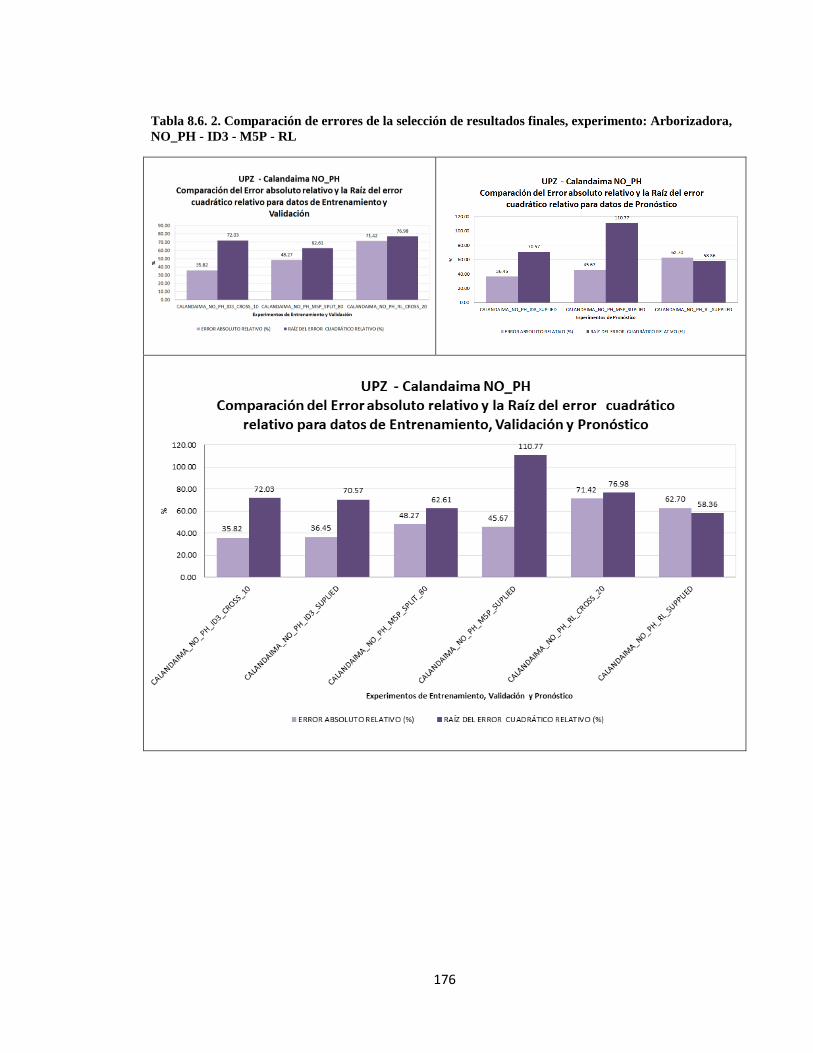



























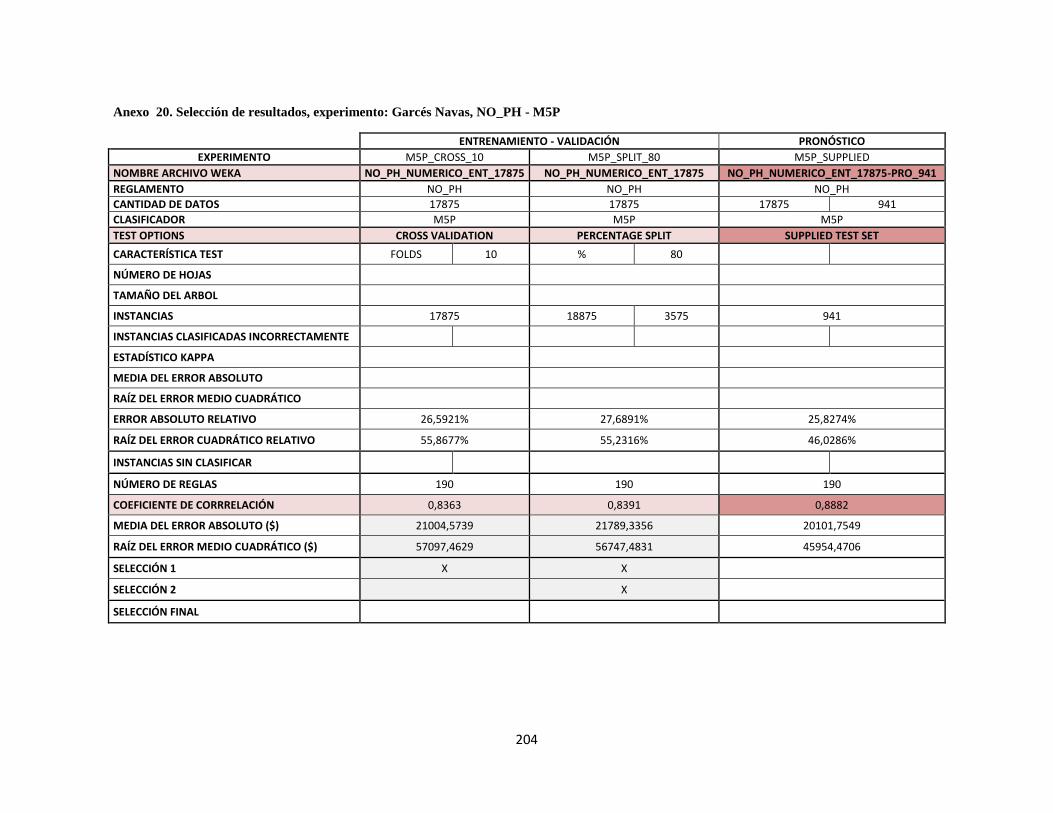

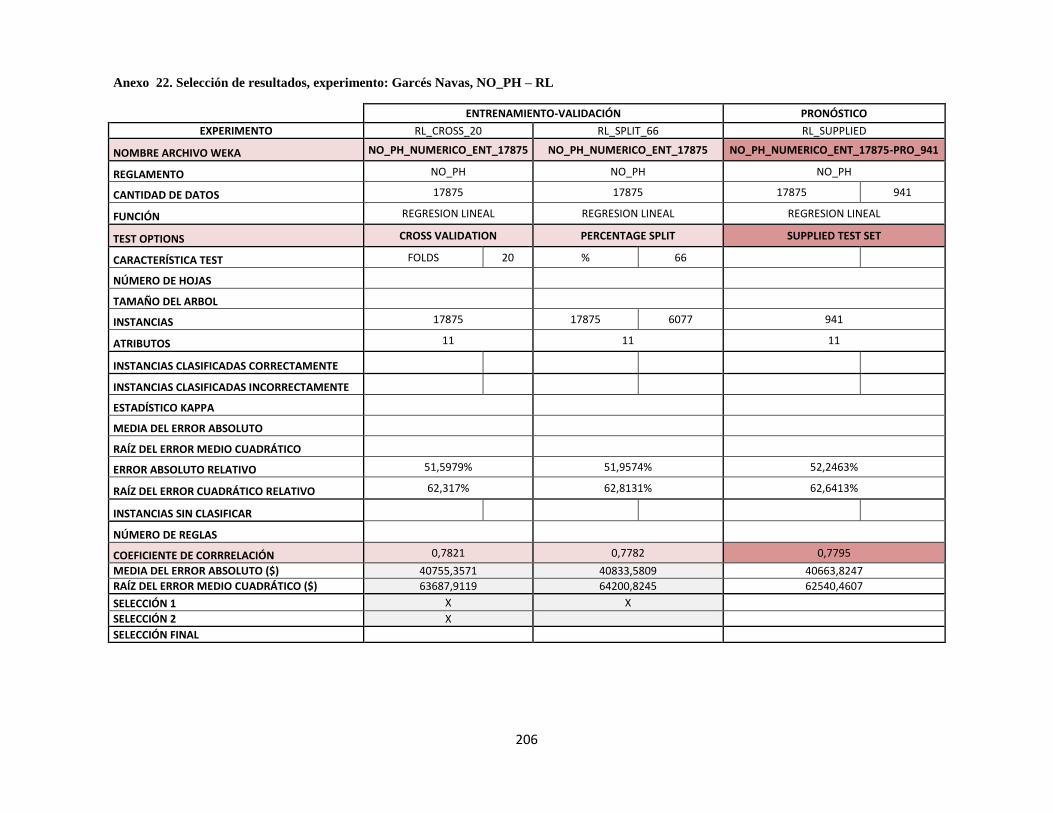







































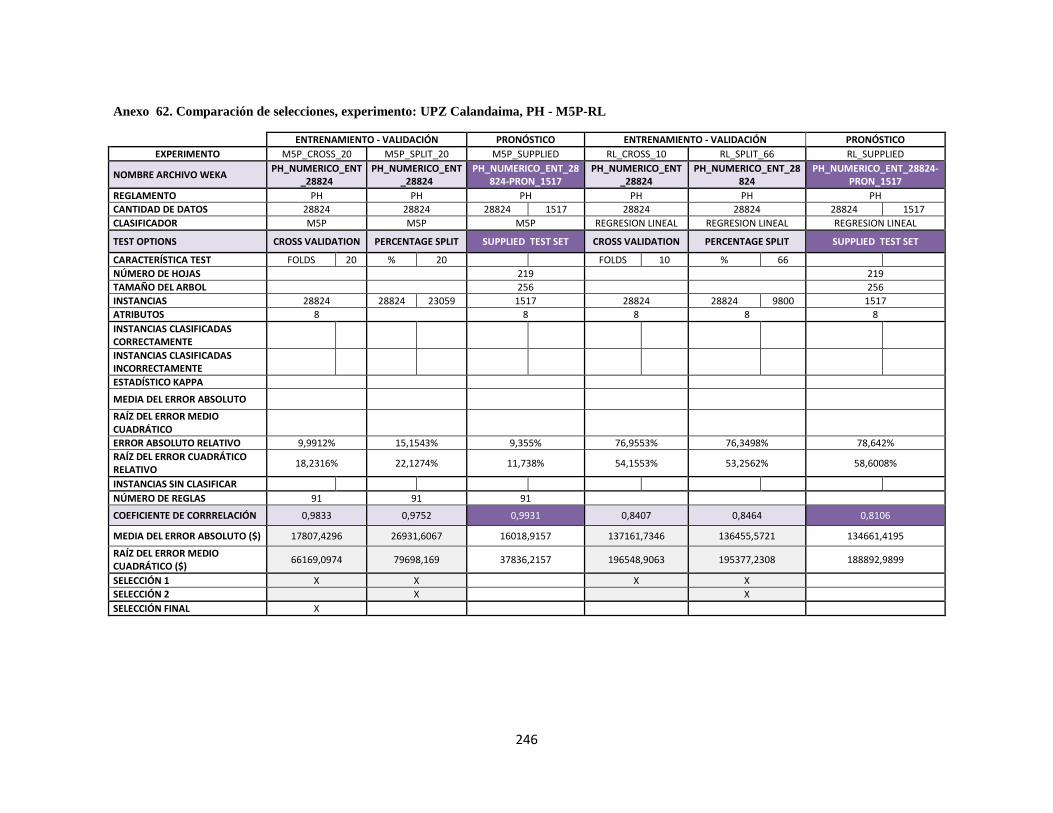














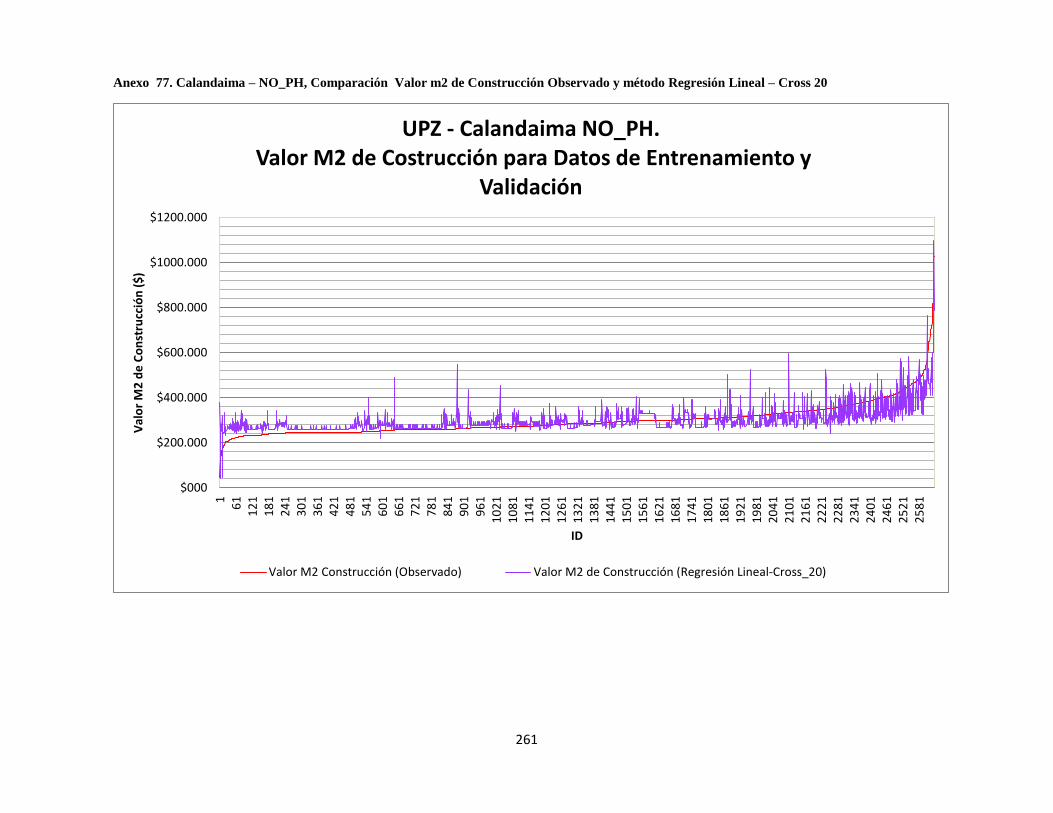















![2016 07 rp4_claves_para_mejora_de_la_prescripcion[5779]](https://static.documentos.tech/doc/80x56/5a6d31e87f8b9a04428b4f01/2016-07-rp4clavesparamejoradelaprescripcion5779.jpg)









