Page 1
Ingeniería en Informática
Tesis de Grado
Prototipo de Sistema de Inteligencia de Negocios
utilizando
Minería de Datos sobre Software Libre
Nicolás Chávez
Christian Bavera
Tutor: Lic. Denise Riveros
Asunción – Paraguay
2.013
Page 2
RESUMEN
El propósito de este proyecto fue demostrar la factibilidad de la realización de un
prototipo de solución de Inteligencia de Negocios basado en software libre y
minería de datos, enfocado a dar soporte a la toma de decisiones estratégicas del
Grupo Flayp, ya que sus empresas almacenan sus datos en fuentes y formatos
diferentes. Para ello se relevaron los sistemas actuales,procesos, requerimientos y
tecnologías vigentes. Logrando la concreción del prototipo, utilizando para ello
las herramientas disponibles bajo licencia de software libre. Evidenciando que
estas herramientas, son una alternativa válida para soluciones de este tipo, sin la
necesidad de incurrir en gastos por el pago de licencias de software propietario.
Palabras Claves: inteligencia de negocios, software libre, minería de datos.
Page 3
DEDICATORIA
Dedico este esfuerzo personal y este logro académico y profesional:
A mis padres Nicolás y María del Carmen, quienes con su ejemplo me
enseñaron que todo es posible si uno se propone, sin ellos, jamás hubiese podido
conseguir este objetivo
A mis hermanos, compañeros de clases y amigos, porque de ellos también
he aprendido.
Nicolás Chavez Espínola
A mis padres, porque siempre creyeron en mí y porque me sacaron
adelante, dándome ejemplos dignos de superación y entrega, porque en gran parte
gracias a ustedes, hoy puedo ver alcanzada mí meta.
A mi familia, por ser soporte fundamental en las etapas complicadas, que
fueron muchas.
A mi novia, por comprenderme y apoyarme siempre y en todo momento.
A mis compañeros de la facultad, que compartieron esta carrera que por
momentos parecía infinita.
A todos, espero no defraudarlos y contar siempre con su valioso apoyo,
sincero e incondicional.
Todo este trabajo ha sido posible gracias a ellos.
Christian Bavera
Page 4
AGRADECIMIENTOS
Primero antes que nada, damos gracias a Dios, por estar con nosotros en
cada paso que dimos, por fortalecer nuestros corazones e iluminar nuestras mentes
y haber puesto en nuestro camino a aquellas personas que han sido soporte y
compañía durante todo el periodo de estudio.
A nuestros profesores quienes nos han enseñado a ser mejores en la vida y
a realizarnos profesionalmente.
Un agradecimiento especial a nuestra asesora la Lic. Denise Riveros por
hacer posible esta tesis.
A los compañeros de clases quienes nos acompañaron en esta trayectoria
de aprendizaje y conocimientos.
Al Grupo Flayp, por permitirnos realizar este proyecto, poniéndose a
nuestra disposición y brindándonos todas las facilidades desde el primer al último
día en que así lo requerimos
En general quisiéramos agradecer a todas y cada una de las personas que
han vivido con nosotros la realización de esta tesis.
Page 5
ÍNDICE
CAPITULO 1 - INTRODUCCIÓN ..................................................................... 13
1.1. Planteamiento del Problema ................................................................... 13
1.2. Necesidad de estudiar el problema. ........................................................ 14
1.3. Significación del problema ..................................................................... 14
1.4. Delimitación del problema ...................................................................... 14
1.5. Objetivos de la Tesis: .............................................................................. 15
1.5.1. Objetivo General ............................................................................. 15
1.5.2. Objetivos Específicos ...................................................................... 15
1.6. Definición de términos ............................................................................ 16
1.7. Presentación del esquema ....................................................................... 17
CAPITULO 2–MARCO TEÓRICO ..................................................................... 19
2.1. El valor de la información....................................................................... 19
2.2. Necesidad de información y conocimiento en la empresa ...................... 20
2.3. La información que las empresas necesitan ............................................ 21
2.4. Las organizaciones y los distintos sistemas de información ................... 24
2.5. Definición de Inteligencia de Negocios .................................................. 26
2.6. Los usuarios de las soluciones de Inteligencia de Negocios................... 27
2.7. Historia de la Inteligencia de Negocios .................................................. 28
2.8. Características de la Inteligencia de Negocios ........................................ 30
2.9. Componentes de una solución de Inteligencias de Negocios ................. 31
2.9.1. Las fuentes de información a las que se puede acceder son: .......... 32
2.9.2. Proceso de extracción, transformación y carga ............................... 33
2.9.3. Data warehouse............................................................................... 35
2.9.4. Herramientas de acceso de la Inteligencia de Negocios ................. 40
2.10. Principales herramientas de la Inteligencia de Negocios ........................ 42
2.11. Minería de datos ...................................................................................... 43
2.11.1. Conceptos e historia de la minería de datos ................................ 43
2.11.2. Los fundamentos de la minería de datos. .................................... 45
2.11.3. Objetivos de la minería de datos ................................................. 45
2.11.4. Entorno de la minería de datos .................................................... 46
2.11.5. El alcance de la minería de datos ................................................ 47
2.12. Reseña histórica del Grupo Flayp ........................................................... 47
2.13. Reseña histórica del software libre ......................................................... 50
Page 6
2.13.1. Richard Stallman y el proyecto GNU .......................................... 50
2.13.2. Software Libre ............................................................................. 52
2.13.3. Libertades básicas del software libre ........................................... 54
2.13.4. Software libre y software de código abierto ................................ 55
2.13.5. Tipos de licencias de software libre ............................................. 58
CAPÍTULO 3– MARCO METODOLÓGICO ..................................................... 60
3.1. Descripción de la profundidad y el diseño de la Tesis: ........................... 60
3.2. Descripción de cómo se realizó la Tesis ................................................. 61
3.2.1. Relevamiento de datos .................................................................... 62
3.2.2. Análisis de datos ............................................................................. 62
3.2.3. Diseño ............................................................................................. 63
3.2.4. Desarrollo ........................................................................................ 64
3.2.5. Prueba .............................................................................................. 65
3.2.6. Implementación ............................................................................... 65
3.3. Descripción de los instrumentos y procedimientos utilizados para la
recolección y tratamiento de la información ..................................................... 66
3.4. Descripción de la muestra ....................................................................... 66
3.5. Relevamiento .......................................................................................... 67
3.5.1. Relevamiento de procesos ............................................................... 67
3.5.2. Relevamiento de Estructura de Datos ............................................. 71
3.5.3. Relevamiento de Necesidades ......................................................... 71
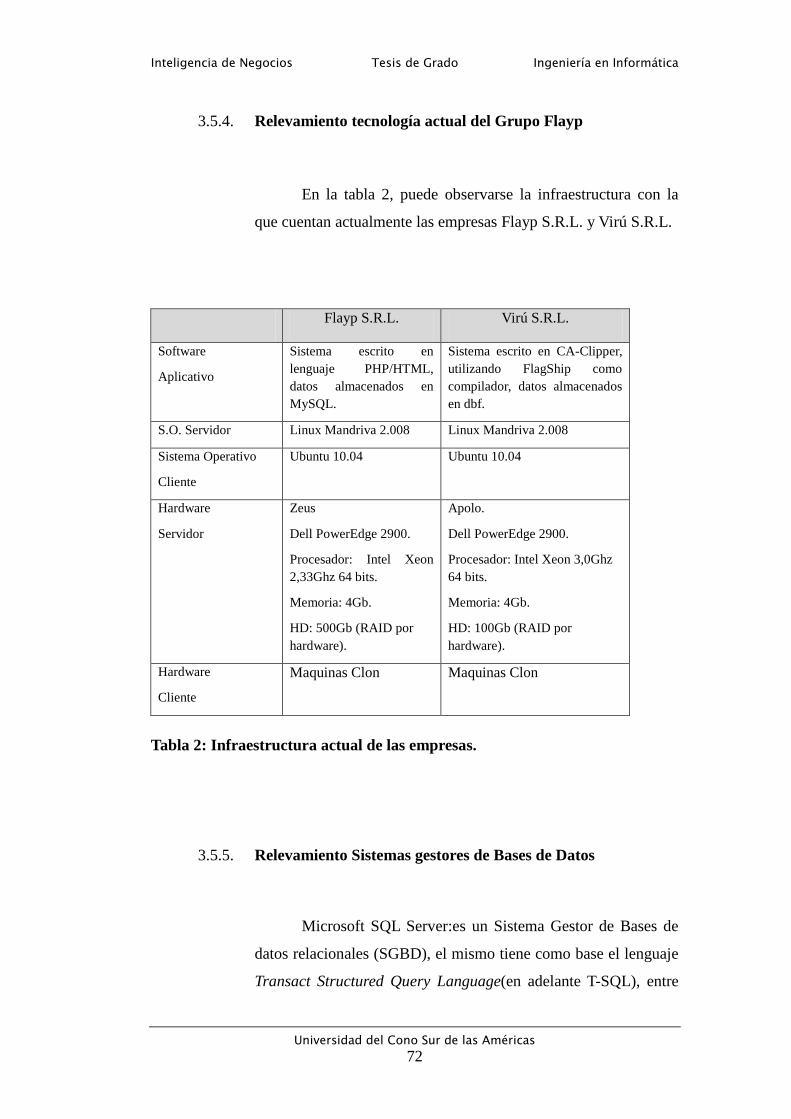
3.5.4. Relevamiento tecnología actual del Grupo Flayp ........................... 72
3.5.5. Relevamiento Sistemas gestores de Bases de Datos ....................... 72
3.5.6. Relevamiento algoritmo de minería de datos .................................. 75
3.5.7. Relevamiento de sistemas operativos ............................................. 78
3.5.8. Relevamiento de herramientas de Inteligencia de Negocios........... 79
3.6. Análisis ................................................................................................... 81
3.6.1. Análisis de requerimientos .............................................................. 81
3.6.2. Análisis de procesos ........................................................................ 83
3.6.3. Análisis de estructura de datos ........................................................ 84
3.6.4. Análisis de herramientas de Inteligencia de Negocios .................... 85
3.6.5. Análisis de sistemas gestores de bases de datos.............................. 86
3.6.6. Análisis de tecnología actual del Grupo Flayp ............................... 87
3.6.7. Análisis de algoritmo de minería de datos ...................................... 87
3.6.8. Análisis de sistemas operativos ....................................................... 88
3.6.9. Análisis de factibilidad económica ................................................. 90
Page 7
3.7. Diseño ..................................................................................................... 91
3.7.1. Diseño del data warehouse ............................................................. 91
3.7.2. Diseño del proceso ETL .................................................................. 93
3.7.3. Diseño de reportes ........................................................................... 98
3.7.4. Diseño de cubos multidimensionales ............................................ 101
3.7.5. Diseño de cuadros de mandos ....................................................... 105
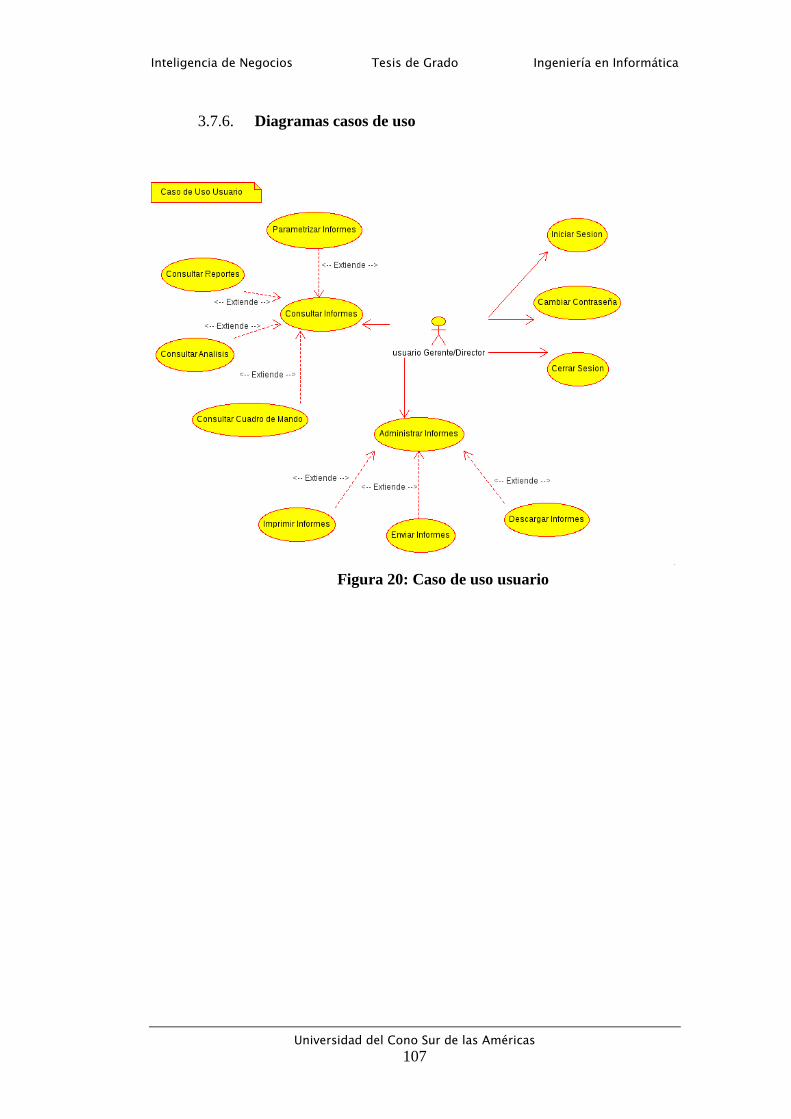
3.7.6. Diagramas casos de uso ................................................................ 107
3.7.7. Diagrama de actividades ................................................................ 110
3.7.8. Diagramas de secuencia ................................................................. 112
3.7.9. Diagrama de arquitectura de Pentaho Open BI Suite ..................... 114
3.7.10. Arquitectura del prototipo de solución de Inteligencia de
Negocios. 116
3.8. Desarrollo del prototipo ......................................................................... 117
3.8.1. Desarrollo del data warehouse ....................................................... 117
3.8.2. Desarrollo de proceso ETL ............................................................ 118
3.8.3. Desarrollo de minería de datos ...................................................... 125
3.8.4. Desarrollo de reportes ................................................................... 127
3.8.5. Desarrollo de cubos multidimensionales ...................................... 130
3.8.6. Desarrollo de cuadros de mandos ................................................. 133
3.9. Prueba de prototipo ............................................................................... 136
3.10. Implementación del Prototipo ............................................................... 143
3.10.1. Implementación de ETL y Data warehouse .............................. 143
3.10.2. Implementación de Pentaho Open BI Server ............................ 144
3.10.3. Implementación de consola de administración de usuarios Pentaho
148
3.10.4. Implementación de reportes ...................................................... 150
3.10.5. Implementación de los cubos multidimensionales .................... 152
3.10.6. Implementación de cuadros de mandos ..................................... 153
CAPÍTULO 4– RESULTADOS .......................................................................... 154
CAPÍTULO 5 - CONCLUSIONES ................................................................... 155
CAPÍTULO 6- RECOMENDACIONES ........................................................... 156
BIBLIOGRAFÍA ................................................................................................ 157
ANEXOS ............................................................................................................ 159
Page 8
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 8
LISTA DE TABLAS
Tabla 1: Diferencias entre sistemas OLTP y OLAP. ............................................. 39
Tabla 2: Infraestructura actual de las empresas. .................................................... 72
Tabla 3: Datos de ejemplo ..................................................................................... 77
Tabla 4: Descripción del algoritmo backpropagation ........................................... 77
Tabla 5: Comparativa herramientas de Inteligencia de Negocios ......................... 85
Tabla 6: Comparativa de SGBD ............................................................................ 86
Tabla 7: Comparativa de algoritmos de minería de datos. .................................... 88
Tabla 8: Comparativa de sistemas operativos ....................................................... 89
Tabla 9: Cuadro de costos ..................................................................................... 90
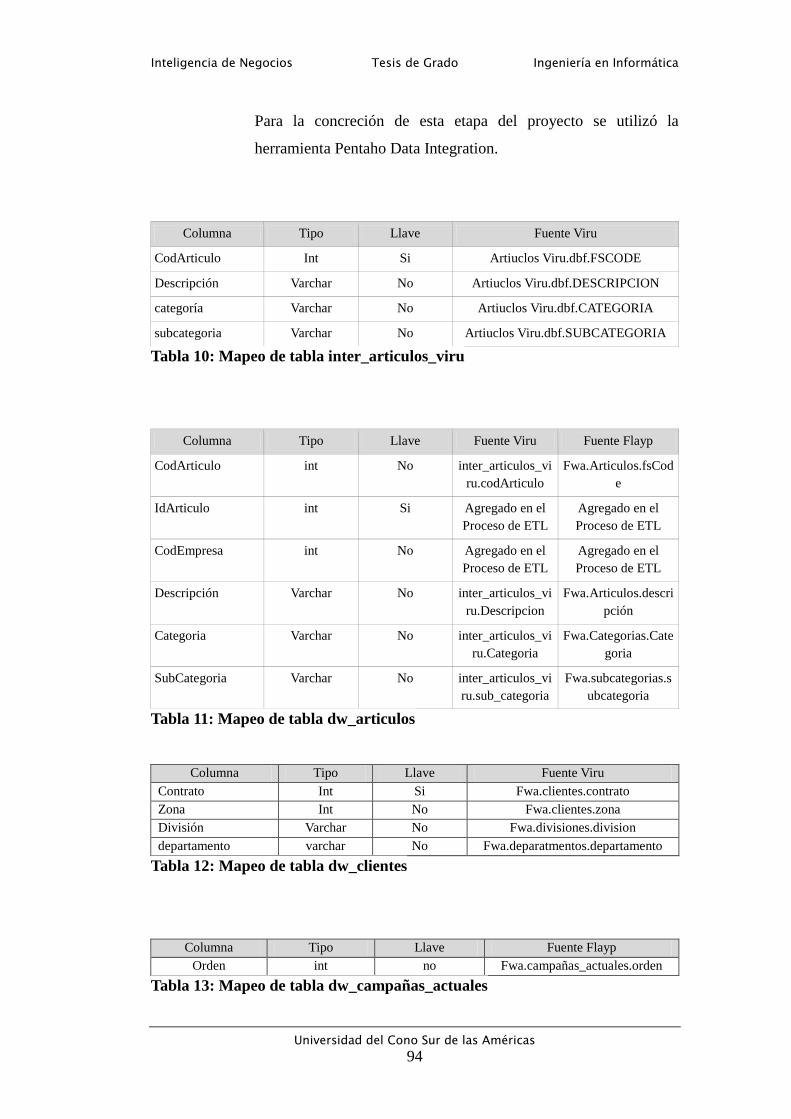
Tabla 10: Mapeo de tabla inter_articulos_viru ...................................................... 94
Tabla 11: Mapeo de tabla dw_articulos ................................................................. 94
Tabla 12: Mapeo de tabla dw_clientes .................................................................. 94
Tabla 13: Mapeo de tabla dw_campañas_actuales ................................................ 94
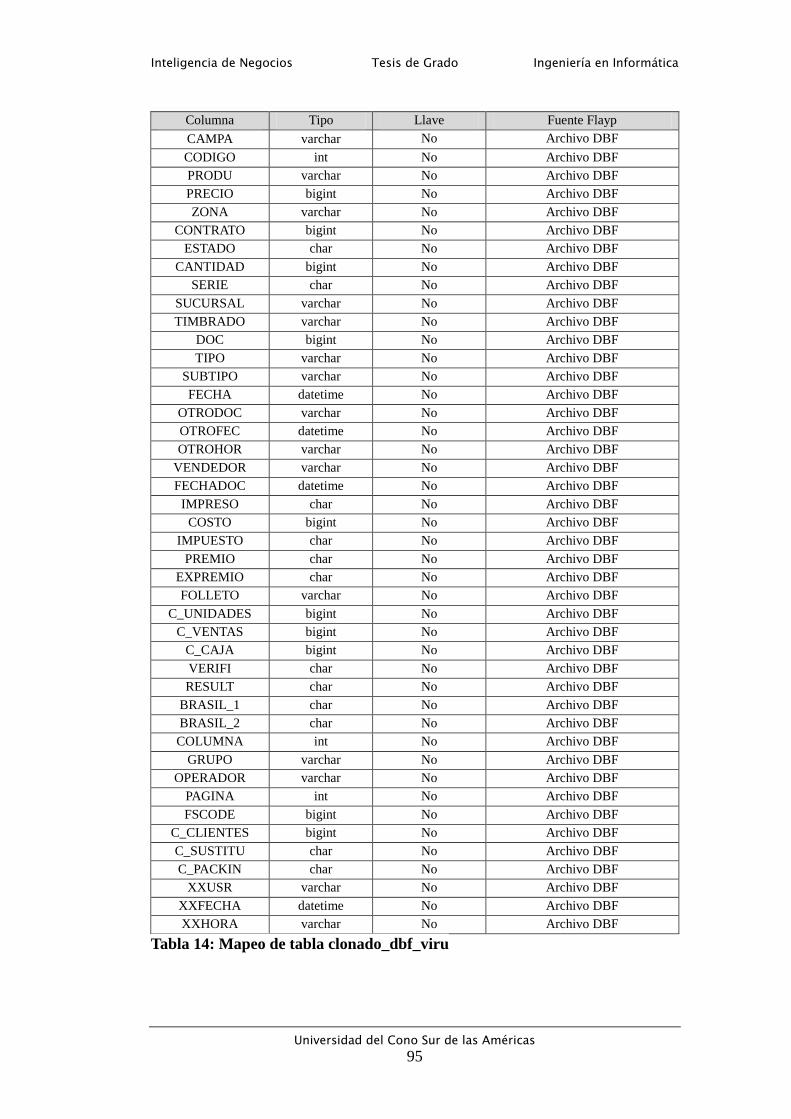
Tabla 14: Mapeo de tabla clonado_dbf_viru ......................................................... 95
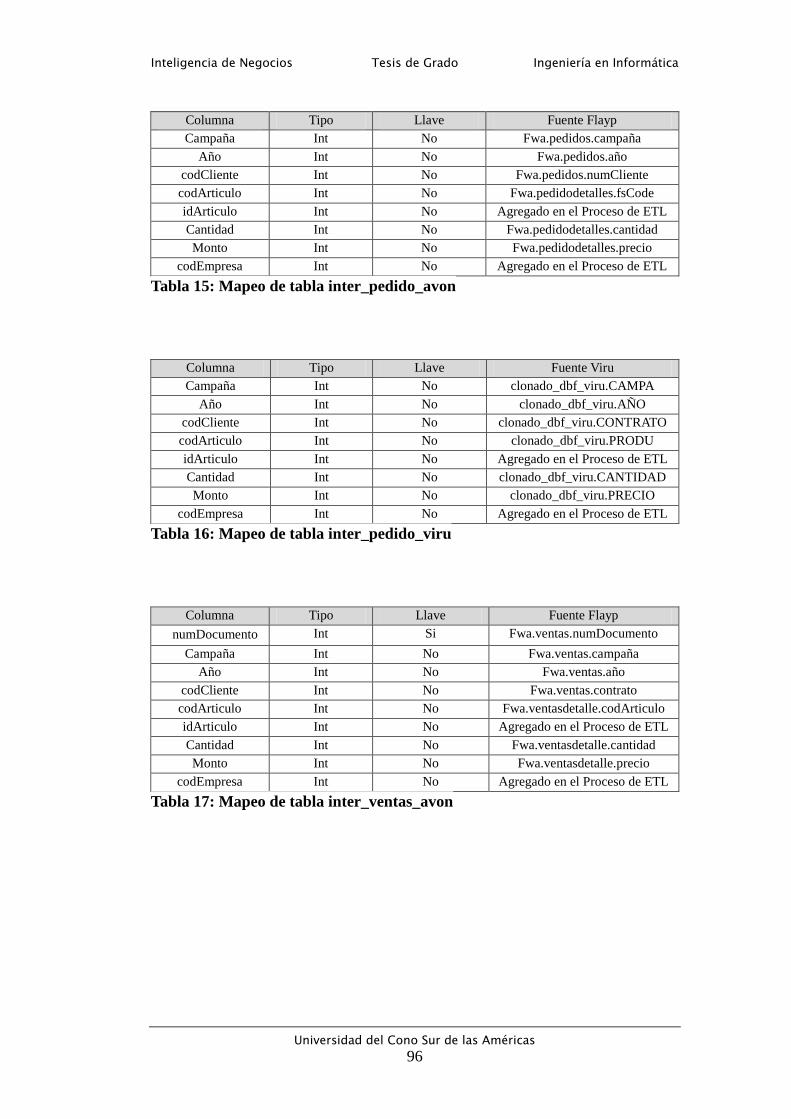
Tabla 15: Mapeo de tabla inter_pedido_avon ....................................................... 96
Tabla 16: Mapeo de tabla inter_pedido_viru ........................................................ 96
Tabla 17: Mapeo de tabla inter_ventas_avon ........................................................ 96
Tabla 18: Mapeo de tabla inter_ventas_viru ......................................................... 97
Tabla 19: Mapeo de tabla dw_hechosventas ......................................................... 97
Tabla 20: Mapeo de tabla dw_hechospedidos ....................................................... 98
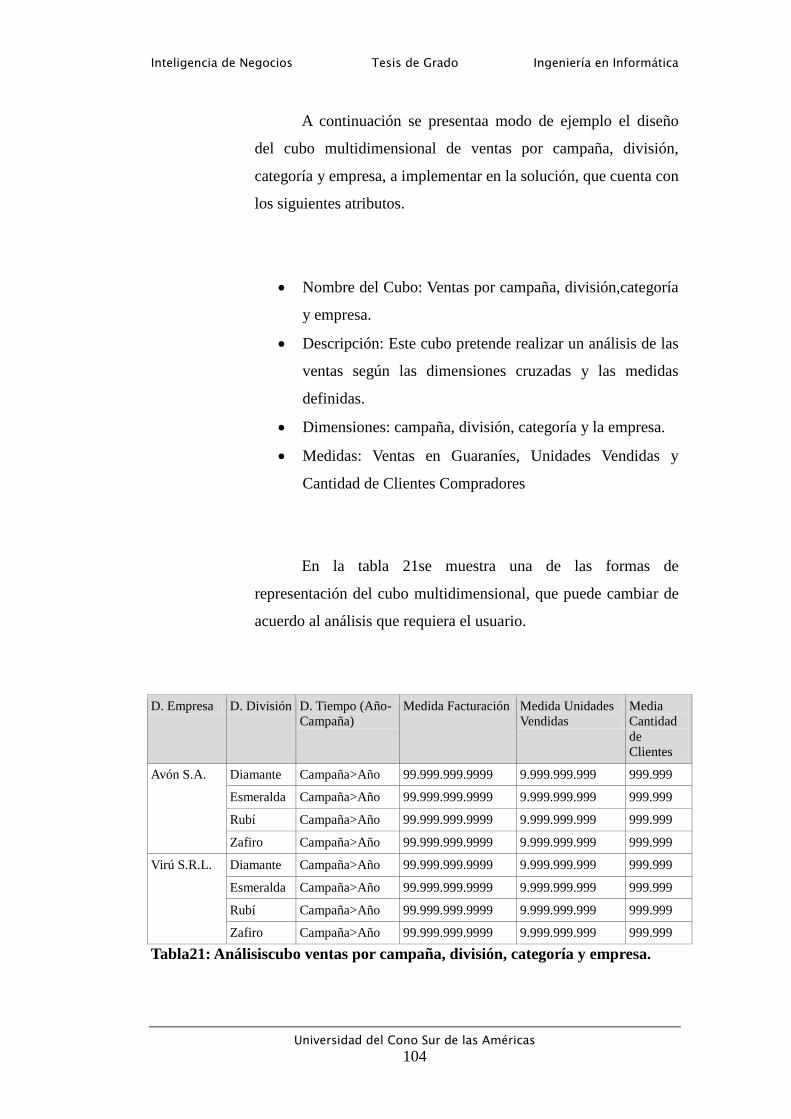
Tabla 21: Análisis cubo ventas por campaña, división, categoría y empresa. .... 104
Page 9
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 9
LISTA DE FIGURAS
Figura 1: Pirámide de usuarios de un sistema de Inteligencia de Negocios ......... 28
Figura 2: Componentes de Inteligencia de Negocios ............................................ 31
Figura 3: Fuentes de información. ........................................................................ 33
Figura 4: Data warehouse ..................................................................................... 36
Figura 5: Data marts ............................................................................................. 38
Figura 6: Herramientas de acceso. ........................................................................ 40
Figura 7: DER Hechos Pedidos............................................................................. 92
Figura 8: DER Hechos Ventas. .............................................................................. 93
Figura 9: DER Proyección .................................................................................... 93
Figura 10: Ventas por campañas por zonas ........................................................... 99
Figura 11: Reporte proyección de ventas ............................................................ 100
Figura 12: Dimensión artículos ........................................................................... 101
Figura 13: Dimensión campaña .......................................................................... 102
Figura 14: Dimensión clientes ............................................................................ 102
Figura 15: Dimensión campaña .......................................................................... 103
Figura 16: Hechos pedidos .................................................................................. 103
Figura 17: Hechos Ventas .................................................................................... 103
Figura 18: Estructura del cuadro de mando ........................................................ 105
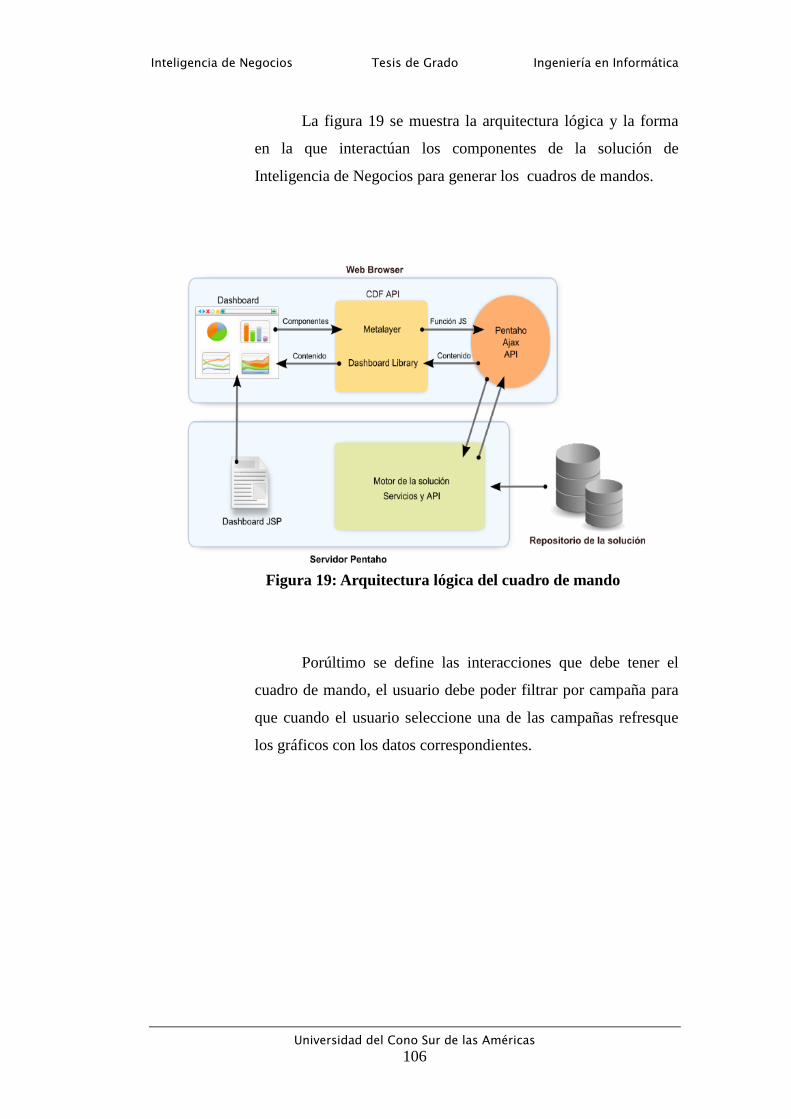
Figura 19: Arquitectura lógica del cuadro de mando .......................................... 106
Figura 20: Caso de uso usuario ........................................................................... 107
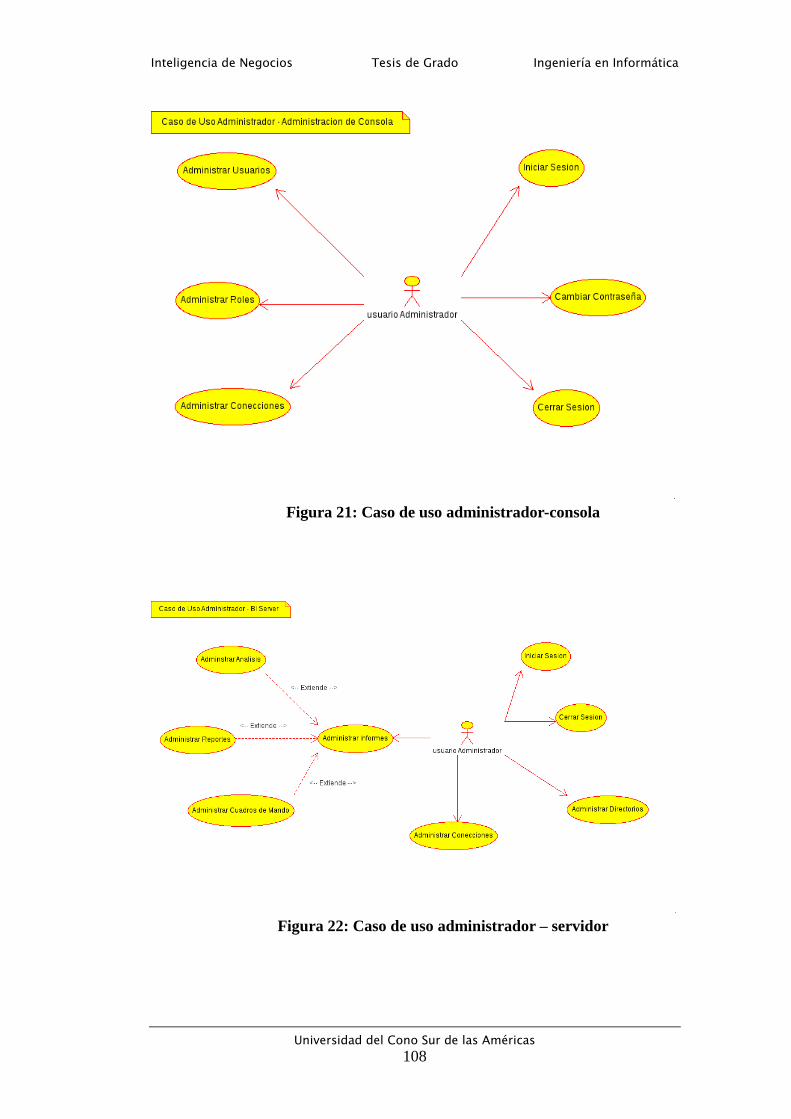
Figura 21: Caso de uso administrador-consola ................................................... 108
Figura 22: Caso de uso administrador – servidor ............................................... 108
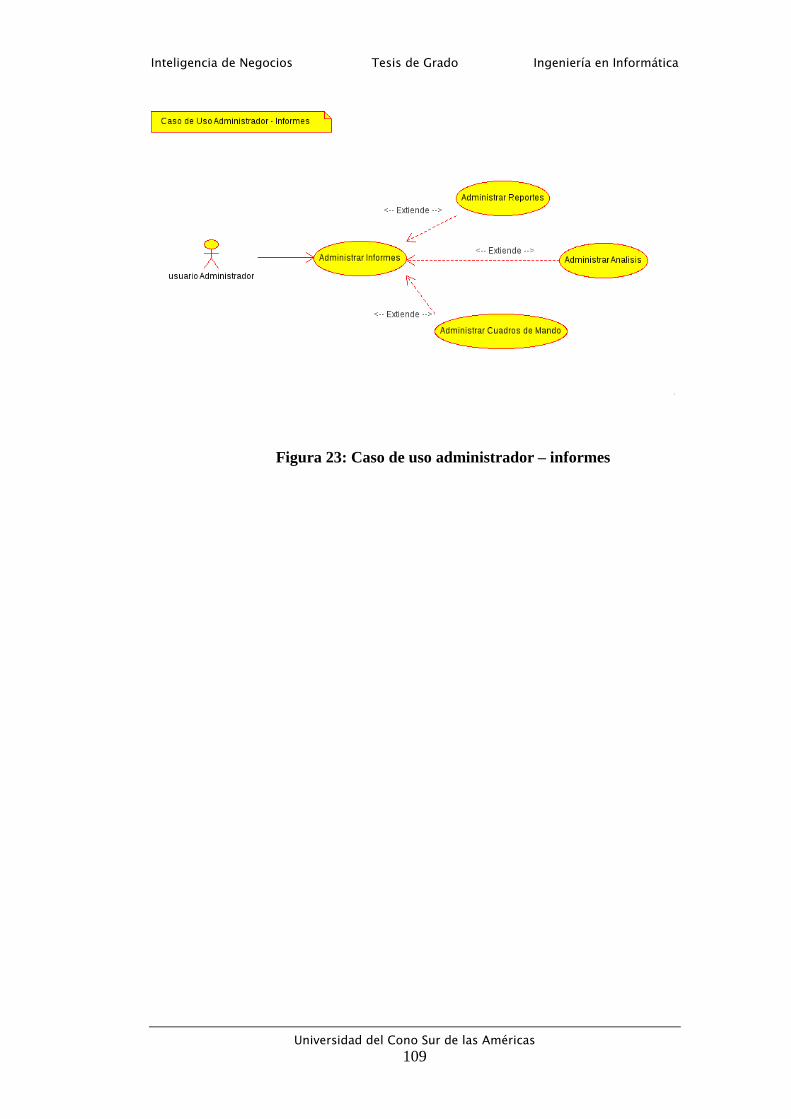
Figura 23: Caso de uso administrador – informes .............................................. 109
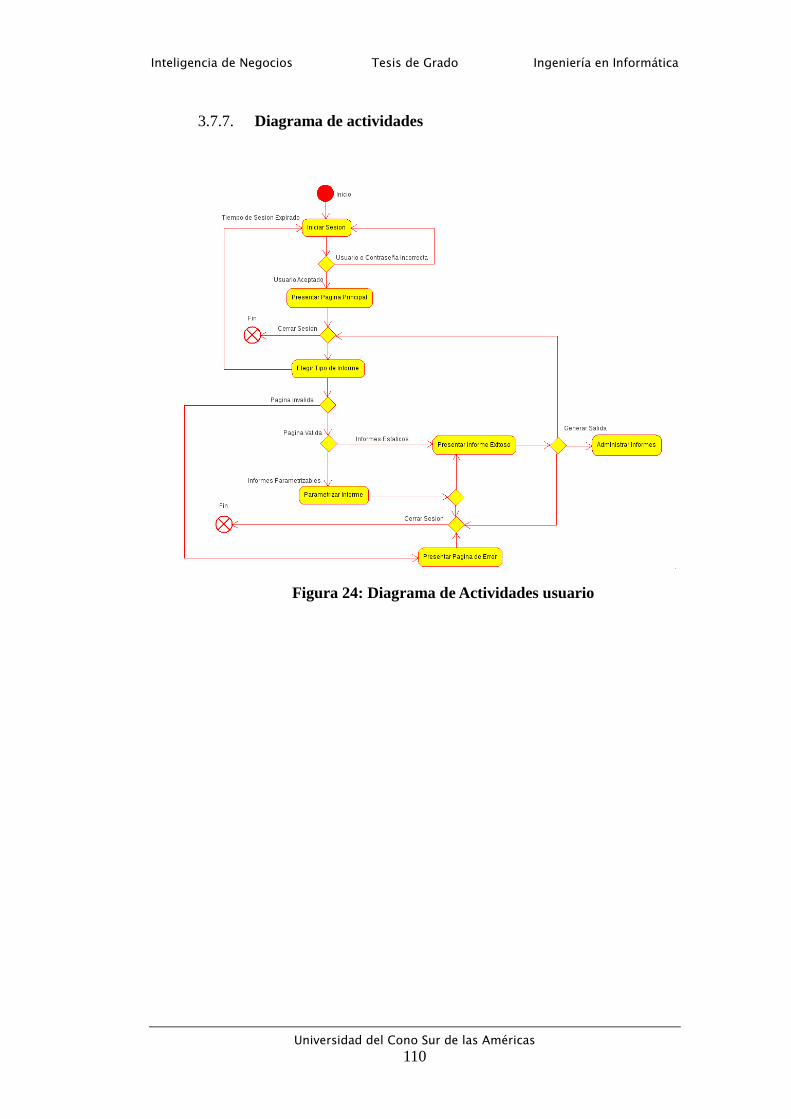
Figura 24: Diagrama de Actividades usuario ....................................................... 110
Figura 25: Diagrama de actividades administrador - usuarios ............................. 111
Figura 26: Diagrama de actividades administrador - servidor ............................. 111
Figura 27: Diagrama de actividades administrador – informes ........................... 112
Figura 28: Diagrama de secuencia – consulta de reporte y cubo ......................... 113
Figura 29: Diagrama de secuencia crear usuario ................................................. 113
Figura 30: Diagrama de secuencia administrar prototipo .................................... 114
Figura 31: Arquitectura Pentaho Open BI Suite .................................................. 115
Figura 32: Arquitectura de Inteligencia de Negocios ........................................... 117
Figura 33: Data warehouse en PhpMyAdmin ..................................................... 118
Page 10
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 10
Figura 34: Transformación selección de campaña a cargar ................................. 119
Figura 35: Transformación inter_ventas_viru ..................................................... 120
Figura 36: Transformación limpieza de clonado_dbf_viru ................................. 120
Figura 37: Transformación borrado hechos_ventas viru ..................................... 121
Figura 38: Transformación cargado de tabla hechos_ventas_viru ...................... 121
Figura 39: Trabajo general de cargado dw_hechosventas fuente Viru ................ 122
Figura 40: Transformación cargado de tabla inter_ventas_avon ........................ 123
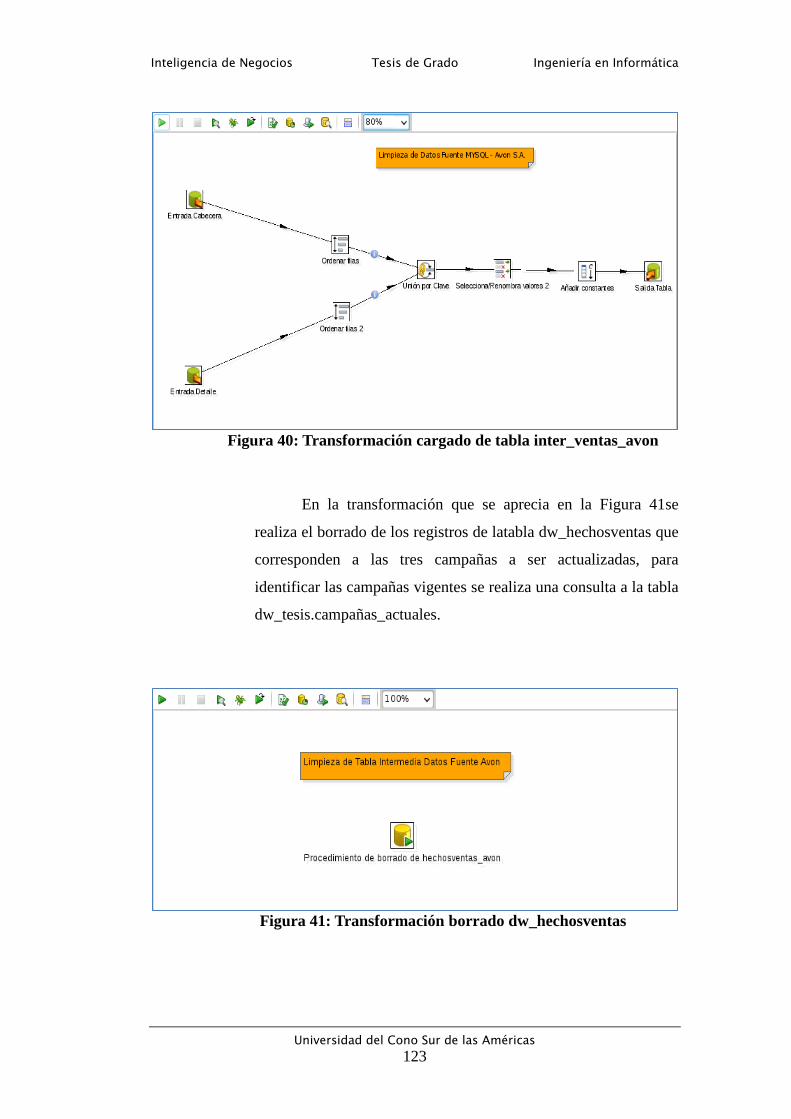
Figura 41: Transformación borrado dw_hechosventas ....................................... 123
Figura 42: Transformación cargado dw_hechosventas ....................................... 124
Figura 43: Trabajo general de cargado hechos_ventas Fuente Flayp ................. 125
Figura 44: Desarrollo reporte ventas por campañas por zonas ........................... 129
Figura 45: Reporte de proyección de ventas ....................................................... 130
Figura 46: Estructura de los cubos ...................................................................... 131
Figura 47: Capas de CDE .................................................................................... 134
Figura 48: Definición de estructura..................................................................... 134
Figura 49: Estructura de CDM ............................................................................ 135
Figura 50: Origen de datos .................................................................................. 135
Figura 51: Selección de archivos dbf Virú. ......................................................... 137
Figura 52: Cargado de tabla intermedia inter_ventas_viru ................................. 138
Figura 53: Borrado de dw_hechosventas ............................................................ 138
Figura 54: Cargado de dw_hechosventas ............................................................ 139
Figura 55: Trabajo hechos ventas fuente dbf ...................................................... 140
Figura 56: Cargado de la tabla inter_ventas_avon .............................................. 141
Figura 57: Borrado hechos ventas Flayp S.R.L. ................................................. 141
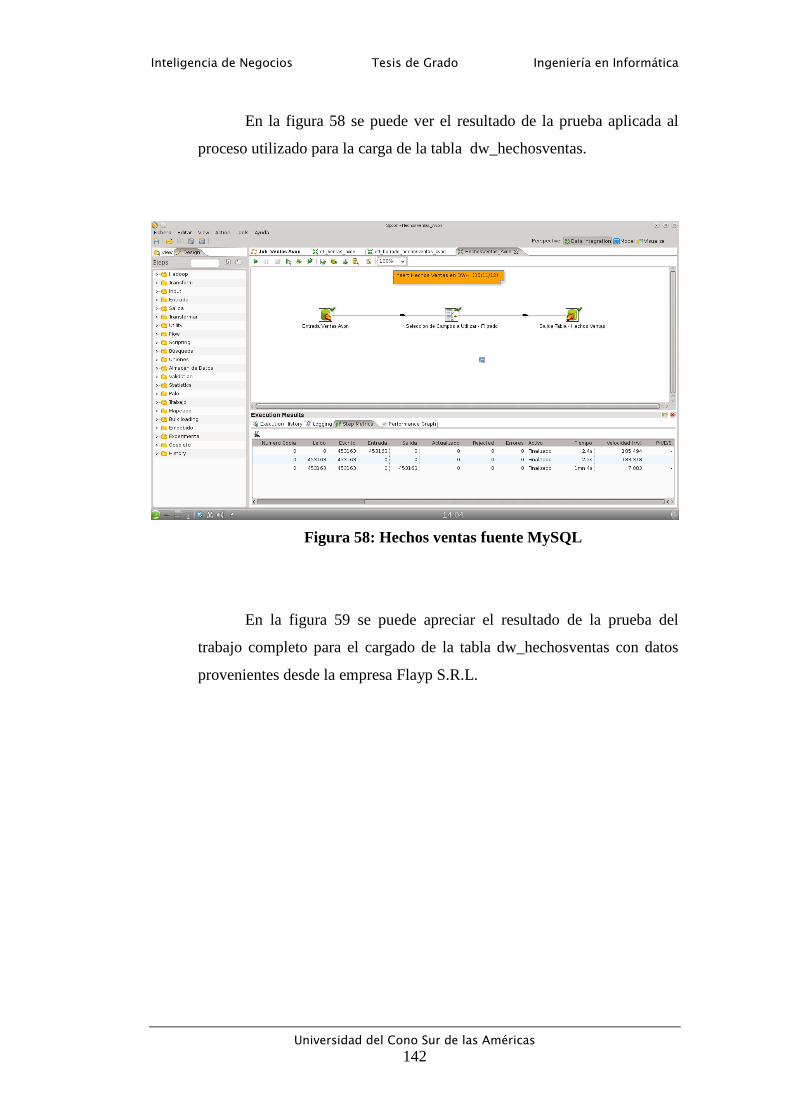
Figura 58: Hechos ventas fuente MySQL ........................................................... 142
Figura 59: Trabajo hechos ventas fuente MySQL............................................... 143
Figura 60: Descarga de Bussines Intelligence Server ......................................... 145
Figura 61: Inicio del servicio Apache. ................................................................ 146
Figura 62: Instalación de Pentaho Bussines Intelligence Server. ........................ 146
Figura 63: Pantalla de inicio de sesión en la consola de usuario de Pentaho...... 147
Figura 64: Consola de usuario Pentaho ............................................................... 147
Figura 65: Consola de administración de usuarios ............................................. 149
Figura 66: Administración de fuentes de datos ................................................... 150
Figura 67: Publicación del reporte ventas por campaña por zonas ..................... 151
Figura 68: Publicación reporte de ventas por zonas............................................ 151
Figura 69: Cubo de ventas .................................................................................. 152
Page 11
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 11
Figura 70: Participación en facturación por empresas ........................................ 153
Page 12
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 12
LISTA DE SÍMBOLOS O ABREVIATURAS
OLTP:Online Transaction Processing
OLAP:On-Line Analytical Processing
ETL:Estract, Transform and Load
ERP:Enterprise Resource Planning
CRM:Customer Relationship Management
KDD:Knowledge Discovery in Databases
VPN:Virtual Private Network
GNU:GNU is Not Unix
FSF:Free Software Foundation
GPL:General Public Licence
OSI:Open Source Initiative
PDI: Pentaho Data Integration
SGBD: Sistema Gestor de Base de Datos
TI: Tecnología de Información
DDL:Data Definition Language
DML: Data Manipulation Language
TCT/IP: Transmission Control Protocol Internet Protocol
Page 13
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 13
CAPITULO 1 - INTRODUCCIÓN
1.1. Planteamiento del Problema
El Grupo Flayp está compuesto por varias empresas, cada una de
ellas cuenta con diferentes sistemas de información para realizar sus
procesos de negocio, las mismas generan y almacenaninformaciónen
distintos formatos y en gran volumen.
Con toda esta acumulación de información diversificada,resulta
dificultoso para los gerentes tener una imagen precisa de la información
más importante para las empresas del Grupo y más aún para el directorio,
quien tiene a su cargo la dirección general Grupo.
A esto debemos sumarle, que ninguna de las empresas cuenta con
un sistema generador automático de informes, y que los mismos son
preparados sobre pedido, con todo lo que esto implica.
El reto de este proyecto consiste en brindar un prototipo de
solución de Inteligencia de Negocios capaz de transformar los datos en
información útil, de manera que los gerentes y directores puedan utilizar
dicha información para incrementar la rentabilidad de las empresas.
Brindándoles un soporte en el cual respaldar la toma de decisiones
estratégicas.
Page 14
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 14
1.2. Necesidad de estudiar el problema.
El hecho de tener una gran cantidad de datos acumulados, no
representa necesariamente tener una gran cantidad de información, y que
dicha información sea o no relevante para la empresa, depende en gran
medida de la forma y calidad en la que esta llegue a los tomadores de
decisiones, la Inteligencia de Negocios tiene como uno de sus ejes
principales lograr esto, ayudar a comprender mejor el comportamiento de
la empresa, esto da pie para para realizar un estudio e implementar
soluciones, haciendo uso de herramientas tecnológicas actuales, siguiendo
tendencias y estándares en las áreas de la informática.
1.3. Significación del problema
La importancia de este proyecto radica en lograr la implementación
de un prototipo de solución de Inteligencia de Negocios que sea capaz de
unificar los datos que se encuentran en distintos formatos, provenientes de
las dos empresas Flayp S.R.L. y Virú S.R.L., pertenecientes al Grupo
Flayp y lograr entre otras cosas, brindar información cohesionada, fiable y
útil.
1.4. Delimitación del problema
La presente tesis se limita al desarrollo de un prototipo de solución
de Inteligencia de Negocios para los departamentos de Ventas y Marketing
de las empresas Flayp S.R.L. y Virú S.R.L., integrantes del Grupo Flayp,
Page 15
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 15
en función a los requerimientos de información solicitadas por dichas áreas
para los procesos de ventas y pedidos.
En cuanto a los datos si bien en un principio se pretendía acceder a
toda la información del Grupo Flayp, las personas a cargo accedieron a
prestar los datos de forma parcial, haciendo énfasis en la importancia de
mantener la confidencialidad de los mismos y que fueran utilizados
exclusivamente para fines académicos.
1.5. Objetivos de la Tesis:
1.5.1. Objetivo General
Implementar un prototipo de Sistema de Inteligencia de
Negocios usando Minería de Datos sobre Software Libre.
1.5.2. Objetivos Específicos
a) Relevar todos los procesos administrativos y de negocio
de las empresas.
b) Relevar software, hardware y tipos de informes.
c) Analizar software, hardware y tipos de informes.
d) Definir los tipos de informes de acuerdo al perfil y las
necesidades de cada usuario.
e) Diseñar, desarrollar, probar e implementar prototipo de
solución de Inteligencia de Negocios.
Page 16
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 16
f) Documentar ciclo de vida del prototipo de solución de
Inteligencia de Negocios.
g) Realizar la demostración del funcionamiento del prototipo.
1.6. Definición de términos
Servidor:Máquina conectada a Internet que entre otros servicios ofrece
alojamiento para páginas web haciendo que estén accesibles desde
cualquier punto de Internet.
Data Warehouse: Colección de datos orientado a un ámbito determinado
(empresa, organización, etc.) sus características son no volátil, integrado y
variable en el tiempo.
Data Marts: Es una versión especial de data warehouse, son subconjuntos
de datos con la finalidad de ayudar a la toma de decisiones dentro de un
área específica en la organización.
Minería de Datos:La integración de un conjunto de áreas que tienen como
propósito la identificación de un conocimiento obtenido a partir de las
bases de datos que aporten una guía para la toma de decisiones.
Inteligencia de Negocios:Es unconjunto de tecnologías que tienen un fin
común con el principal objetivo que es la de servir como soporte para la
toma de decisiones.
Cuadros de Mando:Es una herramienta de gestión que facilita la toma de
decisiones, recoge un conjunto coherente de indicadores que proporciona a
los niveles gerenciales una visión comprensible del negocio de manera
gráfica.
Software Libre: se refiere al tipo de licencias de software que garantiza la
libertad de los usuarios para ejecutar, copiar, distribuir, estudiar, cambiar y
mejorar el software.
Open Source: Es el termino con el que se conoce al software distribuido y
desarrollado libremente.
Page 17
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 17
Consultas Adhoc:Se refiere a las consultas elaboradas específicamente
para un fin preciso y por lo tantono generalizable ni utilizable para otros
propósitos.
Copyleft: Es un método general para hacer un programa o software libre,
exigiendo que todas las versiones modificadas y extendidas del mismo
sean también libres.
1.7. Presentación del esquema
En el Capítulo I – Introducción:se presenta el contenido de la tesis, la
definición del problema de la investigación, la justificación de la necesidad
del estudio y los objetivos.
En el Capítulo II - Marco Teórico: en este capítulo se realiza una
descripción de la importancia y el valor de la información en las empresas,
y el concepto de la Inteligencia de Negocios, donde se mencionan sus
principales componentes como lo son el data warehouse,On-Line
Analytical Processing (en adelante OLAP), Extract, Transform and Load
(en adelante ETL) y minería de datos, además se muestran los principios
claves de estas tecnologías, también se hace referencia al concepto de
software libre y por último se presenta al Grupo Flayp, ya que es este el
lugar elegidopara llevar adelante este trabajo de grado, todas estas
secciones son para una mejor comprensión de lo que se pretende lograr
con este proyecto.
En el Capítulo III - Marco Metodológico:se trata sobre la metodología
utilizada en este trabajo, tipo de investigación y los detalles de la
realización. El mismo se encuentra dividido en 6 partes. En la primera se
Page 18
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 18
describen los métodos utilizados para el relevamiento de los
requerimientos, datos, procesos, tecnología y herramientas. En la segunda
parte se analizan los datos relevados seleccionando los inherentes al
proyecto, también se analiza el modelo de datos de los sistemas actuales, y
se seleccionan aquellos que serán utilizados para el modelado de datos del
datawarehouse, además se realiza una comparación entre las diferentes
opciones de herramientas de inteligencia de negocios. En la tercera se
realizan los diseños deldata warehouse, los procesos de ETL, los distintos
tipos de informes y los diagramas necesarios para la realización del
proyecto. En la cuarta parte se desarrolla el prototipo. En la quinta se
realizan las pruebas del prototipo. En la sexta y última etapa se realiza la
implementación del prototipo.
En el Capítulo IV – Resultados: se describen los resultadosobtenidos,
demostrando la factibilidad de la implementación de un prototipo de
solución de Inteligencia de Negocios sin incurrir en gastos en cuanto a
licencias de software.
En el Capítulo V – Conclusiones:se presenta la síntesis de los objetivos y
la conclusión del trabajo.
Page 19
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 19
CAPITULO 2–MARCO TEÓRICO
2.1. El valor de la información
En la actualidad, cuya característica más importante, se basa en un
crecimiento a gran escala de las tecnologías de la información y las
telecomunicaciones, los activos más valiosos de una empresa pasan a ser
los conocimientos, habilidades, valores y actitudes de sus empleados.
Partiendo de la premisa de que el conocimiento sobre un tema
determinado y su optima utilización, se convierte en un factor
determinante para el éxito en el mundo empresarial. El capital intelectual
ha desplazado a los factores tradicionales, como ser la producción, el
capital, la tierra oel trabajo, como principal elemento a la hora de generar
valor económico para la empresa, tal como se desprende del planteamiento
de Cohen y Asín (2.000).
Todas las compañías de alguna manera han adoptado un modelo del
mundo de negocios sustentado en la información, como por ejemplo: ¿qué
factores influyen en la compra y la demanda?, ¿cómo hallar las
oportunidades de negocio?, ¿existe directa relación entre la calidad del
producto y la demanda de los clientes? A medida que la exactitud de esta
información crece, la capacidad de la empresa por competir se incrementa
en forma proporcional.
La información puede transformarse en conocimiento tácito o
explícito. Se entiende por conocimiento tácito aquel que poseen las
personas producto de la experiencia adquirida, los estudios y la educación;
Page 20
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 20
mientras que los conocimientos explícitos son aquellos almacenados en
bases de datos. Un ejemplo claro es aquel que se produce cuando una
persona cambia de empleo, esta se está llevando consigo información,
conocimientos y está ofertando su capacidad intelectual por un mayor
precio; en el ámbito laboral, la experiencia y la educación son factores
claves para aumentar el costo de la fuerza del trabajo intelectual. Así
mismo, el hecho de que un sistema que maneja información,
eventualmente falle, indefectiblemente generará pérdidas a la empresa.
Es una clara tendencia que las empresas están apostando
fuertemente por la tecnología y las personas, para que en conjunto tengan
un conocimiento suficiente que logre acercar la visión interna de ambos a
la realidad exterior, en la misma medida que la brecha entre la visión
interna y la realidad exterior disminuye, se consigue tomar decisiones más
acertadas y en menos tiempo. Lo que busca esta tendencia es acercar lo
máximo posible el mundo real a la visión interna para generar mayores
ganancias, convirtiendo la información en utilidad y darle un valor a la
información.
2.2. Necesidad de información y conocimiento en la empresa
Desde el mismo instante en que las empresas iniciaron el proceso
de acumular los datos de sus operaciones en medios de almacenamiento
físico, y de esa forma conseguir una mejor administración y control de
dicha información, ha surgido la necesidad de utilizarla para entender las
necesidades particulares del negocio. En un mercado altamente
competitivo, donde muchas marcas ofrecen productos similares, los
clientes tienen una amplia gama de posibilidades para la elección del
producto. Para obtener una porción del mercado, es indispensable para las
Page 21
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 21
empresas, tener la suficiente capacidad de transformar la información
acumulada en conocimiento.
La necesidad de información en las empresas no surge de un día
para el otro, el propósito de almacenar los datos radica en su utilización en
algún momento, cuando así se requiera, caso contrario, cualquier dato de
control sería desechado instantáneamente. Lo que si surge súbitamente, es
la imperiosa necesidad de dar respuesta rápida a los requerimientos de
información para la toma de decisiones y ayudar a mejorar de alguna
manera los procesos internos de negocio.
2.3. La información que las empresas necesitan
En la actualidad las organizaciones demandan información en los
niveles donde anteriormente la administración se basaba meramente en la
intuición y el sentido común para la toma de decisiones. Los mercados
dinámicos obligan a las empresas a que la información estratégica esté
disponible en las computadoras de los directivos y/o gerentes, esta práctica
se ha generalizado principalmente motivada por la mayor utilidad que se
obtiene de la información compartida.
Hoy en día la información está presente en todos los niveles de la
organización con propósitos diferentes (comunicación, control,
administración, evaluación, etc.) ayudando a la correcta y oportuna toma
de decisiones desde el nivel gerencial, hasta el nivel operativo de la
organización. Las empresas han entendido que a pesar de que los niveles
directivos tienen una gran responsabilidad al tomar decisiones, por el peso
que conllevan las mismas, existen también personas que toman decisiones
Page 22
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 22
y a pesar de que éstas no tienen un impacto global, deben ser de igual
manera correctas y oportunas.
Directores, gerentes, jefes y todos aquellos que toman decisiones
deben contar con la suficiente información para respaldar su trabajo
cotidiano, la posición que ocupen en la pirámide organizacional se torna
secundaria cuando la mirada es hacia la gestión de los procesos y como así
también los puestos que tienen cierta relación y dependencia entre sí.
De modo general en una pirámide organizacional, los
requerimientos informativos se dividen en tres niveles:
Información Estratégica
Información Táctica
Información Técnico Operacional.
Información Estratégica: está pensada principalmente para ayudar a la
toma de decisiones de las áreas gerenciales para alcanzar la misión
empresarial. Se caracteriza porque son sistemas con poca carga diaria de
trabajo y sin una gran cantidad de datos, sin embargo, la información que
guarda está relacionada a un contexto cualitativo más que cuantitativo, que
puede indicar cómo evolucionará en el futuro, el criterio es distinto, pero
sobre todo es distinta su delimitación. Se asocia esta información a los
niveles ejecutivos de las empresas. Es importante señalar que la
información estratégica se nutre de grandes cantidades de datos de áreas
relacionadas y no se enfoca puntualmente en una sola dirección, de ahí que
las decisiones que puedan ser tomadas tienen un impacto directo en toda la
organización.
Page 23
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 23
Información Táctica: este tipo de información es la que soporta la
coordinación de actividades y el nivel operativo de la estrategia, es decir,
se analizan opciones y se trazan rutas posibles para alcanzar la estrategia
definida por la dirección de la empresa. Se facilita la gestión independiente
de la información por parte de los niveles intermedios de la organización.
Este tipo de información es extraída puntualmente de un área o sección de
la organización, por lo que su alcance es local y se asocia habitualmente a
las gerencias.
Información Técnico Operacional: hace referencia a las operaciones
diarias que son efectuadas de modo rutinario en las corporaciones
mediante la transacción masiva de datos y sistemas transaccionales. Las
cargas son cotidianas y soportan la actividad de la empresa día tras día
(contabilidad, facturación, almacén, presupuesto, etc.). Generalmente se
asocia esta información con los jefes de área o las coordinaciones
operativas, también llamadas de tercer nivel.
Podemos considerar entonces factores internos y externos de una
empresa y así concluir que los requerimientos en la actualidad se orientan
a descubrir y mejorar los beneficios de toda la cadena corporativa. Dichos
requerimientos se ven reflejados en el interés por tener a mano los
indicadores que arrojen información concreta y clave para determinada
área de la empresa, y en el menor tiempo posible. La clara tendencia es
que las áreas gerenciales necesitan en su mesa de trabajo, la información
clave de su empresa; en todos los niveles el requerimiento es parecido,
aunque es evidente que tendrá objetivos diferentes.
Page 24
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 24
2.4. Las organizaciones y los distintos sistemas de información
Para que una empresa esté completamente automatizada es
necesario contar con una gran infraestructura en tecnologías para que
soporte todos los sistemas de información. El crecimiento en tecnología
puede tener distintos orígenes partiendo desde la implementación,
crecimiento, ampliación, mantenimiento, etc. Las necesidades actuales de
las empresas han provocado contar con tecnología de la informaciones más
sofisticados para responder a cada una de sus peticiones de información,
esto impulsó a que las compañías adquieran distintos tipos de sistemas de
informaciones, entre estos sistemas podemos mencionar a los OnLine
Transaction Processing(en adelante OLTP), Planificación de Recursos
Empresariales(en adelante ERP), Sistemas de Soporte para la toma de
decisiones (en adelante DSS), Administración de la Relación con Clientes
(en adelante CRM), etc.
Estos sistemas siempre están utilizando bases de datos para
almacenar la información generada, las mismas se utilizan como soporte
para la toma de decisiones en las empresas.
Existen empresas que precisan información de una actividad
específica, un ejemplo seria los Sistemas ERP (Planificación de Recursos
Empresariales) son sistemas muy complejos y grandes donde un alto
porcentaje de su contenido dedica a los procesos de producción, si una
empresa se dedica a las bienes raíces, sería ilógico adquirir un sistema de
alta complejidad y costoso como las ERP que no va a dar una solución a
las necesidades de la empresa. Para empresas como estas, existen
desarrollos de soluciones en el mercado comercializado como productos
que pueden ser configurados en una organización en particular de acuerdo
a sus necesidades, que dan soluciones a requerimientos específicos para
Page 25
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 25
cada industria. Hay en el mercado, software para distintos tipos de
empresas como automotriz, hotelería, comercios, educativos entre otros.
Son distintas las herramientas utilizadas debido a que las
actividades de misión crítica que soportan cada una de las organizaciones
son diferentes, y por ende también son distintos los tipos de información
que puede solicitar un directivo en cada una de las organizaciones, lo cual
justifica que existan muchos productos de software dedicados a explotar la
información de las bases de datos que no tienen características estándares,
sino más bien son adaptables según las exigencias. Considerando las
necesidades que se presentan en cada actividad.
La información que se genera en una empresa u organización está
destinada a responder a diversos tipos de preguntas de los usuarios, de ahí
nace la necesidad que existan sistemas de información para requerimientos
muy específicos que permitan la recolección y el manejo de los datos. La
estructura organizacional de una empresa es un factor importante para
determinar la información que comúnmente es requerida por los
funcionarios.
Los sistemas de procesamiento de datos (OLTP) utilizan medios de
almacenamiento y técnicas para el cargado. Un alto porcentaje de las
empresas recurren a los OLTP para guardar grandes cantidades de datos
con un tiempo de respuesta corto en los miles de transacciones realizadas
cotidianamente, sin embargo, su eficiencia no son las consultas masivas de
grandes cantidades de información y mucho menos el análisis de la misma.
Page 26
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 26
La tecnología tuvo que adaptar los medios necesarios para que sean
eficientes en el ámbito específico de aplicación, así como para el diseño de
estructuras de datos que ordenen la información como se desea, como en
las herramientas o software que dan soluciones oportunas a los usuarios.
Todos los sistemas de información tienen un fin muy particular, y se
complementan para mantener de la manera más eficiente una organización;
sin embargo, no todos pueden dar solución a las distintas demandas de los
usuarios, ya que son diseñados para alguna área específica.
El motivo por el cual existen diferentes sistemas de información es
porque las preguntas de los usuarios son muy específicas que no cualquier
sistema puede resolver. De hecho la base de datos operacional, que es
imprescindible en cualquier organización pero no está organizada para dar
respuestas a preguntas globales sino más bien a pequeños grupos de datos.
Preguntas que impliquen consultas complejas podrían resolverse en un
lapso muy extenso, donde la posibilidad de que la vigencia desaparezca
aumenta considerablemente. Es importante recalcar que una base de datos
o sistema de información no está diseñada para resolver las necesidades
informativas de la organización a nivel macro.
2.5. Definición de Inteligencia de Negocios
La Inteligencia de Negocios cuenta con una diversidad de
interpretaciones como muchos otros términos o conceptos. Su uso es
justificado a todo lo que sea considerado como tecnología de información,
pero no hay un consenso en lo respecta a su definición.
Page 27
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 27
“[…] es el conjunto de tecnologías que permiten a las empresas
utilizar la información disponible en cualquier parte de la organización
para hacer mejores análisis, descubrir nuevas oportunidades y tomar
decisiones más informadas”(HOWARD DRESNER, H 1.989).
Examinando las distintas definiciones queda claro que la
Inteligencia de Negocios no consiste en una metodología, sistema,
software o herramienta en particular, si no es un conjunto de tecnologías
que tienen un fin común con el principal objetivo que es la de servir como
soporte para la toma de decisiones.
2.6. Los usuarios de las soluciones de Inteligencia de Negocios
A continuación se describen los diferentes tipos de usuarios que
intervienen en una solución de inteligencia de negocios.
Productores de información:“[..]Habitualmente son el 20% de
los usuarios, que crean informes o modelos utilizando herramientas de
escritorio. Donde predominan estadísticos que se valen de herramientas
para minería de datos o son creadores de informes que utilizan
herramientas para el diseño y/o programación de informes específicos.
Regularmente son profesionales del área de sistema de información o
usuarios muy avanzados con capacidades de comprender la información
y la informática”(CANO, J 2.007).
Los consumidores de información: “[…] Son usuarios no
habituales que regularmente consultan informes para la toma de
decisiones, pero no acceden a los números o hacen análisis detallados
Page 28
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 28
diariamente. Los usuarios no habituales son directivos, gestores,
responsables, colaboradores y usuarios externos. Este numeroso grupo
está bien servido con cuadros de mando con análisis guiados, informes
interactivos (por ejemplo: OLAP, informes parametrizados,
vinculados,…) e informes de gestión estandarizados. La mayoría de estas
herramientas proveen ahora acceso vía web para promover el acceso
desde cualquier lugar y facilitar el uso y minimizar los costes de
administración y mantenimiento”(CANO, J 2.007).
En la Figura 1 se puede apreciar a través de una pirámide los
distintos niveles de usuarios en una solución de inteligencias de negocios.
Figura 1: Pirámide de usuarios de un sistema de Inteligencia de
Negocios
2.7. Historia de la Inteligencia de Negocios
En octubre de 1.958 H.P. Luhn de IBM, escribió un artículo
llamado Business Intelligence System donde describe las características
Page 29
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 29
que debe tener un sistema de este tipo, en muchos aspectos de lo que
escribió Luhn tiempo atrás, si se realiza un paralelismo de lo que se
entiende hoy en día por inteligencia de negocios no varió mucho.
Edgar Frank Codd presenta el concepto de las bases de datos en el
año 1.969, un año más tarde se desarrollaron las primeras base de datos
con sus interfaz empresariales, estas aplicaciones, facilitan la entrada de
datos en los sistemas, haciendo que aumente la información disponible,
pero como el acceso a la información era de alta complejidad y difícil de
acceder a las mismas no fue una solución completa. Otro de los avances
llegaron en el año 1.980 con la creación del concepto del data warehouse
por Ralph Kimball y Bill Inmon, con ellas aparecieron los primeros
sistemas de reportes, con todo esto la solución seguía siendo compleja y
funcionalmente pobre, se contaba con potentes sistemas de bases de datos
pero no existían aplicaciones que facilitaran su explotación.
En 1.989 Howard Dresner difundió el término de Business
Intelligence escrito por H.P. Luhn en el año 1.958, en la década de los 90
llegaba la Business Intelligence1.0 y con ello la multiplicación de
aplicaciones de Inteligencia de Negocios, logrando facilitar el acceso a la
información considerablemente pero empeoraron el problema que se
quería resolver ya que seguían apareciendo múltiples soluciones sin poder
consolidarse. Con la llegada de Business Intelligence 2.0 en el año 2.000
se logró consolidar las aplicaciones en una pocas plataformas a partir de
ahí las herramientas empezaron a dar soluciones reales a las empresas u
organizaciones.
Page 30
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 30
2.8. Características de la Inteligencia de Negocios
Información: el propósito de la Inteligencia de Negocios es
proveer de información al usuario final para dar soporte a la toma
decisiones, por ende la información es la esencia de la Inteligencia de
Negocios, estas pueden originarse desde las bases de datos operacionales,
como también de arquitecturas data mart y data warehouse diseñadas
específicamente para el análisis.
El usuario requiere de información para apoyarse en el momento de
tomar decisiones, pasando en segundo plano de dónde provenga esta,
pudiendo ser de una fuente primitiva o derivada, para lo cual la
inteligencia de negocios utiliza o crea fuentes de datos interna o externa
con el fin de utilizarla como materia prima para lograr su objetivo.
Apoyo a la toma de decisiones: básicamente consiste en organizar
y presentar los datos relevantes para que sirvan como soporte a la hora de
tomar decisiones. Esto implica la utilización de tecnologías, técnicas de
análisis y todo lo que sea necesario con el fin de obtener solamente aquella
información relevante y útil.
Orientación al usuario final:un factor fundamentalque tuvo su
incidencia en la tecnología de la Inteligencia de Negocios para explotar
información, fue que el usuario final no contaba con conocimientos y
técnicas que le permita acceder de una manera sencilla y directa a los datos
almacenados en los sistemas operacionales, ya que casi siempre necesitaba
de ayuda de informáticos para acceder a la información, con la Inteligencia
de Negocios, se elimina la dependencia de terceras personas para el acceso
Page 31
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 31
a los datos e información, siendo esta una herramienta sencilla y preparada
para que interactúe directamente con el usuario final sin intermediarios.
2.9. Componentes de una solución de Inteligencias de Negocios
Teniendo en cuenta el esquema mencionado por Cano (2.007) la
solución de Inteligencia de Negocios está compuesta por las fuentes de
información, proceso de ETL (extracción, transformación y limpieza de
datos) datawarehouse y motor OLAP como se puede apreciar en la figura
2.
Figura 2: Componentes de Inteligencia de Negocios
Page 32
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 32
Los componentes son:
Fuentes de información: generalmente son los datos generados por
sistemas operacionales, los cuales se utilizan para alimentar de
información el data warehouse.
Proceso ETL: de extracción, transformación y carga de los datos en
el datawarehouse. Los datos antes de almacenarse en un data
warehouse,pasan por procesos de filtrado, limpieza, trasformación
y redefinición.
El datawarehouse: en él se almacenan los datos de una manera que
optimice su flexibilidad, facilidad de acceso y administración, en
donde los datos están estructurados para generar informes que
ayuden a la toma decisiones.
El motor OLAP: es el que proporciona la capacidad de realizar
cálculos, análisis, pronósticos, consultas en grandes volúmenes de
datos.
2.9.1. Las fuentes de información a las que se puede acceder son:
a) Los sistemas operacionales, que contienen las aplicaciones
desarrolladas a medida.
b) Sistemas de información por sector: presupuestos, hojas
de cálculo, etcétera o fuentes de información externa,
compradas a terceros como por ejemplo el estudio del
mercado.
Page 33
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 33
En la figura 3 se aprecian las distintas fuentes de
información en un sistema de Inteligencia de Negocios.
Figura 3: Fuentes de información.
2.9.2. Proceso de extracción, transformación y carga
El proceso de extracción, transformación y carga, también
denominado simplemente ETL, es el proceso que permite realizar
el cargado y actualización de los datos obtenidos desde las
distintas fuentes de información en el datawarehouse,
habitualmente consume entre el 60% y el 80% de recursos en un
proyecto de Inteligencia de Negociostal como lo indica Ralf
Kimball (2.004), por lo que es un proceso clave en la vida de todo
proyecto de esta naturaleza.
Page 34
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 34
Esta etapa del proceso de construcción del datawarehouse,
es costosa e implica una inversión significativa de tiempo y
esfuerzo, para la concreción de la misma, por ello requiere
recursos, estrategia, habilidades especializadas y tecnologías.
La extracción, transformación y carga es necesaria para
acceder a los datos de las fuentes transaccionales de información
y volcarlas al data warehouse. El proceso ETL se divide en cinco
subprocesos:
Extracción: en este proceso se recuperan los datos
físicamente de las distintas fuentes de información
transaccional. En este momento se dispone de los datos en
bruto.
Limpieza: a través de este proceso se recuperan los datos
en bruto y se comprueba su calidad, aquí se eliminan los
datos duplicados y, de ser posible, se corrigen los valores
erróneos, y completa los valores vacíos, es decir se
transforman los datos, siempre que esto sea posible, para
reducir al mínimo los errores de carga. En este momento
se dispone de datos limpios y de alta calidad.
Transformación: este proceso utiliza los datos limpios y de
alta calidad obtenidos en la etapa anterior y los estructura
en los distintos modelos de análisis. Como resultado de
este proceso se obtienen datos limpios, consistentes y
útiles.
Integración: en este proceso se validan los datos cargados
en el data warehouse, se analiza si son congruentes con
Page 35
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 35
las definiciones y formatos del data warehouse; es aquí
donde se integran en los distintos modelos, de las distintas
áreas de negocio que se han definido en el mismo. Estos
procesos pueden ser complejos.
Actualización: este es el proceso que permite añadir los
nuevos datos al data warehouse, como así también
mantener el mismo siempre actualizado.
2.9.3. Data warehouse
Eldata warehouse o almacén de datos, es la herramienta
que surgió como respuesta a las necesidades de los usuarios de los
niveles gerenciales, que necesitan información consistente,
integrada, histórica y preparada para ser analizada y utilizada para
mejorar la toma de decisiones.
Su ubicación en el contexto de una solución de
Inteligencia de Negocios se puede apreciar en la sección resaltada
de la figura 4.
Page 36
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 36
Figura 4: Data warehouse
El hecho de recuperar la información desde los distintos
sistemas que posea la empresa, sean estos transaccionales o
externos, para luego almacenarlos en un entorno cohesionado de
información, como es un data warehouse, permitirá analizar la
información contextualmente y relacionada dentro de la
organización.
Las características que debe cumplir undata warehouse
son:
Temático.
Integrado.
Histórico.
No volátil.
Page 37
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 37
El proceso de diseño y construcción de un data warehouse
corporativo usualmente resulta costoso, además de requerir plazos
de tiempo que las empresas no están dispuestas a aceptar. Estas
situaciones, fueron las que originaron la aparición de los data
mart. Los data mart están enfocados a un grupo particular de
usuarios dentro de la organización, que bien puede estar
conformado por los miembros de un departamento, o por los
usuarios de un determinado nivel organizativo, o por un equipo de
trabajo multidisciplinario con objetivos comunes.
Los data mart, se utilizan para almacenar información de
un grupo de áreas en particular, cuyo flujo de información sea
coincidente; por ejemplo, podrían ser de marketing y ventas o de
producción. Lo usual es que éstos se definan para dar respuestas a
usos muy concretos.
Por lo general, los data mart son más pequeños que los
data warehouses. También almacenan menor cantidad de
información, menos modelos de negocio ya que son utilizados por
un menor número de usuarios.
Existen dos tipos de data mart, estos pueden ser
independientes o dependientes. Los independientes son
alimentados directamente desde las fuentes de información,
mientras que los independientes obtienen la información desde el
data warehousecorporativo. Con los data mart independientes
pueden surgir inconvenientes en su evolución, ya que pueden
llegar a generar inconsistencias con otros data mart.
Page 38
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 38
En la figura 5 puede apreciarse la estructura de los data
marts dentro de una solución de Inteligencia de Negocios.
Figura 5: Data marts
Existen grandes diferencias entre los sistemas
transaccionales y los data warehouses, en función a los objetivos
que persiguen cada una de ellos.
El objetivo primordial del modelo relacional en el cual se
basa el concepto OLTP es el de mantener la integridad de la
información en cuanto a las relaciones entre los datos, lo cuales
necesario para operar un negocio de la manera más eficiente. Sin
embargo, este modelo no se corresponde con la forma en la que
el usuario percibe la operación de un negocio.
Los data werehouses están basados en un procesamiento
de los datos distinto al utilizado por los sistemas operacionales, ya
que este se basa en el concepto OLAP pensado y utilizado en el
análisis de negocios y otras aplicaciones que requieren una visión
flexible del negocio.
Page 39
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 39
A continuación en la Tabla 1 se presentan las principales
diferencias entre los sistemas transaccionales (OLTP) y los
basados en data warehouses (OLAP).
Transaccionales Basados en Data warehouse
Admiten el acceso simultáneo de muchos usuarios
(miles) que agregan y modifican datos.
Admiten el acceso simultaneo de muchos usuarios
(cientos) que consultan y no modifican datos
Representan el estado actual de una organización,
pero no guardan su historial.
Guardan el historial de una organización.
Contienen grandes cantidades de datos, incluidos
los datos extensivos utilizados para comprobar
transacciones.
Contienen grandes cantidades de datos, sumarizados,
consolidados y transformados. También de detalle
pero solo los necesarios para el análisis.
Tienen estructuras de base de datos complejas Tienen estructuras de base de datos simples.
Se ajustan para dar respuesta a la actividad
transaccional.
Se ajustan para dar respuesta a la actividad de
consultas.
Proporcionan la infraestructura tecnológica
necesaria para admitir las operaciones diarias de la
empresa.
Pueden combinar datos de orígenes heterogéneos en
una única estructura homogénea y simple, facilitando
la creación de informes y consultas.
Las consultas analíticas que resumen grandes
volúmenes de datos afectan negativamente a la
capacidad del sistema para responder a las
transacciones en línea.
Organizan los datos en estructuras simplificadas
buscando la eficiencia de las consultas analíticas más
que del proceso de transacciones.
El rendimiento del sistema cuando está
respondiendo a consultas analíticas complejas
puede ser lento o impredecible, lo que causa un
servicio poco eficiente a los usuarios del proceso
analítico en línea.
Contienen datos transformados que son válidos,
coherentes, consolidados y con el formato adecuado
para realizar el análisis sin interferir en la operación
transaccional diaria.
Los datos que se modifican con frecuencia
interfieren en la coherencia de la información
analítica.
Proporcional datos estables que representan el
historial de la empresa. Se actualizan periódicamente
con datos adicionales, no como las transaccionales
frecuentes.
La seguridad se complica cuando se combina
análisis en líneas con el proceso de transacciones
en línea.
Simplifican los requisitos de seguridad.
Tabla 1: Diferencias entre sistemas OLTP y OLAP.
Page 40
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 40
2.9.4. Herramientas de acceso de la Inteligencia de Negocios
La información almacenada en un data warehouse, seria
intrascendente, si ésta no pudiera ser accedida por los usuarios,
para ello existen herramientas que permiten tratar y visualizar la
información que reside en un data warehouse.
En la sección resaltada de la figura 6 se aprecia la
ubicación de las herramientas de acceso en una solución de
Inteligencias de Negocios.
Figura 6: Herramientas de acceso.
Page 41
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 41
Existen diferentes tecnologías que permiten aprovechar y
analizar la información almacenada en un data warehouse, siendo
el uso de los cubos OLAP la más extendida de ellas.
Los usuarios que toman decisiones necesitan analizar
información a distintos niveles de agregación y tener una visión
sobre múltiples dimensiones, por ejemplo, las ventas de
determinados productos por zonas, por tiempo, por clientes o por
región geográfica. Estos usuarios deben poder realizar este
análisis al máximo nivel de agregación o al máximo nivel de
detalle. Los cubos OLAP permiten realizar esto de modo a poder
aprovechar al máximo las posibilidades que ofrecen los data
warehouses.
A estos tipos de análisis se los denomina
multidimensionales, ya que permiten el análisis de un hecho en
particular desde distintas dimensiones. Esta es la mejor forma de
analizar la información por parte de los tomadores de decisiones,
ya que los modelos de negocio habitualmente son
multidimensionales.
Las herramientas que se utilizan para la visualización de la
información,son totalmente independientes a la forma en la que
ésta se haya almacenado.
Las formas de acceso de las herramientas OLAP son:
Page 42
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 42
Cliente/Servidor: esto significa tener instalado en la
maquinas cliente, el aplicativo que va conectarse al
servidor donde se almacenan la información que generan
los cubos OLAP.
Acceso web: en este tipo de acceso, el navegador es el que
se comunica con un servidor web, el cual se comunica con
el servidor OLAP donde se almacena la información que
generan los cubos.
2.10. Principales herramientas de la Inteligencia de Negocios
Generadores de informes: estos son utilizados por desarrolladores
profesionales para crear informes estandarizados enfocados a
departamentos, grupos interdepartamentales o la organización.
Herramientas de usuario final de consultas e informes: estas son
utilizados por los usuarios finales para crear informes para su
propio uso o para otros usuarios; no requieren programación.
Herramientas OLAP: estas permiten a los usuarios finales
manipular la información de forma multidimensional para poder
visualizarla desde distintas perspectivas y en función a los criterios
que el usuario considere importantes.
Herramientas de cuadros de mandos: estas permiten a los usuarios
finales visualizar información crítica para el desempeño de manera
rápida, valiéndose para ello de gráficos, ofreciendo la posibilidad
de visualizar alguna sección con más en detalle.
Herramientas de minería de datos: estas permiten a los analistas de
negocio crear modelos estadísticos. La minería de datos es el
proceso para descubrir e interpretar patrones ocultos a simple vista
en un gran cúmulo de información. Los usos más habituales de la
Page 43
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 43
minería de datos son: segmentación, clasificación, previsiones,
agrupación, etc.
2.11. Minería de datos
2.11.1. Conceptos e historia de la minería de datos
El termino minería de datos, desde el enfoque académico
es una de las etapas dentro del proceso de Knowledge Discovery
in Databases(en adelante KDD).
Básicamente la minería de datos consiste en nutrirse de las
ventajas de cada aérea como la estadística, inteligencia artificial,
computación gráfica, bases de datos y procesamiento masivo,
utilizando como materia prima las bases de datos operaciones.
Definición tradicional de minería de datos: “[..]esun
proceso no trivial de identificación válida, novedosa,
potencialmente útil y entendible de patrones comprensibles que
se encuentran ocultos en los datos” (FAYYAD,U 1.996).
Desde el punto de vista empresarial, la minería de
datos se define como: “[..]La integración de un conjunto de
áreas que tienen como propósito la identificación de un
conocimiento obtenido a partir de las bases de datos que aporten
un sesgo hacia la toma de decisión” (MOLINA, L 2.001).
Page 44
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 44
La idea de la minería de datos viene desde los años 60,
cuando los estadísticos de esa época manejaban términos como
data fishing, data mining o data archeology,más tarde en los años
80, Rakesh Agrawal, Gio Wiederhold, Robert Blum y Gregory
Piatetsky-Shapiro, entre otros empezaron a fortalecer los términos
de data mining y KDD.
A finales de los años 80 solo existían un par de empresas
quienes se dedicaban a esta tecnología; para el 2.002 este número
se multiplicó considerablemente, ya que existían más de 100
empresas en el mundo con un portafolio de más de 300 soluciones
que utilizaban la tecnología.
La minería de datos no es un gran software ni algo
parecido, más bien la tecnología está compuesta por etapas que
integran diferentes áreas. Tanto así que para el desarrollo de un
proyecto de minería de datos, se utilizan diferentes aplicaciones
de software para las distintas etapas.
En la actualidad podemos encontrar una variedad
importante de herramientas o aplicaciones comerciales y no
comerciales con una utilería interesante, pero casi siempre es
necesario complementar con otras herramientas para el desarrollo
de la minería de datos.
Page 45
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 45
2.11.2. Los fundamentos de la minería de datos.
Las técnicas de minería de datos, se considera al resultado
de un proceso de investigación y desarrollo de productos.
La evolución comenzó cuando las organizaciones
empezaron a guardar sus datos en las computadoras, esto fue
creciendo cuando se mejoraron el acceso a los datos permitiendo
al usuario navegar y explorar en tiempo real sus datos.
La minería de datos tomando este proceso de evolución
está lista para ser implementada en las organizaciones, utilizando
estas tres tecnologías que ya están muy consolidadas como pilares
de su aplicación:
Recolección masiva de datos.
Potentes computadoras con multiprocesadores.
Algoritmos de minería de datos.
2.11.3. Objetivos de la minería de datos
Examinar, analizar y buscar patrones ocultos en los datos
acumulados en las profundidades de las bases de datos o en
almacenes de datos que contienen datos históricos que ha
generado una organización durante su existencia.
Page 46
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 46
2.11.4. Entorno de la minería de datos
La minería de datos normalmente utiliza la arquitectura
cliente-servidor.
La minería de datos a través de sus herramientas ayuda a
extraer información oculta, archivos acumulados en las bases de
datos operaciones y/o almacenes de datos de las grandes
corporaciones públicas y privadas.
Los usuarios de la minería de datos normalmente no
cuentan con ninguna habilidad de programación, por los cual se
valen de las poderosas herramientas para efectuar consultas adhoc
y obtener respuestas en tiempo real.
La minería de datos es capaz de producir seis tipos de
información:
Asociaciones.
Agrupamientos.
Clasificaciones.
Pronósticos.
Secuencias.
Clasificaciones.
Page 47
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 47
2.11.5. El alcance de la minería de datos
La minería de datos consiste en buscar valiosas
informaciones en grandes bases de datos. Este proceso requiere
explorar grandes cantidades de datos y analizarlos
minuciosamente hasta encontrar las informaciones requeridas.
En las bases de datos de gran volumen y calidad, la
minería de datos puede proporcionarnos oportunidades de
negocio con las siguientes posibilidades:
Pronóstico de comportamiento a futuro: la minería de
datos proporciona la automatización del proceso de
obtención de información predecible en bases de datos de
gran volumen, estos pronósticos pueden ser la predicción
de las ventas, posibles problemas financieros, similitudes
de necesidades de los clientes y un sinfín de predicciones
que el negocio requiera.
Las herramientas para visualizar, examinar y realizar el
análisis de los resultados.
2.12. Reseña histórica del Grupo Flayp
En el año 1.983 tras el cierre de las actividades en Paraguay de la
Multinacional AVON Cosmetics Inc., se crea Flayp S.R.L., con el objetivo
de convertirse en una empresa nacional para la venta y distribución de los
productos AVON, adquiriendo para esto la franquicia de dicha marca, tiene
Page 48
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 48
como visión ser la empresa líder en venta directa y comercialización de
artículos de belleza, llegando a cada rincón del Paraguay, ofreciendo
calidad y excelencia a sus clientes.
En sus inicios contaba con 5 empleados y 120 revendedoras. En la
actualidad la empresa Flayp S.R.L. se transformó en el Grupo Flayp,
compuesto por las siguientes empresas: Flayp S.R.L.; Virú S.R.L.;
Flayprint S.A.; City Sport S.A.; Cima Seis S.A.; Flaypnort S.A., las cuales
si bien están nucleadas en un directorio, son totalmente independientes
administrativa, económica y operativamente entre sí.
Hoy en día el Grupo Flayp cuenta con más de 700 empleados
directos y más de 30.000 revendedoras a lo largo de todo el país. A más del
directorio, compuesto actualmente por sus 6 miembros fundadores, el
Grupo cuenta con un gerente general, y para cada una de las empresas un
gerente en cada área estratégica (Marketing, Ventas, Compras,
Administrativo, Logística, Tecnología e Información).
En cuanto a tecnología, el Grupo cuenta en la actualidad con 5
servidores, 2 de los cuales son utilizados para albergar en forma
independiente cada uno de los sistemas de procesamiento de pedidos,
facturación y cuenta corriente de cada una de las empresas, dichos
sistemas informáticos se encuentran desarrollados en distintos lenguajes de
programación y distintos orígenes de datos, además de eso, cuenta con una
conexión Virtual Private Network (en adelante VPN), con muchas de las
sucursales en el interior del país y el área metropolitana, las cuales realizan
sus transacciones directamente a las bases de datos contenidas en los
servidores, las agencias que no cuentan con acceso a internet, envían sus
Page 49
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 49
pedidos utilizando los vehículos de la empresa, dichos pedidos son
procesados en un centro de procesamiento.
Actualmente el Grupo Flayp maneja un volumen de compras
cercano a los 10.000.000 u$s anuales (comprende las dos principales
empresas del Grupo; Virú S.R.L. y Flayp S.R.L.) y un volumen de ventas
que ronda los 24.000.000 u$s anuales. En cuanto a unidades vendidas, las
mismas superan los 7.000.000 anuales. Con una proyección de crecimiento
entre el 10% y el 14% anual. El Grupo Flayp cuenta con una casa central
en Asunción, además de contar con más de 45 agencias distribuidas en
todo el país, logrando así una cobertura total, posee 2 depósitos que
albergan las mercaderías, además de una flota de camiones, los cuales son
utilizados para la distribución de los productos.
El Grupo empresarial cuenta con un equipo de ventas, liderados por
su gerente de ventas, quien tiene a su cargo a 4 gerentes divisionales, los
cuales se dividen la cobertura del país en 4 grandes regiones, además
cuenta con más de 350 zonas, las cuales están distribuidas en cada una de
las 4 divisiones y que su vez se encuentran presentes en todos los
departamentos del país, cada zona es gerenciada por una promotora de
ventas y que a su vez tienen a su cargo el manejo de las 30.000
revendedoras. Por otro lado cabe mencionar que el sistema de venta directa
tiene una dinámica diferente a la venta convencional, el mismo consiste en
ofrecer sus productos a través de folletos los cuales son ofrecidos por las
revendedoras, la vigencia promedio de cada folleto es de 18 días, esto lleva
a tener 20 folletos por año, que son denominadas campañas, por lo tanto la
facturación se maneja por campañas y no así por fecha calendario. De esto
se desprende que toda la información que manejan las empresas del
grupo, corresponden a este esquema organizacional.
Page 50
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 50
2.13. Reseña histórica del software libre
En los primeros pasos de la informática, los programas y las
máquinas utilizadas para su ejecución estaban estrechamente ligados. No
se concebía el concepto de programa como elemento separado tal cual se
tiene hoy en día.
Tampoco existían usuarios comunes, sino que la totalidad de las
personas que ejecutaban los programas tenían grandes conocimientos de
programación y por lo general eran ingenieros y científicos, una costumbre
muy practicada entre estos usuarios, era intercambiar y mejorar los
programas, distribuyendo sus modificaciones.
No fue hasta los últimos años de la década del 70, cuando las
empresas comenzaron con la costumbre de imponer restricciones a los
usuarios, con la implementación de los acuerdos de licencia.
2.13.1. Richard Stallman y el proyecto GNU
Para empezar a entender todo lo que implica el software
libre, es imprescindible hablar de Richard Stallman. Este físico
graduado en 1.974 en la Universidad de Harvard, se encontraba
trabajando en los laboratorios de inteligencia artificial del
Instituto de Tecnología de Massachussetts(en adelante MIT)
desde el año 1.971.
Page 51
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 51
La impresora con la que contaban en su laboratorio tenía
algunos inconvenientes con la alimentación del papel, lo que
hacía que se atascara de forma permanente y no había forma de
descubrirlo más que acercarse hasta donde se encontraba la
misma.
Por este motivo, Stallman contacta con la empresa
fabricante de la impresora, con el propósito de modificar el
software que se encargaba de controlar a la impresora y lograr
hacer que la misma mande una señal cuando se atascaba,
consiguiendo con esto que no se perdiese tanto tiempo de trabajo.
Ante este pedido, los fabricantes se negaron a entregarle el
código fuente, los cuales son imprescindibles para poder
modificar su comportamiento. Esta situación hace que termine de
tomar forma su idea de que el código fuente de los programas
debía ser accesible para todo aquel que quisiese.
Movilizado por esta inquietud, Stallman decidió
abandonar el MIT a comienzos de 1.984, para dar inicio al
proyecto GNU, el mismo es un acrónimo recursivo que significa
GNU's Not Unix, GNU No Es Unix, haciendo referencia a que el
proyecto tenía como objetivo desarrollar un sistema operativo tipo
Unix, pero totalmente libre.
Tiempo después Stallman funda la Free Software
Foundation (en adelante FSF), entidad encargada de promocionar
el desarrollo y uso del software libre, en 1.985 Stallman creó la
Page 52
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 52
licencia General Public License (en adelante GPL) como
mecanismo para proteger el software libre, sustentado sobre el
concepto de copyleft, la FSF tiene un registro de todas licencias
compatibles con la licencia GNU (la más popular de las licencias
de software libre) y aquellas que, no siendo compatibles con ella,
son consideradas licencias de software libre.
En sus comienzos, el proyecto GNU se concentra en
desarrollar las herramientas necesarias para construir un sistema
operativo, como ser editores y compiladores y en las utilidades
básicas para la gestión del sistema.
A través del concepto de copyleft, se busca una alternativa
a la idea del copyright, siendo que “todo el mundo tiene derecho a
ejecutar un programa, copiarlo, modificarlo y distribuir las
versiones modificadas, pero no tiene permiso para añadir sus
propias restricciones al mismo”. De esta forma, las libertades que
definen al software libre están garantizadas para todo el mundo
que tenga una copia, tornándose en derechos inalienables.
2.13.2. Software Libre
Lo primero que debe entenderse cuando se habla
desoftware libre, es que no se está hablando de software gratis, el
alcance de la palabra libre es mucho más abarcativa, se refiere a la
libertad de los usuarios para ejecutar, copiar, distribuir, estudiar,
cambiar y mejorar el software. De modo más preciso, se refiere a
cuatro libertades de los usuarios del software. (GNU, 2008).
Page 53
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 53
Es entonces que se tiene dentro de las distintas
clasificaciones de software, una muy determinante, como lo es
clasificar al software de acuerdo a su “filosofía”.
Softwarepropietario: se entiende por esto, el software cuya
propiedad absoluta continua en poder de quien tiene sus derechos
y no del usuario, quien solo puede utilizarlo cumpliendo ciertas
condiciones. Siendo así que su uso, distribución y/o modificación
total o parcial, están prohibidos o restringidos de tal manera que
no es posible llevarlos adelante. Es decir, que el software
comercializado bajo este tipo de licencias le da al usuario
derechos limitados sobre su usufructo, el alcance de esto es
establecido por el autor o quien posea ese derecho.
Software libre: se considera así, al software que le otorga
al usuario la libertad de utilizarlo, mejorarlo, estudiarlo, adaptarlo
a sus necesidades y redistribuirlo libremente, con la única
limitación de no sumarle ningún tipo de restricción agregado al
software luego de modificado. Es importante destacar que para
considerar a un software como libre, se debe permitir el acceso al
código fuente, por cuanto esto es una condición imprescindible
para ejercer las libertades de estudiarlo, modificarlo, mejorarlo y
adaptarlo (FSF, 2009).
Cuando se habla de softwarelibre es necesario hacer
mención a las cuatro libertades básicas de su filosofía según la
Fundación de Software Libre.
Page 54
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 54
2.13.3. Libertades básicas del software libre
Libertad cero: “usar el programa con cualquier propósito”.
Esta libertad es la que garantiza que se puede utilizar el programa
para cualquier fin, sea este comercial, educativo, cultural, etc.
Esta libertad está en contraposición a las licencias que limitan la
utilización del software a un propósito determinado, o que
restringen su uso para ciertas actividades.
Libertad uno: “Estudiar cómo funciona el programa, y
adaptarlo a nuestras necesidades”. Esto se traduce en que se puede
estudiar el funcionamiento (para ello se debe tener acceso al
código fuente del programa) lo que permitirá, descubrir
funcionalidades ocultas, conocer de qué manera realiza
determinada tarea, averiguar que otras opciones tiene, que más se
le puede agregar, etc. El hecho de poder adecuar el programa,
implica que se pueden eliminar partes que no se necesitan,
agregarle elementos que se consideren importantes, etc.
Libertad dos: “Distribuir copias”. Esto quiere decir que se
tiene la libertad redistribuir el programa, ya sea de forma gratuita
o cobrando por el servicio, pudiendo realizar esto por e-mail, CD,
o algún medio de almacenamiento, ya sea a una persona o a
varias, etc.
Libertad tres: “Mejorar el programa, y liberar las mejoras
a todos”. Por esto se entiende que se tiene la libertad de mejorar el
programa, traduciéndose esto en menores los requerimientos de
Page 55
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 55
hardware para funcionar, un software con mayores prestaciones,
que ocupe menos espacio en disco, etc.
2.13.4. Software libre y software de código abierto
Barahona, Seona y Robles (2.008) señalan que Open
Source como Free Software en realidad son movimientos sociales,
motivados por lo que se puede o se debería poder hacer
(derechos) con los programas (software). Entre estos dos
movimientos existen diferencias filosóficas pero realmente pocas
diferencias prácticas.
La primera diferencia que existe entre estos movimientos,
radica en la visión que tienen del software, Free Software tiene
una visión moral “el software debería ser libre” Open Source tiene
una visión práctica “el software es mejor si su código es abierto“.
Free Software en realidad hace referencia a software libre
(de ninguna manera a software gratis) y está sustentado en
fundamentos morales. Las libertades en las que basa su
concepción hacen referencia que puedas utilizar un programa,
pero que también puedas copiarlo, distribuirlo, estudiarlo o
modificarlo sin ningún tipo de restricción. Desde su punto de
vista, limitar cualquiera de estas libertades es inmoral.
Open Source por su parte se refiere a la limitación de
acceso al código fuente del software, el hecho distribuir el código
Page 56
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 56
fuente del software alienta, según los promotores del open source,
un software de mayor calidad, más seguro y creativo, el cual
evoluciona de forma más ágil y está orientada a satisfacer las
necesidades de sus usuarios.
En algo en lo cual coinciden tanto Free Software como
Open Source es que ambos no ponen reparos en que la gente
venda software, eso sí, lo que se vende no es la licencia del
software en sí, sino que se vende el servicio de entregar el
software (muchas veces se vende empaquetado, con manuales,
instalado u otro valor agregado).
Para los dos movimientos, ante la venta de un softwarede
desarrollo propio o desarrollado por otros, no se puede restringir
al comprador, para que éste no pueda a su vez venderlo o
inclusive regalarlo y debe entregarse el código fuente y permitir
su modificación, para poder ser considerado Free Software u
Open Source.
Se entiende por licencias de software al contrato existente
entre dos personas (proveedor y usuario) en el cual se describen y
puntualizan los derechos y deberes sobre el uso que se le puede
dar al software.
Aunque ciertamente, Open Source y Software Libre tienen
prácticamente las mismas licencias, la FSF opina que el
movimiento Open Source es filosóficamente diferente del
movimiento del Software Libre. La Open Source Initiative(en
Page 57
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 57
adelante OSI) surgió en el año 1.998, en ese entonces un grupo de
personas encabezados por Eric S. Raymond y Bruce Perens
buscan otorgar mayor importancia a los beneficios en que
redundaría el hecho de compartir el código fuente de los
programas, como así también lograr captar el interés de las
grandes casas de software y otras empresas de la industria de la
alta tecnología en ese rumbo.
La visión que tienen ambos movimientos, es una de las
principales diferencias, mientras que el movimiento del software
libre pone el foco en los aspectos éticos o morales del software,
dejando a un segundo plano la excelencia técnica siendo su mayor
deseo el plano ético. En tanto movimiento Open Source centraliza
más su mirada hacia la excelencia técnica como el principal
objetivo, basándose en el hecho compartir el código fuente un
medio para lograr dicho fin.
Un punto a tener en cuenta es que el software en sí mismo,
no es ni Free Software ni Open Source, solo la licencia del
software es la que puede ser reconocida por ambos movimientos
como válidas para sus fines. De hecho las mayorías de las
licencias aceptadas por uno de los movimientos son aceptadas por
el otro.
Aunque habitualmente los términos “software libre” y
“código abierto” son intercambiados fácilmente entre sí, no
significa que ambos términos sean equivalentes.
Page 58
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 58
2.13.5. Tipos de licencias de software libre
La licencia de software libre más utilizada es la GNU
General Public License (GPL), está presente en diversos
productos de software libre en sus versiones 2 y 3. Este tipo de
licencias a más de las cuatro libertades básicas del software libre
agrega una cláusula de “efecto viral”, gracias a la cual es posible
aunar varios productos de software exclusivamente si todos estos
utilizan la licencia GPL.
Ciertamente la licencia GPL no es la única licencia de
software libre. Existen muchas otras licencias derivadas de la
GPL como por ejemplo la Lesser General Public License(en
adelante LGPL) y la Affero GNU Public License(en
adelanteAGPL). La LGPL permite que el software bajo esta
licencia pueda utilizar librerías de licencia privativas (en esto se
diferencia de la GPL, con la cual puede utilizarse solo software
que tiene licencia GPL). Mientras que la AGPL dirigida al campo
del software ofrecido como servicio, y su principal característica
práctica está en el hecho de que, si un tercero utiliza el software
para brindar un servicio a varios usuarios y realiza modificaciones
al código original, está en la obligación de publicar dicho código
fuente.
Por el lado de las licencias de código abierto que
abiertamente no son licencias de software libre, ya que no son
compatibles con las libertades y principios básicos del software
libre de la GPL se puede mencionar a la Common Public
Attribution License Version 1.0 (en adelante CPAL). Esta licencia
admite el uso y la modificación del código fuente, siempre y
Page 59
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 59
cuando se haga referencia al creador original del software, y por
tanto no podría ser utilizada por algún competidor.
Page 60
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 60
CAPÍTULO 3– MARCO METODOLÓGICO
3.1. Descripción de la profundidad y el diseño de la Tesis:
La investigación llevada a cabo para la realización del proyecto se
basó en un estudio descriptivo, se revisó exhaustivamente la literatura
existente relacionada, con el fin de obtener la información necesaria para
dar inicio al proyecto. Durante la investigación se recabo cuantiosa
información sobre las empresas Flayp S.R.L. y Virú S.R.L., pertenecientes
al Grupo Flayp, como así también acerca de la Inteligencia de Negocios,
software libre, open source, etc., y sobre todo las herramientas a utilizar
para el diseño y desarrollo del proyecto, las cuales sirvieron para llevar
adelante la tesis.
La presente tesis está basada en un diseño cualitativo, donde los
datos se describieron detalladamente teniendo en cuenta el objeto de
estudio. Patton (1.980), mencionado en el libro de investigación de
Hernandez Sampieri y Col (2.003).
Cabe destacar que para la realización del presente proyecto se
analizaron detalladamente todos los requerimientos y en base a los
conocimientos básicos, más las investigaciones realizadas, junto con los
relevamientos del sistema actual que se posee, además del hardware con el
que cuentan las empresas, se definió la solución que mejor se adecua al
contexto actual, para luego definir las etapas necesarias para llevar
adelante la realización de la tesis.
Page 61
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 61
3.2. Descripción de cómo se realizó la Tesis
Para el desarrollo de la tesis, se optó por el modelo de ciclo de vida
en cascada ya que es este, el que mejor se adapta a la realización del
proyecto de tesis.
En este sentido, “[…] el modelo en cascada, algunas veces
llamado el ciclo de vida clásico, sugiere un enfoque sistemático,
secuencial hacia el desarrollo del software, que se inicia con la
especificación de requerimientos del cliente y que continúa con la
planeación, el modelado, la construcción y el despliegue, para culminar
en el soporte del software terminado”(Pressman, R.2005:50).
El mismo consiste en el ordenamiento secuencial de las etapas del
proceso para el desarrollo del software, teniendo en cuenta que debe
aguardarse la finalización de una etapa inmediatamente anterior, antes de
poder dar inicio a una siguiente etapa, de ser necesario pueden realizarse
retroalimentaciones de etapas anteriores, a fin de minimizar impactos
negativos. Las etapas definidas para este proyecto son las siguientes:
relevamiento de datos, análisis de datos, diseño, desarrollo, prueba e
implementación.
Para el análisis de los procesos se diseñó una WBS (Work
Breakdown Structure), donde se puede apreciar la descripción jerárquica
de los trabajos a realizar para la concreción de la tesis, la misma puede
observarse en el Anexo 1.
Page 62
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 62
3.2.1. Relevamiento de datos
Se concretaron reuniones con los miembros del directorio
del Grupo Flayp, de igual manera se realizaron entrevistas
personalizadas a los gerentes de cada área, se relevaron los
procesos realizados diariamente en los sistemas operacionales por
medio de observaciones de los manuales de procesos; gracias a
las entrevistas realizadas a los gerentes, se definieron los criterios
que son utilizados para la toma de decisiones, de manera a poder,
a través de la concreción del proyecto, brindar un soporte para
optimizarla toma de dichas decisiones.
En cuanto a software, se observó el funcionamiento de los
sistemas actualmente utilizados, y la manera en la que estos
interactúan con todas y cada una de las áreas de las empresas, en
esta instancia se relevó con especial atención todo lo que respecta
a la estructura de datos, así también la infraestructura base en
cuanto a softwarey hardware existente.
3.2.2. Análisis de datos
Una vez finalizada la tarea de relevamiento de datos, y ya
con toda la información necesaria, se llevó a cabo un análisis
minucioso de las necesidades e inquietudes de los futuros
usuarios del sistema, esto más la información sobre la tecnología
con la que se cuenta, nos dio las bases para definir que la mejor
opción que se adecua a dichas necesidades radica en la
Page 63
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 63
implementación de una solución de Inteligencia de Negocios, ya
que dicha solución brindará un soporte para la toma de decisiones
estratégicas, como así también brindar una visión macro de ambas
empresas en conjunto, que será de mucha utilidad para los altos
niveles ejecutivos, ya que los datos se encuentran dispersos en
diferentes formatos de almacenamiento, lo que dificulta la
realización de análisis, para lo cual no se trabajará de manera
directa con las bases de datos transaccionales.
La utilizaciónde un data warehousepermitirá cohesionar
los datos de las distintas fuentes, la misma se desarrollará
íntegramente sobre softwarelibre, se llegó a esta conclusión luego
de analizar detenidamente las soluciones propietarias existentes
en el mercado, los requerimientos tanto de software como de
hardware que son necesarios para la implementación de la
solución, son altamente compatibles con los que ya se cuentan, se
prevén todas las medidas de seguridad en aplicaciones web,
también se harán uso de las nuevas tecnologías existentes, con el
fin de optimizar y agilizar el acceso a los datos en considerables
niveles de tiempo.
3.2.3. Diseño
Con el afán de obtener un prototipo coherente que
satisfaga los requerimientos relevados y analizados en etapas
anteriores, se llevó a cabo el diseño conceptual, lógico y físico del
prototipo de solución de Inteligencia de Negocios, comenzando
por el data warehouse, los procesos de ETL, reportes, cubos
multidimensionales, cuadros de mandos y demás componentes,
Page 64
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 64
como ser la arquitectura de la herramienta y del prototipo en el
contexto general.
3.2.4. Desarrollo
Ya con toda la documentación resultante de la etapa de
diseño, se procedió a desarrollar el proyecto, se inició con el
desarrollo el data warehouse, cuyo objetivo es unificar los datos
obtenidos de las distintas fuentes transaccionales, para ello se
eliminan las ambigüedades e inconsistencias, a través de un
proceso de extracción, transformación y cargado de los datos en
eldata warehouse. Se diseñaron y publicaron en el servidor los
cubos OLAP, los cuadros de mando, los reportes y el resultado de
la minería de datos, para lo cual se aplicó el algoritmo
seleccionado.
Se configuró e implementó el servidor, para que los
usuarios puedan acceder a los distintos módulos, ya sean estos de
reportes, análisis, etc., asítambién se otorgaron los privilegios
necesarios a los informes y a las carpetas contenedoras. Se
configuró e implementó la consola de administración, de manera
tal a poder administrar tanto los usuarios como los roles
asignados. En cada una de las etapas de configuración e
implementación del proyecto, se tomaron en cuenta todas las
políticas y estándares de seguridad en cuanto a aplicaciones
cliente-servidor se refiere, como ser, manejo de sesiones,
administración de perfiles, permisos de usuario, etc.
Page 65
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 65
3.2.5. Prueba
Se realizaron las pruebas correspondientes, se
corroboraron los resultados obtenidos, si cumplen con los
requerimientos y la fiabilidad de los mismos, además se
realizaron pruebas exhaustivas en cuanto a concurrencia de
acceso al sistema, conectividad, tiempo de respuesta, nivel de
seguridad, etc.
3.2.6. Implementación
Los componentes del prototipo de la solución, se
instalaron y configuraron en una máquina preparada para actuar
de servidor, el mismo está compuesto por, la consola de
administración de Pentaho, el servidor Pentaho, los componentes
de Pentaho Data Integration (en adelante PDI) y se configuró la
periodicidad de la actualización del data warehouse, y el Sistema
Gestor de Base de Datos (en adelante SGBD) MySQL, donde se
almacenará el data warehouse, así también se crearon los perfiles
de usuario, con la asignación de roles y permisos
correspondientes, se configuraron los ordenadores-cliente para
acceder al sistema.
Page 66
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 66
3.3. Descripción de los instrumentos y procedimientos utilizados para la
recolección y tratamiento de la información
Para la elaboración de este proyecto se recolectaron los datos a
través de entrevistas semi-estructuradas a directores y gerentes del Grupo
Flayp,para obtener los permisos para acceder a la información, procesos y
los reportes necesarios para la toma de decisiones.
También se realizaronobservaciones directasde los distintos
procesos y sistemas operacionales automatizadosa fin de elaborar reportes
de requerimientos.
3.4. Descripción de la muestra
Para la realización de este proyecto, luego de un análisis de la
población, se optó por llevarlo adelante en las empresas del Grupo Flayp,
concretamente Viru S.A y Flayp S.R.L., en los departamentos de Ventas y
Marketing, la selección de las empresas y los departamentos se realizó
gracias a la buena predisposición e interés de los directivos de contar con
una herramienta que ayude a la toma de decisiones.
Las entrevistas se realizaron a los gerentes de Compras, Ventas,
Marketing, Finanzas y un director de las empresas seleccionadas. También
se realizaron observaciones directas de los distintos procesos y sistemas
operacionales automatizados.
Page 67
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 67
En el Anexo 2 se presentan los esquemas de las entrevistas y
observaciones utilizadas para la recolección de datos.
3.5. Relevamiento
A continuación se describen todos los datos relevados para la
realización del proyecto de tesis.
3.5.1. Relevamiento de procesos
Se relevaron los procesos de ambas empresas, Flayp
S.R.L. y Virú S.R.L. Teniendo en cuenta que estas dos empresas
forman parte de un grupo empresarial razón por la cual rinden
cuenta a un directorio, pero son tanto financieras, económica y
administrativamente totalmente autónomas. Seguidamente se
detallan los procesos de la empresa Virú S.R.L.
Proceso de Planificación de Ventas: El departamento de
Marketing, basándose en datos históricos, épocas del año,
y/o acontecimientos especiales de mercado (Mundial,
Copa América, etc.), planifica cada folleto de ventas, en
función a productos y precios, como así también realiza
las estimaciones de ventas de cada producto, por ultimo
genera un listado donde se detallan los productos que
serán promocionados en dicho folleto de ventas, el cual es
enviado al departamento de Tecnología de Información
Page 68
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 68
(en adelante TI) Este proceso tiene una duración
aproximada de 10 días, el mismo se realiza utilizando
planillas de cálculo. El resultado de este proceso, se
exporta a un archivo csv, que posteriormente es
almacenado en un sistema basado en archivos dbf.
Proceso de Compras: El departamento de Compras
utilizando las estimaciones de ventas del departamento de
Marketing y cotejando el stock de los productos existentes
en el depósito, calcula que productos se deben comprar y
las cantidades necesarias para cada folleto de ventas. De
ser necesario, emite la orden de provisión para realizar las
compras tanto para proveedores locales como
internacionales.
Proceso de Recepción de Productos: El departamento de
Stock recibe y da entrada a los productos comprados,
asignándole un lugar determinado dentro del depósito. El
mismo proceso se realiza en el módulo de stock del
sistema, actualizando de esta manera el mismo.
Proceso de Distribución de materiales de venta: El
departamento de Logística recibe de la imprenta, los
materiales, consistentes en folletos y órdenes de compra y
los envía a las distintas agencias, las promotoras de venta,
retiran de su agencia estos materiales, para luego
redistribuirlos a sus revendedoras.
Proceso de Recepción de Pedidos: Cada promotora recibe
de sus revendedoras las órdenes de compra, donde se
detalla los productos y sus cantidades.
Proceso de Pedidos: Las órdenes de compras, las cuales
contienen los datos de la revendedora y su pedido para la
campaña actual, se procesan en el módulo de pedidos del
sistema, el cual genera los packinglist, a ser utilizados por
el departamento de stock para la preparación de los
Page 69
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 69
pedidos. Existen dos maneras de procesamiento, las
agencias que cuentan con conectividad VPN y por ende
acceso al sistema, el procesamiento se realiza en la
agencia misma, y las agencias que no cuentan con VPN
envían las órdenes de compras al departamento de TI para
su procesamiento.
Proceso de Packing: El departamento de stock utilizando
los packinglist generados por el departamento de TI, los
cuales están compuestos por los datos de las revendedoras
y su pedido correspondiente, prepara los paquetes con los
productos solicitados, con los cuales se cuenta en
existencia, indicando en el sistema, con que productos no
se contaba con stock al momento de la carga del paquete,
para poder de esta manera actualizar el packinglist del
pedido original en función a los productos a ser enviados y
generar la factura correspondiente, estos paquetes se
cargan y se etiquetan para su distribución en las distintas
agencias. Todo esto se almacena en el módulo de
procesamiento de pedidos del sistema.
Proceso de Distribución de Pedidos: El departamento de
logística toma los paquetes que corresponden a cada
pedido preparado en el proceso de packing, prepara y
envía las cajas con los pedidos solicitados por las
revendedoras, utilizando para ello los transportes de la
empresa, de acuerdo a la agencia que corresponda, para
ser retirada por las revendedoras.
Proceso de parametrización de Procesamiento de Pedidos:
El departamento de TI recibe del departamento de
Marketing, un listado donde se detalla que productos serán
publicados, con sus respectivos precios y códigos en cada
folleto de venta, de acuerdo a este listado se modifica el
sistema de procesamiento de órdenes de compras,
Page 70
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 70
estableciendo códigos y precios, este proceso se realiza ya
que los códigos y precios de los productos varían de
acuerdo a cada folleto.
Proceso de Cobranzas: Las bocas de cobranzas situadas en
cada agencia, se encargan del cobro a las revendedoras,
quienes deben saldar su cuenta anterior de manera a poder
retirar su pedido con los productos y la factura
correspondiente, la cual genera una nueva obligación para
con la empresa, la misma deberá ser cancelada al
momento de retirar los productos del folleto siguiente,
cabe mencionar que las consejeras operan a crédito por
campaña.
Proceso de Entrega de Pedidos: Con la deuda anterior
saldada, la revendedora retira su pedido con los productos
facturados.
Proceso de Reportes: El departamento de TI prepara
consultas para los distintos SGBD (ventas, pedidos, etc.),
por demanda de cada uno de los departamentos, estos
utilizan dichas consultas y preparan de manera manual los
informes gerenciales, utilizando para ello herramientas de
ofimáticas como Excel, Power Point etc., normalmente la
generación de los reportes tiene un alto costo en recursos
y tiempo, además el resultado no siempre es el esperado
ya sea por fallas en la comunicación de necesidades o
errores humanos en la confección.
Estos mismos procesos se llevan a cabo en la empresa
Flayp S.R.L., con la única diferencia de que esta opera con un
solo proveedor que es AVON Internacional, ya que la relación es
de franquicia.
Page 71
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 71
3.5.2. Relevamiento de Estructura de Datos
En esta etapa se relevaron las bases de datos de los
sistemas operacionales de las dos empresas, donde Flayp S.R.L.
utiliza MySQL, el cual es un gestor de base de datos relacional.
Por su parte Virú S.R.L. almacena su información en archivos
planos del tipo dbf.
A partir de estos relevamientos se obtuvieron las
estructuras de datos de los sistemas operacionales de ambas
empresas.
3.5.3. Relevamiento de Necesidades
En función de los procesos relevados de ambas empresas,
se observó que las mismas no cuentan con un sistema de reportes
y análisis eficiente que ayuden a optimizar la toma de
decisiones.De igual manera no cuentan con un sistema de reportes
consolidado de ambas empresas, siendo esto necesario ya que las
dos empresas pertenecen al mismo grupo empresarial, donde
contar con un sistema de información macro es sumamente
importante. Para lo cual es fundamental poder unificar los datos
con los que ya se cuenta en formato digital, de manera a eliminar
inconsistencias e integrar los mismos.
Page 72
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 72
3.5.4. Relevamiento tecnología actual del Grupo Flayp
En la tabla 2, puede observarse la infraestructura con la
que cuentan actualmente las empresas Flayp S.R.L. y Virú S.R.L.
Tabla 2: Infraestructura actual de las empresas.
3.5.5. Relevamiento Sistemas gestores de Bases de Datos
Microsoft SQL Server:es un Sistema Gestor de Bases de
datos relacionales (SGBD), el mismo tiene como base el lenguaje
Transact Structured Query Language(en adelante T-SQL), entre
Flayp S.R.L. Virú S.R.L.
Software
Aplicativo
Sistema escrito en
lenguaje PHP/HTML,
datos almacenados en
MySQL.
Sistema escrito en CA-Clipper,
utilizando FlagShip como
compilador, datos almacenados
en dbf.
S.O. Servidor Linux Mandriva 2.008 Linux Mandriva 2.008
Sistema Operativo
Cliente
Ubuntu 10.04 Ubuntu 10.04
Hardware
Servidor
Zeus
Dell PowerEdge 2900.
Procesador: Intel Xeon
2,33Ghz 64 bits.
Memoria: 4Gb.
HD: 500Gb (RAID por
hardware).
Apolo.
Dell PowerEdge 2900.
Procesador: Intel Xeon 3,0Ghz
64 bits.
Memoria: 4Gb.
HD: 100Gb (RAID por
hardware).
Hardware
Cliente
Maquinas Clon Maquinas Clon
Page 73
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 73
otras características que posee, es rápido, es multiusuario y es
capaz de manejar grandes transacciones de datos. El Transact-
SQLes un lenguaje de programación que difiere de otros
lenguajes, ya que en su mayoría, en estos lenguajes se escriben
grandes cantidades de códigos para luego ser compilados en un
archivo ejecutable, pero con el lenguaje T-SQL no sucede esto, ya
que este es más un lenguaje de control y manipulación de datos
que de programación en sí. El T-SQL no es “case sensitive” (no
hace diferencias entre mayúsculas y minúsculas) y tiene como
base el estándar SQL-92, que es el que estandariza el lenguaje
Structured Query Language(en adelante SQL), y sirve de guía
para todos los sistemas gestores de bases de datos, haciendo más
fácil la compatibilidad entre los diferentes productos que se
ofrecen en el mercado.
En el Microsoft SQL Server se pueden considerar
características tales como:
Soporta transacciones.
Soporte de procedimientos almacenados.
Seguridad, estabilidad y escalabilidad.
Interfaz gráfica de administración, que facilita el uso de
comandos DDL (Data Definition Language) y DML
(Data Manipulation Language) gráficamente.
Modo cliente-servidor (La información se aloja en el
servidor y solo los clientes acceden a esta).
Administración de información de otros servidores de
datos.
Page 74
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 74
Este gestor también tiene una versión más estándar, que
utiliza el mismo motor de base de datos, aunque destinado a
proyectos más pequeños, que para las versiones 2.005 y 2.008 es
la SQL Express Edition, que se distribuye de una manera gratuita.
MySQL Server: es un sistema de gestión de bases de datos
relacional, con la característica de ser multiusuario. El mismo está
desarrollado bajo licencia de software libre en un esquema de
licenciamiento dual. Existe una versión que se ofrece bajo la
GNU GPL destinada a cualquier uso que sea compatible con este
tipo de licencia, y para el caso de aquellas empresas que quieran
utilizarlo en productos privativos deben adquirir de la empresa
una licencia específica que les permita hacer esto. MySQL
SERVER se encuentra desarrollado en su mayor parte en ANSI C.
A diferencia de otros proyectos, donde el software es
desarrollado y mantenido por una comunidad pública y los
derechos de autor del código fuente se encuentran en manos del
autor, MySQL es patrocinado por una empresa privada, que posee
el copyright de la mayor parte del código.
Esta situación es la que ofrece la posibilidad del esquema
de licencias dual. Aparte de la comercialización de las licencias
privativas, la compañía también ofrece soporte y servicios.
En el MySQL Server podemos considerar características
como:
Page 75
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 75
Uso de multihilos mediante hilos del kernel.
Tablas hash en memoria temporales.
Soporta operadores y funciones en cláusulas select y
where.
Soporta cláusulas group by y order by, soporte de
funciones de agrupación.
Gestión de contraseñas y privilegios utilizando
verificación basada en el host y el tráfico de contraseñas
está cifrado al realizar una conexión al servidor.
Soporta gran cantidad de datos.
Permite un máximo de 64 índices por tabla, cada uno de
los cuales puede consistir desde 1 hasta 16 columnas o
partes de columnas. El máximo ancho de límite son 1.000
bytes.
Los usuarios se conectan al servidor MySQL usando
sockets TCP/IP en cualquier plataforma.
3.5.6. Relevamiento algoritmo de minería de datos
A continuación se describen los métodos y algoritmos
predictivos que se pueden aplicar a la minería de datos.
Métodos predictivos: estos métodos tienen como objetivo
describir una o más variables en relación a las demás,
también es conocida como método asimétrico,
supervisado o directo. Este tipo de método ayuda a la
predicción o clasificación de acontecimientos futuros de
una o más variables en relación a lo ocurrido teniendo en
cuenta los motivos que lo causa o directamente en relación
Page 76
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 76
a las variables que se utilizan como entrada. Los
principales métodos de este tipo son las redes neuronales
(arboles de decisiones y perceptrón de multicapa),
modelos estadísticos clásicos, modelos de regresión lineal
y logística.
Métodos descriptivos: permiten agrupar datos
rápidamente, conocidos también como métodos simétricos
no supervisados o indirectos. Realiza la clasificación sin
que en el momento de realizar las observaciones se tenga
conocimientos de las clases asociadas, su objetivo es
descubrir estas asociaciones, contornos y agruparlos.
El algoritmo de regresión lineal es un método que modela
la relación entre una variable dependiente Y, las variables
independientes Xi y un término aleatorio ε. Regresión lineal por
mínimos cuadrados, es una técnica cuyo objetivo es derivar una
curva que minimice la discrepancia entre los puntos y la curva, la
formula general esy=m+b.
Donde los valores de m y b se determinan al resolver el
siguiente sistema de ecuaciones.
b.n+ m∑x = ∑y
b∑x + m∑x2 = ∑xy
Page 77
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 77
En la tabla 3 se muestran los datos de ejemplo para dicha
ecuación:
Tabla 3: Datos de ejemplo
El backpropagationes un algoritmo de aprendizaje
supervisado que se usa para entrenar redes neuronales artificiales.
El algoritmo consiste en minimizar un error (comúnmente
cuadrático) por medio de descenso de gradiente, por lo que la
parte esencial del algoritmo es cálculo de las derivadas parciales
de dicho error con respecto a los parámetros de la red neuronal.
Para ello se requiere que especifiquen los valores de la salida que
se asocien a ciertos tipos de entradas. En la tabla 4 se describe en
detalle dicho algoritmo.
Pasos Descripción
Adelante
Tras inicializar los pesos de forma aleatoria y con valores pequeños, selecciona el
primer par de entrenamiento.
Calculamos la salida de la red.
Calculamos la diferencia entre la salida real de la red y la salida deseada, con lo
que obtenemos el vector de error.
Atrás
Ajustamos los pesos de la red de forma que se minimice el error
Repetimos los tres pasos anteriores para cada par de entrenamiento hasta que el
error para todos los conjuntos de entrenamiento sea aceptable.
Tabla 4: Descripción del algoritmo backpropagation
Campaña (n) X Y X2 XY
1 1 77 2 77
2 2 88 4 176
3 3 96 6 288
4 4 100 8 400
5 5 132 10 660
6 6 160 12 960
Sumatoria21 653 42 2561
∑X=21 ∑Y=653 ∑X2=42 ∑XY=2561
Page 78
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 78
3.5.7. Relevamiento de sistemas operativos
Sistema operativo Linux: es un sistema operativo de
código abierto de libre distribución y compatible con UNIX, está
compuesto por el núcleo principal del sistema, conocido también
como kernel, además de un sinfín de programas y librerías que
hacen posible su funcionamiento.
Los sistemas operativos Linux concretamente están
basados en UNIX, el cual se desarrolló con la colaboración de
muchos programadores, unas de las ventajas en estos sistemas
operativos es que cualquier programador puede desarrollar nuevos
módulos o modificar las ya existentes de acuerdo a sus
necesidades, la distribución es gratuita, cuenta con amplia
posibilidades de configuración, mientras que entre las desventajas
lo más significativo es que se requiere de más tiempo para el
aprendizaje, lo cual es lógico si el usuario precisa configurar a
bajo nivel el sistema para mejorar el rendimiento, pero para un
usuario que solo utilizaría herramientas de ofimática el tiempo de
aprendizaje es lo mismo que en otros sistemas operativos .Entre
las características podemos mencionar, la capacidad de soportar
multitarea, multiusuario y multiplataforma.
Sistemas operativos Windows: a la familia de sistemas
operativos desarrollados y comercializados por Microsoft se le
denomina Windows, este como los otros sistemas operativos es el
encargado de hacer llegar las instrucciones realizadas por el
usuario al hardware a través del núcleo o kernel principal y
diversos programas y librerías que hacen posible su utilización,
son multitarea, multiusuario y multiplataforma, como una de las
Page 79
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 79
ventajas se puede mencionar lo intuitivo que es a la hora de su
utilización por personas con conocimientos básicos y la facilidad
de configuración, mientras que la desventaja más significativa
consiste en el alto costo en licencias al que se debe incurrir para
implementar, inestabilidad, limitaciones en configuración y
costoso en recursos de hardware.
3.5.8. Relevamiento de herramientas de Inteligencia de Negocios
En este apartado se realizó el relevamiento de algunas de
las soluciones de Inteligencia de Negocios disponibles en la
actualidad como son Michroestrategy, Pentaho, Jasper y Oracle.
MicroStrategy ReportingSuite:permite desarrollar y
proporcionar rápidamente una aplicación de reportes.
MicroStrategy Reporting Suitees una completa solución
para implementar sistema de inteligencia de negocios,
permitiendo la generación de cuadros de mandos, reportes,
análisis OLAP, análisis avanzado y predictivo, alertas y
notificaciones.
PentahoBusiness Intelligence Open Source: ofrece, con
soluciones propias, todo el espectro de recursos para
desarrollar, mantener y explotar un proyecto de
Inteligencia de Negocios, desde las ETL con Data
Integration, hasta los cuadros de mando con el Dashboard
Designer o el Comunity Dashboard Framework.La forma
como Pentaho ha construido su solución de Inteligencia de
Negocios es integrando diferentes proyectos ya existentes
y de solvencia reconocida. Data Integration anteriormente
Page 80
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 80
era Kettle, de hecho sigue conservando su antiguo nombre
como nombre coloquial. Mondrian es el otro componente
de Pentaho que sigue manteniendo entidad propia.
Jaspersoft: es la empresa que está detrás del famoso y
extendido JasperReports. Solución Open Source de
reportes. Jaspersoft ha construido su solución de
Inteligencia de Negocios en torno a su motor de informes.
Y lo ha hecho de una forma distinta a la de Pentaho.
Jasper ha integrado en sus soluciones, proyectos también
preexistentes y consolidados pero no los ha absorbido.
Esta estrategia le hace depender de Talend en cuanto a
solución ETL y de Mondrian – Pentaho para el motor
OLAP. Jasper tiene acceso al código de Mondrian y puede
adaptar y continuar los desarrollos en cualquier punto de
Mondrian.
Oracle Business Intelligence: esta es la suite más modesta,
muy accesible para pymes. Incluye todo lo necesario para
tener funcionando en poco tiempo un sistema de
Inteligencia de Negocios. Eso sí, se ha de instalar todo en
un servidor, y este ha de ser un Windows Server.La
licencia no permite utilizar más de dos CPU's del servidor
y sólo permite utilizar otra fuente de datos directa aparte
de la BD que incluye. El licenciamiento es
obligatoriamente por usuario nominal, y se pueden
licenciar entre 5 y 50 usuarios. La licencia es fácilmente
transformable a una Enterprise, ya que esta última incluye
el software de la Standard.
Page 81
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 81
3.6. Análisis
En este capítulo se presenta el análisis de los sistemas existentes,
en primer término se analizan todos los procesos, seleccionando los
inherentes al proyecto, de manera tal que cumpla con los requerimientos
relevados, también se muestra el modelo de los datos de los sistemas
operacionales y/o transaccionales, estos modelos agrupan a varios sub-
modelos que agrupan de forma lógica a las funcionalidades del sistema.
3.6.1. Análisis de requerimientos
A partir de las entrevistas realizadas a los miembros del
directorio y a los gerentes de cada área de ambas empresas, se
detectaron las dificultades con las que se encuentran en el
momento de obtener información de vital importancia para la
toma de decisiones, lo cual lleva a concluir en la necesidad de la
implementación de una solución de Inteligencia de Negocios, que
sea capaz de brindar reportes, por empresas y también un
consolidado de ambas empresas, como así también un análisis de
los datos históricos para predecir el probable comportamiento a
futuro de las ventas.
De igual manera, se tomó la decisión de
proporcionar a través de la implementación del prototipo, los
reportes a ser utilizados por los departamentos de Venta y
Marketing, esto se decidió en primera instancia, por pedido de los
miembros del directorio, ya que consideran que son los
departamentos a los que más beneficiará la solución de
Page 82
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 82
Inteligencia de Negocios, por otro lado, ambos departamentos se
nutren del mismo tipo de información, por lo cual se optimiza la
implementación del prototipo, debiéndose generar un solo grupo
de reportes para ambos departamentos. A continuación se detallan
los tipos de reportes analizados en detalle.
Venta por Campaña: visualiza gráficamente los resultados
de una o más campañas en función a tres variables
(facturación, unidades y pedidos), de una o ambas
empresas.
Venta por División: visualiza gráficamente los resultados
obtenidos por cada una de las divisiones, esto se puede
generar para una o más campañas, en función a tres
variables (facturación, unidades y pedidos), de una o
ambas empresas.
Venta por Departamento: visualiza gráficamente los
resultados obtenidos en cada uno de los departamentos,
esto se puede generar para una o más campañas, en
función a tres variables (facturación, unidades y pedidos),
de una o ambas empresas.
Venta por Quarter: visualiza gráficamente los resultados
de cada quarter (cada quarter se compone de 5 campañas,
1-5 1erQ, 6-10 2doQ, 11-15 3erQ y 16-20 4toQ) en
función a tres variables (facturación, unidades y pedidos),
de una o ambas empresas.
Top Salers: Visualiza gráficamente los productos más
vendedores de una o rango de campañas, en función a las
dos variables (facturación y unidades), se podrá generar:
consolidado general, por categoría, por división, por
departamento, por promotora.
Page 83
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 83
Ventas por Categoría: visualiza gráficamente el resultado
obtenido con cada una de las categorías.
Proyección de ventas: visualiza gráficamente el resultado
de una proyección basada en datos históricos y con la
aplicación de minería de datos. Se podrá obtener en
función a las dos variables (facturación y unidades).
3.6.2. Análisis de procesos
Contando con todos los procesos relevados, se procedió a
la clasificación de los mismos en función a los requerimientos de
la solución, estos se clasificaron de acuerdo a la organización
departamental del Grupo, la misma se detalla a continuación:
Marketing
— Planificación de Ventas
Compras
— Planificación de Ventas – Compras
Logística
— Recepción de Productos - Distribución de
materiales de venta
— Packing-Facturación-Distribución de Pedidos.
— Cobranzas - Entrega de Pedidos.
Tecnología de la Información
— Procesamiento de Pedidos – Reportes
Page 84
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 84
— Parametrización para Procesamiento de Pedidos.
Ventas
— Recepción de Pedidos
Posterior a la clasificación, se continuó con la selección de
los procesos intervinientes en los departamentos de TI y
Logística, seleccionando a su vez los inherentes al proyecto.
Tomando el proceso de procesamiento de pedidos del
departamento de TI y el proceso de facturación del departamento
de Logística.
Luego de llevar a cabo estos análisis, se llegó a la
conclusión que entorno a estos dos procesos seleccionados, se
llevara adelante el diseño del proyecto.
3.6.3. Análisis de estructura de datos
Se analizaron minuciosamente las estructuras de datos
provenientes de cada sistema de información, lo cual permitió
definir que tablas y datos serán necesarios para la realización del
prototipo, la misma puede visualizarse en detalle en el Anexo 3.
Page 85
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 85
3.6.4. Análisis de herramientas de Inteligencia de Negocios
Con todos los datos relevados sobre las herramientas de
Inteligencia de Negocios se realizó el análisis para la selección de
la herramienta en la cual se desarrollará este trabajo de tesis.
En la tabla 5 se presenta un cuadro comparativo de las
distintas herramientas mencionadas en el relevamiento.
Herramienta Permite ETL Reportes Minería de
Datos
Open Source
Oracle SI SI SI NO
Jasper SI SI NO SI
Pentaho SI SI SI SI
MicroStrategy SI SI SI NO
Tabla 5: Comparativa herramientas de Inteligencia de Negocios
Después de analizar minuciosamente cada componente las
opciones de suite de Inteligencia de Negocios, se llegó a la
conclusión de que Pentaho BI Suite es la que mejor se adecua al
proyecto teniendo en cuenta que con este trabajo se busca
proporcionar una solución de Inteligencia de Negocios basada en
software libre, además de la robustez de la herramienta y su larga
trayectoria, sumado al amplio soporte en su versión de la
comunidad y la facilidad de uso de todos sus componentes.
Page 86
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 86
3.6.5. Análisis de sistemas gestores de bases de datos
Con todos los datos relevados sobre los sistemas gestores
de bases de datos, se realizó el análisis para la selección del
SGBD que se utilizará para el desarrollo del data warehouse
necesario para la concreción del proyecto.
A continuación se presenta la tabla 6 donde se tiene un
cuadro comparativo de los SGBD seleccionados y mencionados
en el relevamiento.
Característica MySQL SQL Server
Costo Libre de Pago De Pago
Open Source Si No
Plataformas Linux, Windows, Mac y otras Windows
Límite de tamaño de BD Limitado por el Sistema
Operativo
Limitado por el Sistema
Operativo
Transacciones Si Si
Posibilidad de elegir
diferentes formas de
almacenamiento
Si No
Claves Foráneas Depende del motor Si
Vistas Si Si
Procedimientos Almacenados Si Si
Triggers Si Si
Cursores Si Si
Subconsultas Si Si
Funciones definidas por el
usuario
Si Si
Multiusuario Si Si
Tabla 6: Comparativa de SGBD
Finalmente, después de realizar un análisis detallado de las
dos opciones seleccionadas, se optó por utilizar MySQL Server
como SGBD para el desarrollo del data warehouse, basados en
Page 87
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 87
que no existen diferencias sustanciales entre las dos opciones, en
función a lo que se necesita para la realización de esta tesis, como
así también y principalmente teniendo en cuenta que se busca
desarrollar una solución de Inteligencia de Negocios basada en
softwarelibre.
3.6.6. Análisis de tecnología actual del Grupo Flayp
En función a los requerimientos de las herramientas
necesarias, para la implementación del prototipo de la Inteligencia
de Negocios, no es apropiado instalar en los servidores que
soportan las cargas transaccionales ya que esto propiciaría efectos
negativos en cuanto a las prestaciones, disponibilidad y
desempeño de los mismos.
3.6.7. Análisis de algoritmo de minería de datos
A continuación se puede observar en la tabla 7un cuadro
comparativo de los algoritmos relevados en la etapa de
revelamiento de datos.
Page 88
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 88
Algoritmo Costo
Computacional
Tiempo de Ejecución Rendimiento
BackPropagation
(Redes Neuronales)
Alto costo
computacional
Consume mucho
tiempo
La memoria puede
llegar a ser insuficiente
durante la ejecución del
algoritmo
Regresión Lineal de
Cuadrados Mínimos
No tiene un costo
muy elevado
El tiempo de
ejecución es muy
superior al
BackPropagation
Se adecua más fácil a
los recursos disponibles
Tabla 7: Comparativa de algoritmos de minería de datos.
Para este proyecto de tesis se optó por el algoritmo de
regresión lineal aplicando métodos de mínimos cuadrados, ya que
este algoritmono consume demasiados recursos y tiene un tiempo
de respuesta significativamente superior al algoritmo
backpropagation de redes neuronales, además es uno de los más
utilizados para predicciones de ventas.
3.6.8. Análisis de sistemas operativos
Se realiza un cuadro comparativo entre sistemas
operativos basados en GNU/Linux y Windows tomando los
aspectos más importantes a tener en cuenta en el momento de la
elección de un Sistema Operativo. El mismo puede observarse en
la tabla 8.
Page 89
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 89
Aspecto Sistema Operativo GNU/Linux Sistema Operativo Windows
Tiempo de Inicio
El proceso de carga de archivos
para el arranque es muy ligero y
rápido.
Es más pesado, la carga de los
archivos para el arranque lo
realiza más lento.
Seguridad
Muy bajo el índice de
vulnerabilidad, pocos virus se han
creado para este sistema operativo.
Muy alto el índice de
vulnerabilidad, se crean muchos
virus para este sistema operativo.
Aplicaciones
En la actualidad existen una
variedad importante de aplicaciones
para Linux.
Existen muchas aplicaciones para
Windows.
Drivers
Aplica lista de drivers para el
funcionamiento de los dispositivos.
Aplica lista de drivers para el
funcionamiento de los
dispositivos.
Mantenimiento
Su mantenimiento es más fácil
comparado al de Windows, pero si
no lo sabemos hacer, conseguir
personas que lo haga puede ser una
dificultad.
Su mantenimiento es más
complicado que el de Linux pero
existen más personas que lo saben
hacer comparado al de Linux.
Soporte Java
Virtual Machine
Soporta perfectamente plataforma
Java
Soporta perfectamente plataforma
Java
Difusión
Día a día va ganando terreno en los
hogares y oficina, muy utilizando
en servidores.
Tiene un alto porcentaje del
mercado salvo el de servidores.
Costo
Sigue siendo el sistema más
comercial tiene un costo importante
en licenciamiento con código fuente
cerrado.
El sistema operativo Linux como
un sinfín de aplicaciones que lo
utilizan es open source.
Tabla 8: Comparativa de sistemas operativos
Teniendo en cuenta el objetivo de la tesis, el cual consiste
en implementar un prototipo de sistema de inteligencia de
negocios utilizando software libre, sumado a la preferencia de las
empresas en utilizarsoftware con este tipo de licencia, se optó por
el sistema operativo Linux.
Page 90
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 90
3.6.9. Análisis de factibilidad económica
A continuación se presenta una tabla donde pueden
apreciarse los costos necesarios para llevar adelante este proyecto,
en la misma se detallan los conceptos y los respectivos montos.
Concepto Cant. P.U u$s Total u$s
Analista de Sistemas 1 0.0$s 0.0$s
Desarrollador 2 0.0$s 0.0$s
Especialista en BI 1 1.500$s 4.500$s
Servidor Dell PE R520 Rackeable 1 5.397$s 5.397$s
Licencia S.O. Servidor 1 0.0$s 0.0$s
Licencia Herramienta Desarrollo BI 1 0.0$s 0.0$s
Licencia Servidor BI 1 0.0$s 0.0$s
Total 6.647$s 6.647$s
Tabla 9: Cuadro de costos
Tal como puede observarse en la tabla anterior, el costo
total que implica la implementación de este proyecto es por
demás accesible, teniendo en cuenta la relación entre el costo
mencionado y el volumen de ventas que manejan las empresas del
Grupo Flayp. Esto es favorecido también, gracias a la posibilidad
de contar con los servicios de los profesionales de T.I del Grupo
Flayp, como ser Analistas de Sistemas y Desarrolladores,
necesitándose solo la tutoría de un especialista en soluciones de
Inteligencia de Negocios, para brindar un acompañamiento que
asegure el éxito del proyecto. Así también recalcar una vez más,
el ahorro que representa la utilización de herramientas con
licencia de software libre.
Page 91
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 91
En el Anexo 4 se adjunta el presupuesto del servidor
recomendado.
3.7. Diseño
En este capítulo se describirá el diseño deldata warehouse,ETL,
reportes, cubos OLAP, cuadros de mandos, y los distintos diagramas que
componen el prototipo.
Se utilizarán cuatro ejemplos de informes, un reporte dinámico que
permite la interacción del usuario con el mismo, un reporte basado en el
proceso de minería de datos, un análisis dinámico basado en cubos OLAP
y un cuadro de mando.
3.7.1. Diseño del data warehouse
Se diseñó eldata warehouse utilizando un modelo en
estrella, y en cuanto a los estándares para el modelado, se define
lo siguiente:
Todas las tablas del data warehouse (hechos y
dimensiones) poseerán el prefijo dw_.
Todas las tablas intermedias utilizadas para el proceso de
actualización poseerán el prefijo inter_.
Page 92
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 92
A continuación se presentan las distintas tablas
dimensionales deldata warehouse y sus relacionamientos con las
tablas de hechos, para el diseño del diagrama entidad relación se
utilizó la herramienta MySQL Workbench.
En las figuras 7,8 y 9 se pude observar los diagramas de
entidad relación del data warehouse.
Figura 7: DER Hechos Pedidos
Page 93
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 93
Figura 8: DER Hechos Ventas.
Figura 9: DER Proyección
3.7.2. Diseño del proceso ETL
A continuación se presenta en tablas, el mapeo del cargado
del data warehouse indicando sus respectivas fuentes de datos.
Page 94
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 94
Para la concreción de esta etapa del proyecto se utilizó la
herramienta Pentaho Data Integration.
Columna Tipo Llave Fuente Viru
CodArticulo Int Si Artiuclos Viru.dbf.FSCODE
Descripción Varchar No Artiuclos Viru.dbf.DESCRIPCION
categoría Varchar No Artiuclos Viru.dbf.CATEGORIA
subcategoria Varchar No Artiuclos Viru.dbf.SUBCATEGORIA
Tabla 10: Mapeo de tabla inter_articulos_viru
Columna Tipo Llave Fuente Viru Fuente Flayp
CodArticulo int No inter_articulos_vi
ru.codArticulo
Fwa.Articulos.fsCod
e
IdArticulo int Si Agregado en el
Proceso de ETL
Agregado en el
Proceso de ETL
CodEmpresa int No Agregado en el
Proceso de ETL
Agregado en el
Proceso de ETL
Descripción Varchar No inter_articulos_vi
ru.Descripcion
Fwa.Articulos.descri
pción
Categoria Varchar No inter_articulos_vi
ru.Categoria
Fwa.Categorias.Cate
goria
SubCategoria Varchar No inter_articulos_vi
ru.sub_categoria
Fwa.subcategorias.s
ubcategoria
Tabla 11: Mapeo de tabla dw_articulos
Columna Tipo Llave Fuente Viru
Contrato Int Si Fwa.clientes.contrato
Zona Int No Fwa.clientes.zona
División Varchar No Fwa.divisiones.division
departamento varchar No Fwa.deparatmentos.departamento
Tabla 12: Mapeo de tabla dw_clientes
Columna Tipo Llave Fuente Flayp
Orden int no Fwa.campañas_actuales.orden
Tabla 13: Mapeo de tabla dw_campañas_actuales
Page 95
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 95
Columna Tipo Llave Fuente Flayp
CAMPA varchar No Archivo DBF
CODIGO int No Archivo DBF
PRODU varchar No Archivo DBF
PRECIO bigint No Archivo DBF
ZONA varchar No Archivo DBF
CONTRATO bigint No Archivo DBF
ESTADO char No Archivo DBF
CANTIDAD bigint No Archivo DBF
SERIE char No Archivo DBF
SUCURSAL varchar No Archivo DBF
TIMBRADO varchar No Archivo DBF
DOC bigint No Archivo DBF
TIPO varchar No Archivo DBF
SUBTIPO varchar No Archivo DBF
FECHA datetime No Archivo DBF
OTRODOC varchar No Archivo DBF
OTROFEC datetime No Archivo DBF
OTROHOR varchar No Archivo DBF
VENDEDOR varchar No Archivo DBF
FECHADOC datetime No Archivo DBF
IMPRESO char No Archivo DBF
COSTO bigint No Archivo DBF
IMPUESTO char No Archivo DBF
PREMIO char No Archivo DBF
EXPREMIO char No Archivo DBF
FOLLETO varchar No Archivo DBF
C_UNIDADES bigint No Archivo DBF
C_VENTAS bigint No Archivo DBF
C_CAJA bigint No Archivo DBF
VERIFI char No Archivo DBF
RESULT char No Archivo DBF
BRASIL_1 char No Archivo DBF
BRASIL_2 char No Archivo DBF
COLUMNA int No Archivo DBF
GRUPO varchar No Archivo DBF
OPERADOR varchar No Archivo DBF
PAGINA int No Archivo DBF
FSCODE bigint No Archivo DBF
C_CLIENTES bigint No Archivo DBF
C_SUSTITU char No Archivo DBF
C_PACKIN char No Archivo DBF
XXUSR varchar No Archivo DBF
XXFECHA datetime No Archivo DBF
XXHORA varchar No Archivo DBF
Tabla 14: Mapeo de tabla clonado_dbf_viru
Page 96
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 96
Columna Tipo Llave Fuente Flayp
Campaña Int No Fwa.pedidos.campaña
Año Int No Fwa.pedidos.año
codCliente Int No Fwa.pedidos.numCliente
codArticulo Int No Fwa.pedidodetalles.fsCode
idArticulo Int No Agregado en el Proceso de ETL
Cantidad Int No Fwa.pedidodetalles.cantidad
Monto Int No Fwa.pedidodetalles.precio
codEmpresa Int No Agregado en el Proceso de ETL
Tabla 15: Mapeo de tabla inter_pedido_avon
Columna Tipo Llave Fuente Viru
Campaña Int No clonado_dbf_viru.CAMPA
Año Int No clonado_dbf_viru.AÑO
codCliente Int No clonado_dbf_viru.CONTRATO
codArticulo Int No clonado_dbf_viru.PRODU
idArticulo Int No Agregado en el Proceso de ETL
Cantidad Int No clonado_dbf_viru.CANTIDAD
Monto Int No clonado_dbf_viru.PRECIO
codEmpresa Int No Agregado en el Proceso de ETL
Tabla 16: Mapeo de tabla inter_pedido_viru
Columna Tipo Llave Fuente Flayp
numDocumento
Int Si Fwa.ventas.numDocumento
Campaña Int No Fwa.ventas.campaña
Año Int No Fwa.ventas.año
codCliente Int No Fwa.ventas.contrato
codArticulo Int No Fwa.ventasdetalle.codArticulo
idArticulo Int No Agregado en el Proceso de ETL
Cantidad Int No Fwa.ventasdetalle.cantidad
Monto Int No Fwa.ventasdetalle.precio
codEmpresa Int No Agregado en el Proceso de ETL
Tabla 17: Mapeo de tabla inter_ventas_avon
Page 97
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 97
Columna Tipo Llave Fuente Viru
CAMPA bigint No clonado_dbf_viru.CAMPA
AÑO smallint No clonado_dbf_viru.AÑO
PRODU varchar No clonado_dbf_viru.PRODU
idArticulo int No Agregado en el Proceso de ETL
PRECIO bigint No clonado_dbf_viru.PRECIO
CONTRATO bigint No clonado_dbf_viru.CONTRATO
CANTIDAD bigint No clonado_dbf_viru.CANTIDAD
DOC bigint No clonado_dbf_viru.DOC
codEmpresa int No Agregado en el Proceso de ETL
Tabla 18: Mapeo de tabla inter_ventas_viru
Columna Tipo Llave Fuente Viru Fuente Flayp
Campaña int Si inter_ventas_viru.CAMPA inter_ventas_avon.Campaña
Año int Si inter_ventas_viru.AÑOAgreg
ado en el Proceso de ETL
inter_ventas_avon.Año
CodEmpresa int Si Agregado en el Proceso de
ETL
Agregado en el Proceso de
ETL
NumFactura bigin No inter_ventas_viru.DOC inter_ventas_avon.numDoc
umento
CodArticulo Int No inter_ventas_viru.PRODU inter_ventas_avon.codArtic
ulo
IdArticulo int Si Agregado en el Proceso de
ETL
Agregado en el Proceso de
ETL
CodCliente Int Si inter_ventas_viru.CONTRAT
O
inter_ventas_avon.codClient
e
Cantidad Int No inter_ventas_viru.CANTIDA
D
inter_ventas_avon.cantidad
Monto Int No inter_ventas_viru.PRECIO inter_ventas_avon.monto
Tabla 19: Mapeo de tabla dw_hechosventas
Page 98
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 98
Columna Tipo Llave Fuente Viru Fuente Flayp
Campaña Int Si inter_pedido_viru.campaña inter_pedido_avon.campaña
Año Int Si inter_pedido_viru.año inter_pedido_avon.año
codEmpresa Int Si Agregado en el Proceso de
ETL
Agregado en el Proceso de
ETL
codArticulo Int Si inter_pedido_viru.codArticulo inter_pedido_avon.codArtic
ulo
idArticulo Int No Agregado en el Proceso de
ETL
Agregado en el Proceso de
ETL
codCliente Int Si inter_pedido_viru.codCliente inter_pedido_avon.codClien
te
Cantidad Int Si inter_pedido_viru.cantidad inter_pedido_avon.cantidad
Monto Int No inter_pedido_viru.monto inter_pedido_avon.monto
Tabla 20: Mapeo de tabla dw_hechospedidos
3.7.3. Diseño de reportes
En esta sección se detalla el diseño de los distintos tipos
de informes previstos en el prototipo de solución de Inteligencia
de Negocios.
La figura 10 representa el diseño del reporte ventas por
campañas por zonas, el mismo está basado en la tabla
dw_hechosventas y en las tablas de dimensiones dw_empresas,
dw_campañas, dw_clientes del data warehouse, este reporte
aporta información sobre la venta efectiva por zonas, en las
variables de unidades y facturación de ambas empresas en
conjunto, como así también por separado.
Page 99
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 99
El reporte visualiza en un gráfico de líneas, el rendimiento
de cada una de las campañas, tanto las campañas con datos
cerrados, como así también las campañas en curso. Pudiéndose
filtrar esa información por zonas y por años, como así también
visualizar los datos de una empresa en particular, o de ambas en
conjunto.
Figura 10: Ventas por campañas por zonas
Page 100
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 100
La figura 11 representa el diseño de uno de los reportes
que se utiliza para representar el resultado de la minería de datos
que predice las ventas, el mismo está basado en las tablas
dw_proyección y dw_empresas del data warehouse, este reporte
aporta información sobre la proyección de ventas en cuanto a las
variables de unidades y facturación.
Figura 11: Reporte proyección de ventas
Page 101
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 101
3.7.4. Diseño de cubos multidimensionales
A continuación se presenta el modelado de cada uno de los
elementos multidimensionales que forman parte del prototipo de
solución de Inteligencia de Negocios. El modelado se realizó
según los requerimientos establecidos en etapas anteriores,
algunos que otros requerimientos fueron ampliados para brindar
una mayor variedad de reportes en la solución.
Dimensión Artículos de la figura 12: esta dimensión se
define para el análisis de las ventas y/o pedidos según el artículo.
Para esta dimensión se definen los siguientes atributos:
El Código del Articulo
Código de la Empresa
Descripción del Articulo
Categoría del Articulo
Sub Categoría del Articulo
Figura 12: Dimensión artículos
Dimensión Campaña de la figura 13: esta dimensión
determina que campaña, año y quarterson los datos cargados en el
data warehouse, la dimensión está compuesta por los siguientes
atributos.
Page 102
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 102
Numero de campaña
Año de la campaña
Quarter de la campaña
Figura 13: Dimensión campaña
Dimensión Clientes de la figura 14: esta dimensión se
define para realizar el análisis de las ventas y/o pedidos según los
datos del cliente. La dimensión está compuesta por los siguientes
atributos.
Numero de contrato del cliente
Zona del cliente
División del cliente
Departamento del cliente
Figura 14: Dimensión clientes
Dimensión Empresas de la figura 15: esta dimensión se
define para realizar análisis de ventas/pedidos según las dos
empresas. La dimensión está compuesta por los siguientes
atributos.
Page 103
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 103
Código de la empresa
Nombre de la empresa
Figura 15: Dimensión campaña
Hechos Pedidos de la figura 16: este hecho modela la
cantidad y monto de los pedidos según el cruzamiento con las
distintas dimensiones ya descritas.
Figura 16: Hechos pedidos
Hechos Ventas de la figura 17: este hecho modela la
cantidad y monto de las ventas según el cruzamiento con las
distintas dimensiones ya descritas.
Figura 17: Hechos Ventas
Page 104
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 104
A continuación se presentaa modo de ejemplo el diseño
del cubo multidimensional de ventas por campaña, división,
categoría y empresa, a implementar en la solución, que cuenta con
los siguientes atributos.
Nombre del Cubo: Ventas por campaña, división,categoría
y empresa.
Descripción: Este cubo pretende realizar un análisis de las
ventas según las dimensiones cruzadas y las medidas
definidas.
Dimensiones: campaña, división, categoría y la empresa.
Medidas: Ventas en Guaraníes, Unidades Vendidas y
Cantidad de Clientes Compradores
En la tabla 21se muestra una de las formas de
representación del cubo multidimensional, que puede cambiar de
acuerdo al análisis que requiera el usuario.
D. Empresa D. División D. Tiempo (Año-
Campaña)
Medida Facturación Medida Unidades
Vendidas
Media
Cantidad
de
Clientes
Avón S.A. Diamante Campaña>Año 99.999.999.9999 9.999.999.999 999.999
Esmeralda Campaña>Año 99.999.999.9999 9.999.999.999 999.999
Rubí Campaña>Año 99.999.999.9999 9.999.999.999 999.999
Zafiro Campaña>Año 99.999.999.9999 9.999.999.999 999.999
Virú S.R.L. Diamante Campaña>Año 99.999.999.9999 9.999.999.999 999.999
Esmeralda Campaña>Año 99.999.999.9999 9.999.999.999 999.999
Rubí Campaña>Año 99.999.999.9999 9.999.999.999 999.999
Zafiro Campaña>Año 99.999.999.9999 9.999.999.999 999.999
Tabla21: Análisiscubo ventas por campaña, división, categoría y empresa.
Page 105
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 105
3.7.5. Diseño de cuadros de mandos
A continuación, en la figura 18 se presenta el diseño de la
estructura general de uno de los componentes de gran importancia
en el prototipo de solución de Inteligencia de Negocios, que son
los cuadros de mandos.
Nombre del cuadro de mando: CDM C6-2012 EN
UNIDADES.
Indicadores Clave de Desempeño (KPI Key Performance
Indicators):
Participación de Ventas en Unidades
Por campaña
Por Empresa
Por División
Top 10 de Zonas
Figura 18: Estructura del cuadro de mando
Page 106
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 106
La figura 19 se muestra la arquitectura lógica y la forma
en la que interactúan los componentes de la solución de
Inteligencia de Negocios para generar los cuadros de mandos.
Figura 19: Arquitectura lógica del cuadro de mando
Porúltimo se define las interacciones que debe tener el
cuadro de mando, el usuario debe poder filtrar por campaña para
que cuando el usuario seleccione una de las campañas refresque
los gráficos con los datos correspondientes.
Page 107
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 107
3.7.6. Diagramas casos de uso
Figura 20: Caso de uso usuario
Page 108
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 108
Figura 21: Caso de uso administrador-consola
Figura 22: Caso de uso administrador – servidor
Page 109
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 109
Figura 23: Caso de uso administrador – informes
Page 110
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 110
3.7.7. Diagrama de actividades
Figura 24: Diagrama de Actividades usuario
Page 111
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 111
Figura 25: Diagrama de actividades administrador - usuarios
Figura 26: Diagrama de actividades administrador - servidor
Page 112
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 112
Figura 27: Diagrama de actividades administrador – informes
3.7.8. Diagramas de secuencia
En la figura 28 se puede apreciar el diagrama de secuencia
correspondiente a la consulta de reporte y cubos que realiza el
usuario gerente.
Page 113
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 113
Figura 28: Diagrama de secuencia – consulta de reporte y cubo
En la figura 29 se puede apreciar el diagrama de secuencia
y por ende las interacciones que se generan al crear un usuario.
Figura 29: Diagrama de secuencia crear usuario
Page 114
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 114
En el diagrama de secuencia que se aprecia en la figura 30
se puede ver las interacciones entre objetos cuando el
administrador del prototipo realiza tareas administrativas.
Figura 30: Diagrama de secuencia administrar prototipo
3.7.9. Diagrama de arquitectura de Pentaho Open BI Suite
En la figura31 se puede ver la arquitectura funcional y los
distintos componentes que hacen a la suite de Pentaho Open BI
Suite. Tal como se puede apreciar en el gráfico, la suite de
Pentaho CE está divida en cuatro capas que son:
Origen de datos, aquí encontramos las fuentes de datos
del cual se extrae la información.
Integración de datos, en esta capa se encuentran las
herramientas de ETL (Data Integration) y las
herramientas para la creación de Metadata.
Page 115
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 115
Plataforma de Inteligencia de Negocios, en esta capa se
encuentra el conjunto de herramientas que facilitan la
administración y ejecución de los procesos creados para
realizar el análisis de datos, aquí está el repositorio de
archivos, la lógica del negocio, los sistemas de
administración y seguridad de la plataforma.
Presentación, en el gráfico se puede apreciar las distintas
maneras de visualizar el resultado de las ejecuciones de
procesos como reportes, On-Line Analitical
Processing(OLAP) y los cuadros de mandos.
Figura 31: Arquitectura Pentaho Open BI Suite
Page 116
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 116
3.7.10. Arquitectura del prototipo de solución de Inteligencia de
Negocios.
A continuación se presenta de forma general la
arquitectura de la solución planteada en la tesis, teniendo en
cuenta la plataforma de la herramienta Pentaho BI Open
Sourceelegidapara el desarrollo del prototipo de sistema,
detallando cada uno de los componentes o sub-sistemas a ser
utilizados para el desarrollo del prototipo, los cuales se pueden
apreciar en la figura 32.
El sistema está estructurado en los siguientes seis
subsistemas.
Fuentes de datos
Extracción Transformación y Cargado (ETL)
On-Line Analytical Procesing (OLAP)
Presentación
Seguridad y Administración
Page 117
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 117
Figura 32: Arquitectura de Inteligencia de Negocios
3.8. Desarrollo del prototipo
3.8.1. Desarrollo del data warehouse
Para el desarrollo deldata warehouse se utilizó el motor de
base de datos MySQL utilizando interfaz de desarrollo la
herramienta phpMyAdmin. Con la cual se desarrollaron las tablas
intermedias, de dimensiones y de hechos además de las funciones
y procedimientos almacenados requeridos para el correcto
funcionamiento del data warehouse. En la Figura 33 se puede
apreciar el data warehouse visto a través del phpMyAdmin.
Page 118
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 118
Figura 33: Data warehouse en PhpMyAdmin
En el Anexo 5 se puede apreciar en detalle el script
utilizado para el desarrollo del data warehouse.
3.8.2. Desarrollo de proceso ETL
En este apartado se detalla a modo de ejemplo, el conjunto
de transformaciones que comprenden el trabajo para la carga de la
tabla dw_hechosventas, en el data warehouse, en ella se describen
las distintas etapas por las que pasaron los datos fuentes de ambas
empresas hasta llegar a ser cargados en el data warehouse.
A continuación se presenta el proceso de ETL realizado
con la herramienta Spoon incluida en el paquete de Pentaho Data
Integration. Para una mejor compresión se detalla primeramente
Page 119
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 119
las transformaciones llevadas a cabo sobre los datos de Virú
S.R.L. y luego las de Flayp S.R.L.
En la figura 34 se observa la primera transformación, la
misma utiliza información almacenada en la tabla
dw_tesis.campañas actuales, donde se indican cuáles son las tres
campañas vigentes, el sistema operacional de la empresa Virú
S.R.L. actualmente genera un archivo dbf por campaña, los
mismos se actualizan periódicamente, conociendo las campañas
vigentes, esta transformación selecciona el archivo dbf
correspondiente de manera automática, e inserta esa información
en la tabla clonado_dbf_viru tal cual reside en la fuente.
Figura 34: Transformación selección de campaña a cargar
En la figura 35 se observa la siguiente transformación, la
misma toma los datos de la tabla dw_tesis.clonado_dbf_viru,
seguidamente se filtran los campos a ser utilizados, descartando
aquellos que no tienen valor para la tabla, luego se le agrega una
constante para indicar que esos datos pertenecen a la empresa
Virú S.R.L., y luego se insertan estos datos en la tabla intermedia
dw_tesis.inter_ventas_viru
Page 120
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 120
Figura 35: Transformación inter_ventas_viru
En la figura 36 puede observarse la siguiente
transformación, la misma genera un llamado a un procedimiento
almacenado, limpiar_clonado_dbf_viru, el cual se encarga de
borrar todos los datos de la tabla clonado_dbf_viru, dejando la
tabla lista para la siguiente transformación.
Figura 36: Transformación limpieza de clonado_dbf_viru
La siguiente transformación se encarga de preparar la tabla
dw_hechosventas para el cargado de los datos a ser actualizados,
para lo cual se genera un llamado a al procedimiento almacenado
borrado_hechosventas_viru que realiza dicha tarea, como puede
observarse en la figura 37.
Page 121
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 121
Figura 37: Transformación borrado hechos_ventas viru
La siguiente transformación toma los datos de la tabla
inter_ventas_viru, luego renombra algunas de las columnas e
inserta los datos en la tabla dw_hechosventas, tal como puede
observarse en la figura 38.
Figura 38: Transformación cargado de tabla hechos_ventas_viru
Finalmente en la figura 39 se puede observar el trabajo
completo, compuesto por todas las transformaciones detalladas
más arriba y el orden en la que se ejecutan cada una de ellas.
Page 122
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 122
Figura 39: Trabajo general de cargado dw_hechosventas fuente Viru
A continuación se muestra como se realizó el proceso de
ETL para la carga de las ventas extraída de la base de datos
operacional de Flayp S.R.L. la cual reside en un motor de base de
datos MySQL. Se presenta cada transformación que se realiza
durante todo el proceso para la carga de los datos en la tabla
dw_hechosventas del data warehouse.
En la transformación de la Figura 40; se muestra como se
realiza el proceso extracción de datos, primero se realiza la unión
de la cabecera con el detalle extraída de la base datos FWA de
Flayp S.R.L. específicamente de las tablas fwa.ventas y
fwa.ventasdetalle, seguidamente se realiza la selección y
renombrado de los campos,se agrega un identificador para la
empresa y por último se insertan los datos en la tabla temporal
inter_ventas_avon del data warehouse.
Page 123
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 123
Figura 40: Transformación cargado de tabla inter_ventas_avon
En la transformación que se aprecia en la Figura 41se
realiza el borrado de los registros de latabla dw_hechosventas que
corresponden a las tres campañas a ser actualizadas, para
identificar las campañas vigentes se realiza una consulta a la tabla
dw_tesis.campañas_actuales.
Figura 41: Transformación borrado dw_hechosventas
Page 124
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 124
En la transformación de cargado de las ventas se toman los
datos limpios y depurados desde la tabla intermedia y se inserta
en la tabla dw_hechosventas del data warehouse, tal como se
puede apreciar en la Figura 42.
Figura 42: Transformación cargado dw_hechosventas
Se crea un trabajo general compuesto por las
transformaciones presentadas, la misma comienza en el paso
Start, luego carga la tabla temporal inter_ventas_avon, realiza el
borrado de los datos a actualizar con el fin de evitar duplicación
de registros, posterior a eso, inserta los datos en el data
warehouse y por ultimo tenemos el paso del tipo control Success
para comprobar que el trabajo se haya realizado con éxito, como
se aprecia en la figura 43.
Page 125
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 125
Figura 43: Trabajo general de cargado hechos_ventas Fuente Flayp
3.8.3. Desarrollo de minería de datos
En esta etapa se presenta el desarrollo del algoritmo de
regresión lineal con mínimos cuadrados utilizado para realizar el
proceso de proyección de ventas con minería de datos.
A continuación se detalla el algoritmo escrito en lenguaje
SQL utilizado en un procedimiento almacenado, para la
proyección de ventas sobre las ventas ya concretadas,
almacenadas en la tabla dw_consolidado, el resultado lo escribe
en la tabla dw_proyeccion.
CREATE PROCEDURE `regresion_lineal`()
BEGIN
DECLARE _promedioX DECIMAL(20,10);
DECLARE _promedioY DECIMAL(20,10);
DECLARE _stdY DECIMAL(20,10);
DECLARE _varY DECIMAL(20,0);
DECLARE _maxY DECIMAL(20,10);
DECLARE _pendiente DECIMAL(20,10);
Page 126
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 126
DECLARE _intercepto DECIMAL(20,10);
DECLARE _empresa INT;
DECLARE _campa INT;
SET _empresa = 1;
regresion_lineal: LOOP
SELECT AVG(Unidades) INTO _promedioY FROM dw_consolidado
WHERE codEmpresa = _empresa;
SELECT AVG(Pedidos) INTO _promedioX FROM dw_consolidado
WHERE codEmpresa = _empresa;
SELECT STD(Unidades) INTO _stdY FROM dw_consolidado WHERE
codEmpresa = _empresa;
SELECT POW(STD(Unidades),2) INTO _varY FROM
dw_consolidado WHERE codEmpresa = _empresa;
SELECT MAX(Unidades) INTO _maxY FROM dw_consolidado
WHERE codEmpresa = _empresa;
SELECT SUM((Unidades-_promedioY)*(Pedidos-
_promedioX))/SUM(POW((Pedidos-_promedioX),2)) INTO _pendiente
FROM dw_consolidado WHERE codEmpresa = _empresa;
SET _intercepto:= _promedioY-_pendiente*_promedioX;
UPDATE dw_proyeccion SET Unidades = _pendiente * Pedidos +
_intercepto WHERE codEmpresa = _empresa;
SELECT AVG(Facturacion) INTO _promedioY FROM
dw_consolidado WHERE codEmpresa = _empresa;
SELECT AVG(Pedidos) INTO _promedioX FROM dw_consolidado
WHERE codEmpresa = _empresa;
SELECT STD(Facturacion) INTO _stdY FROM dw_consolidado
WHERE codEmpresa = _empresa;
SELECT POW(STD(Facturacion),2) INTO _varY FROM
dw_consolidado WHERE codEmpresa = _empresa;
SELECT MAX(Facturacion) INTO _maxY FROM dw_consolidado
WHERE codEmpresa = _empresa;
SELECT SUM((Facturacion-_promedioY)*(Pedidos-
_promedioX))/SUM(POW((Pedidos-_promedioX),2)) INTO _pendiente
FROM dw_consolidado WHERE codEmpresa = _empresa;
Page 127
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 127
SET _intercepto:= _promedioY-_pendiente*_promedioX;
UPDATE dw_proyeccion SET Facturacion = _pendiente * Pedidos +
_intercepto WHERE codEmpresa = _empresa;
SELECT MAX(año*100+campaña) INTO _campa FROM
dw_consolidado WHERE codEmpresa = _empresa;
DELETE FROM dw_proyeccion WHERE (año*100+campaña) <=
_campa AND codEmpresa = _empresa;
SET _empresa = _empresa + 1;
IF _empresa > 2 THEN
LEAVE regresion_lineal;
END IF;
END LOOP regresion_lineal;
END
3.8.4. Desarrollo de reportes
Para el desarrollo de los reportes se utilizó la herramienta
Pentaho Report Designer.
Dentro del Pentaho Report Designer se definieron las
fuentes de datos a utilizar, indicando la conexión a la base de
datos del data warehouse, también se indican las sentencias
definidas previamente en la etapa de diseño, las cuales
recuperarán los datos necesarios para cada reporte.
Por último se han indicado agrupamientos, funciones de
agregación, sumatorias, etc., para personalizar el reporte y lograr
que satisfaga los requerimientos previstos en el diseño del mismo.
Page 128
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 128
A continuación se visualiza el reporte Ventas por
Campañas por Zonas en etapa de desarrollo. La sentencia
utilizada para la generación del reporte es la siguiente:
SELECT
sum(`dw_hechosventas`.`cantidad`) AS Unidades,
sum(`dw_hechosventas`.`monto`) AS
Facturacion,
`dw_hechosventas`.`Campaña` AS Campaña,
`dw_hechosventas`.`Año` AS Año,
`dw_empresa`.`Empresa` AS Empresa,
`dw_clientes`.`zona` AS Zona,
`dw_clientes`.`division` AS Division,
`dw_clientes`.`departamento` AS
Departamento
FROM
`dw_hechosventas` INNER JOIN
`dw_clientes` ON
`dw_hechosventas`.`codCliente` =
`dw_clientes`.`contrato`
INNER JOIN `dw_empresa` ON
`dw_hechosventas`.`codEmpresa` =
`dw_empresa`.`codEmpresa`
WHERE
`dw_clientes`.`zona` = ${zona}
and `dw_hechosventas`.`Año` = ${año}
and (`dw_hechosventas`.`codEmpresa` = ($
{empresa}&1)
or `dw_hechosventas`.`codEmpresa` = ($
{empresa}&2))
GROUP BY
`dw_clientes`.`zona`,
`dw_hechosventas`.`Campaña`,
`dw_hechosventas`.`Año`
Page 129
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 129
Figura 44: Desarrollo reporte ventas por campañas por zonas
A continuación se detalla el desarrollo del reporte
Proyección de Ventas, la sentencia utilizada para la generación
del reporte es la siguiente:
SELECT
`dw_consolidado`.`campaña`, `dw_consolidado`.`año`,
`dw_consolidado`.`codEmpresa`, `dw_consolidado`.`Pedidos`,
`dw_consolidado`.`Unidades`, `dw_consolidado`.`Facturacion`,
`dw_empresa`.`Empresa`
FROM
`dw_consolidado` INNER JOIN `dw_empresa` ON
`dw_consolidado`.`codEmpresa` = `dw_empresa`.`codEmpresa`
GROUP BY
codEmpresa, campaña, año
Page 130
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 130
Figura 45: Reporte de proyección de ventas
3.8.5. Desarrollo de cubos multidimensionales
En la figura 46 se presenta de manera general como se
realizó el desarrollo de los cubos, utilizando como ejemplo el
cubo diseñado en la etapa anterior.
Como se puede apreciar en la figura la estructura de los
cubos en la herramienta (Schema Workbench) se detalla en forma
de árbol, en la cual el nodo padre es el cubo
(ventas_camp_div_cat) del cual se desprenden la tabla de hechos
(dw_hechosventas), las dimensiones (Empresas, Geografías, Año-
Campaña) con sus respectivas etiquetas y tablas de dimensión
(dw_empresas, dw_clientes, dw_campañas), y las medidas que se
desean registrar (Total Ventas, Unidades de Ventas y Cantidad de
Clientes).
Page 131
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 131
Figura 46: Estructura de los cubos
En el siguiente código XML se puede apreciar la metadata
que corresponde a la estructura del cubo creada con la
herramienta Schema Workbench referida en la figura 46. Se puede
apreciar el mapeo de las tablas, las dimensiones con su jerarquía
y las medidas del cubo.
<Schema name="Cubos MKT">
<Cube name="ventas_camp_div_cat" visible="true" cache="true"
enabled="true">
<Table name="dw_hechosventas">
</Table>
<Dimension type="StandardDimension" visible="true"
foreignKey="codEmpresa" highCardinality="false" name="Empresa">
<Hierarchy name="Empresa" visible="true" hasAll="true"
allMemberName="Empresa" primaryKey="codEmpresa">
<Table name="dw_empresa">
Page 132
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 132
</Table>
<Level name="Empresas" visible="true" column="Empresa"
type="String" uniqueMembers="false" levelType="Regular"
hideMemberIf="Never">
</Level>
</Hierarchy>
</Dimension>
<Dimension type="StandardDimension" visible="true"
foreignKey="codCliente" highCardinality="false" name="Geografica">
<Hierarchy name="Division" visible="true" hasAll="true"
allMemberName="Division" primaryKey="contrato">
<Table name="dw_clientes">
</Table>
<Level name="Divisiones" visible="true" column="division"
type="String" uniqueMembers="false" levelType="Regular"
hideMemberIf="Never">
</Level>
</Hierarchy>
</Dimension>
<Dimension type="StandardDimension" visible="true"
foreignKey="Campaña" name="Año-Campaña" caption="Año-
Campaña">
<Hierarchy name="Año-Campaña" visible="true" hasAll="true"
primaryKey="Campaña" caption="Año-Campaña">
<Table name="dw_campañas">
</Table>
<Level name="Año" visible="true" column="Año"
uniqueMembers="false" caption="Año">
</Level>
<Level name="Campaña" visible="true" column="Campaña"
uniqueMembers="false" caption="Campaña">
</Level>
</Hierarchy>
</Dimension>
<Measure name="Total-Ventas" column="monto" datatype="Numeric"
aggregator="sum" caption="Ventas en Guaranies" visible="true">
</Measure>
<Measure name="Unidades de Ventas" column="cantidad"
aggregator="sum" caption="Unidades de Ventas" visible="true">
Page 133
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 133
</Measure>
<Measure name="Cantidad de Clientes" column="codCliente"
aggregator="distinct-count" caption="Cantidad de Clientes"
visible="true">
</Measure>
</Cube>
</Schema>
3.8.6. Desarrollo de cuadros de mandos
Para el desarrollo de los cuadros de mandos o dashboards
se utilizó la aplicación Community Dashboard Editor for Pentaho
(CDE) un editor web gráfico de cuadros de mandos con sus
componentes CDF (Comunity Dashboard Framework) que
permite la creación de dashboards con html y javascript,
Community Chart Component (CCC) que se encarga de la parte
visual de los datos y el framework Community Data Access
Component (CDA) que nos facilita el acceso a los datos.
Con cada una de estas aplicaciones y/o componentes
integrados a Pentaho BI Server CE se desarrollaron los cuadros de
mandos que se puede apreciar en las figuras que se presentan a
continuación.
El diseño se lleva a cabo en tres capas: presentación,
componentes y datos como se puede ver en la figura 47.
Page 134
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 134
Figura 47: Capas de CDE
A continuación se diseña la estructura, se definen el
encabezado, cuerpo y pie del cuadro de mando como se ve en las
figura 48 y figura 49.
Figura 48: Definición de estructura
Page 135
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 135
Figura 49: Estructura de CDM
Una vez definida la estructura se llena la misma de
contenidos, empezando por orígenes de datos y luego los gráficos.
Figura 50: Origen de datos
Para la obtención de los datos se utilizaron sentencias SQL
para cargar los gráficos.
Page 136
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 136
Ventas en Unidades por Campaña:SELECT
b.empresa,sum(a.cantidad) as Unidades from `dw_hechosventas`
a join dw_empresa b on(a.codempresa = b.codempresa) WHERE
campaña = 6 and año = 2012 group by a.codempresa
Participación por Empresas: SELECT
b.empresa,sum(a.cantidad) from dw_hechosventas a join
dw_empresa b on(a.codempresa = b.codempresa) where
a.campaña = 6 and a.año =2012 group by a.codempresa
Participación por División: SELECT
b.division,sum(a.cantidad) as Unidades from `dw_hechosventas`
a join dw_clientes b on(a.codcliente = b.contrato) WHERE
campaña = 6 and año = 2012 group by b.division
Top 10 de Zonas de Mayor Ventas: select b.zona,
sum(a.cantidad) as unidades from dw_hechosventas a join
dw_clientes b on(a.codCliente = b.contrato) group by b.zona
order by unidades desc limit 0,10
3.9. Prueba de prototipo
Se realizaron las pruebas de ejecución de los procesos ETL
utilizados para el cargado de la tabla de hechos ventas en el data
warehouse.
Page 137
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 137
Para una mejor compresión se presentan las pruebas, separadas por
empresas.
Pruebas de los procesos de ETL utilizados, para los datos de
facturación o ventas de la empresa Virú S.R.L.
El proceso de la figura 51, es el resultado de la ejecución del
proceso para obtener los datos de las tres campañas actuales desde los
archivos dbf para su inserción en la tabla auxiliar clonado_dbf_viru.
Figura 51: Selección de archivos dbf Virú.
En la figura 52 se muestra el resultado de la ejecución de la prueba
en el proceso utilizado para el filtrado de datos, inserción de identificador
para la empresa y posterior cargado en la tabla inter_ventas_avon.
Page 138
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 138
Figura 52: Cargado de tabla intermedia inter_ventas_viru
En la figura 53 se puede ver el resultado de la prueba aplicada al
proceso de borrado de la tabla dw_hevhosventas.
Figura 53: Borrado de dw_hechosventas
Page 139
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 139
En la figura 54 se puede ver el resultado de la prueba aplicada al
proceso utilizado para la carga de la tabla dw_hechosventas.
Figura 54: Cargado de dw_hechosventas
Finalmente en la figura 55 se puede apreciar el resultado de la
prueba del trabajo completo para el cargado de la tabla dw_hechosventas
con datos provenientes desde la empresa Virú S.R.L.
Page 140
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 140
Figura 55: Trabajo hechos ventas fuente dbf
Pruebas de los procesos de ETL utilizados, para los datos de ventas
obtenidas de la empresa Flayp S.R.L.
En la figura 56 se muestra el resultado de la ejecución de la prueba
en el proceso utilizado para la obtención, filtrado de datos, inserción de
identificador para la empresa y cargado en la tabla inter_ventas_avon.
Page 141
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 141
Figura 56: Cargado de la tabla inter_ventas_avon
En la figura 57 se puede ver el resultado de la prueba aplicada al
proceso de borrado de la tabla dw_hevhosventas.
Figura 57: Borrado hechos ventas Flayp S.R.L.
Page 142
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 142
En la figura 58 se puede ver el resultado de la prueba aplicada al
proceso utilizado para la carga de la tabla dw_hechosventas.
Figura 58: Hechos ventas fuente MySQL
En la figura 59 se puede apreciar el resultado de la prueba del
trabajo completo para el cargado de la tabla dw_hechosventas con datos
provenientes desde la empresa Flayp S.R.L.
Page 143
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 143
Figura 59: Trabajo hechos ventas fuente MySQL
Como resultado de las pruebas se pudo comprobar la efectividad de
los procesos ETL.
3.10. Implementación del Prototipo
3.10.1. Implementación de ETL y Data warehouse
Para la implementación de los trabajos de ETL que a su
vez implementan eldata warehouse se utilizóun administrador
regular de procesos en segundo plano (demonio) llamado cron,
provisto nativamente por los sistemas operativos basados en
UNIX.
Page 144
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 144
Para programar el cron se copió dentro de la carpeta de
Pentaho el archivo cron_tesis.sh el cual corresponde al script a ser
ejecutado.
Dentro de crontab se agregó el siguiente comando.
#m h dom mon dow command
00 01 * * * sh /usr/Pentaho/cron_tesis.sh
Con esto se logró que la actualización deldata warehouse
a través de la ejecución de los procesos de ETL se realice todos
los días a las 01:00 am.
3.10.2. Implementación de Pentaho Open BI Server
Para la implementación del Pentaho BI Suite Community
Edition (CE), se procedió a descargar la versión 4.5 estable desde
la siguiente dirección, desde donde están disponibles para
descargar todas las herramientas de la comunidad de Pentaho.
http://sourceforge.net/projects/pentaho/files/
Como se aprecia en la figura 60, seleccionamos Bussines
Intelligence Server para descargar.
Page 145
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 145
Figura 60: Descarga de Bussines Intelligence Server
Una vez descargado el paquete de instalación del servidor,
se debe iniciar el servicio Apache en nuestro Servidor con
Sistema Operativo Linux Open Suse 12.2, como se indica en la
figura 61.
Este servicio es necesario ya que la plataforma Pentaho
utiliza Apache-Tomcat como servidor de aplicaciones para
desplegar los servicios que la componen.
Page 146
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 146
Figura 61: Inicio del servicio Apache.
Para completar la instalación se navega hasta el directorio
donde se encuentran los archivos descargados, y se procede
levantar el servidor Pentaho a través del archivo start-pentaho.sh
como se puede apreciar en la figura 62.
Figura 62: Instalación de Pentaho Bussines Intelligence Server.
Con el Servidor de Pentaho Bussines Intelligence
instalado y corriendo, nos conectamos a la Consola de Usuario de
Pentaho, ingresando la dirección de nuestro servidor en el
navegador de internet (http://localhost:8080/pentaho/Home)
iniciamos sesión con nuestro usuario como se aprecia en la figura
63.
Page 147
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 147
Figura 63: Pantalla de inicio de sesión en la consola de usuario de
Pentaho
Finalmente ingresamos a la consola de usuario, como
puede visualizarse en la figura 64,desde donde los usuarios
podrán acceder para visualizar los reportes, realizaran análisis e
interactuar con los cuadros de mandos.
Figura 64: Consola de usuario Pentaho
Page 148
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 148
3.10.3. Implementación de consola de administración de usuarios
Pentaho
En este apartado se detallan los pasos realizados para la
implementación de la consola de administración usuarios de
Pentaho.
La versión instalada es la Pentaho BI Server 4.5.0-stable,
en primer lugar se descargó el instalador desde la página de la
comunidad de Pentaho, en el siguiente vínculo de descarga:
http://sourceforge.net/projects/pentaho/files/Business%20I
ntelligence%20Server/4.5.0-stable/biserver-ce-4.5.0-
stable.tar.gz/download
Una vez descargado el instalador, se descomprimió el
archivo tar.gz, el cual genera dos carpetas; biserver-ce y
administration-console
Dentro de la carpeta administration-console se encuentra
el instalador de la consola de administración, el mismo es el start-
pac.sh, mientras que para detener el servicio de la consola, el
archivo es stop-pac.sh.
Una vez que el servidor se encuentra en funcionamiento,
para acceder a la consola de administración de usuarios, solo
basta escribir en la barra de direcciones del navegador: localhost:
Page 149
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 149
8099, el usuario y contraseñas configuradas por defecto para la
administración inicial son; usuario: admin y contraseña:
password. Luego de lo cual se procede a crear una contraseña más
segura.
La consola de administración usuarios permite la gestión
tanto de los usuarios, como así también de los roles que se
asignaran a cada usuario, ya que de acuerdo a dichos roles, se
especifican los privilegios que tendrá cada usuario dentro de la
solución.
En la figura 65 se observa una imagen del acceso a la
consola de administración de usuarios de Pentaho.
Figura 65: Consola de administración de usuarios
Page 150
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 150
Así también a través de la consola de administración se
pueden administrar las fuentes de datos que utilizará el servidor.
Tal como se aprecia en la figura 66.
Figura 66: Administración de fuentes de datos
3.10.4. Implementación de reportes
La figura 67 visualiza el acceso al reporte Ventas por
Campañas por Zonas, el mismo puede ser visualizado en
diferentes formatos (HTML, PDF, Microsoft Excel, RichText
Format y texto plano), como así también puede ser descargado a
la pc del usuario. Este reporte permite la interacción de los
usuarios, utilizando para ello las variables de: Zona, Año y
Empresa.
Page 151
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 151
Figura 67: Publicación del reporte ventas por campaña por zonas
La imagen 68 visualiza el acceso al reporte Proyección de
Ventas, el mismo puede ser visualizado en diferentes formatos
(HTML, PDF, Microsoft Excel, Rich Text Format y texto plano),
como así también puede ser descargado a la pc del usuario.
Figura 68: Publicación reporte de ventas por zonas
Page 152
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 152
3.10.5. Implementación de los cubosmultidimensionales
Para que los cubos sean accesibles por el motor de cubos,
se publicaron dentro de la plataforma de Pentaho, para lo cual se
utilizó la funcionalidad de la herramienta Schema Workbench,
que a través de unos pasos sencillos tenemos el cubo publicado,
este proceso se realiza cada vez que se crea un nuevo cubo o se
modifica uno ya existente.
Para navegar por los cubos e interactuar se puede utilizar
el Jpivot o Saiku, en la figura 69, se visualiza el cubo de las
ventas generales, explorado desde la herramienta Saiku.
Figura 69: Cubo de ventas
Page 153
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 153
3.10.6. Implementaciónde cuadros de mandos
Al igual que en los reportes, los usuarios acceden a los
informes a través de cualquier navegador desde una
computadora, tabletas y/o teléfonos inteligentes con el cual se
conecta al servidor de Pentaho. En la figura 70, se aprecia el
cuadro de mandos que tiene los indicadores de la participación de
las empresas del Grupo Flayp en las ventas.
Figura 70: Participación en facturación por empresas
Page 154
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 154
CAPÍTULO 4– RESULTADOS
Con la concreciónde este proyecto se logró demostrar la factibilidad de la
realización de un prototipo de solución de Inteligencia de Negocios, desarrollado
íntegramentesobresoftware libre, utilizando además la técnica de minería de datos.
La implementación de dicho prototipo implica la reducción del costo en
tiempo y recursos humanos para la generación de los informes, que además
permite el acceso a información consolidada, fiable y actualizada delas empresas
Virú S.R.L. y Flayp S.R.L.Esto permite que los gerentes y directores se
encuentren con mayor seguridad al momento de tomar decisiones pertinentes,
teniendo en cuenta la realidad actual de las empresas.
Con todo lo anteriormente citado, se evidencia el logro de los objetivos
trazados al inicio del proyecto, como así también la solución a la problemática
planteada.
Page 155
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 155
CAPÍTULO 5 - CONCLUSIONES
Con el desarrollo del prototipo de solución de Inteligencia de Negocios se
adquirieron conocimientos en el área de la Inteligencia de Negocios, debiendo
para ello, investigar y aprender sobre las distintas herramientas necesarias para la
concreción de una solución de esta naturaleza. Todo esto sustentado en los
conocimientos adquiridos en las distintas materias a lo largo de la carrera.
Ademásse logró demostrar la factibilidad de la realización de un proyecto
de este tipocon la utilización de software libre, logrando también aplicar una de
las técnicas de minerías de datos, en función a la proyección de las ventas en
distintos niveles, logrando de esta manera alcanzar el objetivo trazado al inicio de
este proyecto.
Así también mencionar que las empresas pueden acceder a una solución de
vanguardia incurriendo en gastos mínimos y convertir esta solución en un aliado
estratégico a la hora de la toma de decisiones que puedan marcar la diferencia en
un mercado altamente competitivo.
Page 156
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 156
CAPÍTULO 6- RECOMENDACIONES
Es recomendable la utilización de software libre para el desarrollo de
soluciones de Inteligencia de Negocios, ya que estas disponen de todas las
herramientas necesarias para la concreción de proyectos de esta naturaleza.
Concibiendo la solución desde un enfoque integral, con la centralización e
integración de los datos que manejan las empresas, permitiendo a los usuarios
acceder a información veraz, consolidad y en tiempo real, convirtiéndose en un
aliado estratégico para dar respuestas más eficientes al creciente entorno
competitivo. Sin que esto signifique incurrir en grandes inversiones.
Para el caso de este proyecto se recomienda en una segunda etapa, ir
integrando las distintas áreas como ser Compras, Logística, Finanzas y en una
tercera etapa a todas las otras empresas pertenecientes al Grupo Flayp, bajo una
misma plataforma de Solución de Inteligencia de Negocios.
Page 157
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 157
BIBLIOGRAFÍA
Cohen Karen, D. y Asín Lares, E. 2.000. Sistemas de Información para
los negocios (Tercera Edición). Editorial McGraw Hill. México, 1-
43pp.
Pressman, R. 2.005. Ingeniería del Software: un enfoque práctico
(Sexta Edición). Editorial McGraw Hill. México, 48-76pp.
Ross, M.y Kimball, R. 2.002.The Data Warehouse Toolkit: The
Complete Guide to Dimensional Modeling (Second Edition).John
Wiley and Sons, Inc. Toronto, 331-369pp.
Conesa Caralt, J. y Curto Diaz, J. 2.010. Introducción al Business
Intelligence, UOC, Barcelona.
Cano, J. L. 2.007. Bussines Intelligence: Competir con
Información.Banesto, Fundación Cultural, Barcelona, 19-195 pp.
Vallejos, S. J. 2.006. Minería de Datos. Tesis Universidad Nacional del
Nordeste Facultad de Ciencias Exactas, Naturales y Agrimensura,
Corrientes, ARG, 11-16 pp.
Hernández et al., 2.008. Introducción al Software Libre. Eureca Media,
SL, Barcelona, 17-58 pp.
Ramos, S. 2.011. Microsoft Business Intelligence: Vea el cubo medio
lleno. SolidQ™ Press. Alicante, España, 7-19 pp.
Smith, N. 2.009. History of Business
Intelligence.http://www.powerpivotblog.nl/history-of-business-
intelligence . Último acceso 06/12
http://www.stratebi.com/ . Herramientas de Inteligencia de Negocios
Open Source. Último acceso 07/12.
http://forums.pentaho.com/forum.php .Foro oficial de la suite de
Pentaho Comunity Edition. Último acceso 09/12.
http://www.dataprix.com/forum/software/pentaho .Foro de consultas
de la suite de Pentaho Comunity Edition. Último acceso 07/12.
Page 158
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 158
Hernández Sampieri R., Fernández, Collado C., Baptista, Luci P.
(1996). Metodología de la Investigación. Ed. Mc Graw-Hill: México.
González Barahona,J.M., Seoane Pascual, J., Robles G. (2008).
Introducción al Software Libre (Segunda Edición). Eureca Media:
Barcelona.
Kimball, R. y Caserta, J. 2.004.The Data Warehouse ETL Toolkit.
WileyPublishing , Inc. Toronto, 3-52pp.
Peña Ayala A. 2.006 Inteligencia de Negocios: Una propuesta para su
desarrollo en las organizaciones. Dirección de Publicaciones del
InstitutoPolitécnico Nacional, Mexico D.F.
Hernandez Orallo J., Ramirez Quintana M., Ferri Ramirez C. 2.004
Introducción a la minería de datos. Pearson Prentice Hall, Madrid.
Stallman R. 2.004 Software libre para una sociedad libre. Traficante de
Sueños, Madrid.
http://www.microstrategy.com/software/business-intelligence/.
Business Intelligence for the Enterprise. Último acceso 07/12.
http://www.palo.net/. Open SourceBusiness Intelligence. Último
acceso 07/12.
Page 159
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 159
ANEXOS
Anexo 1
Diagrama WBS
Page 160
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 160
Anexo 2
Esquema de Entrevistas
Gerente de Marketing del Grupo Flayp
P - ¿Cuáles son los criterios que se utilizan para evaluar los resultados de una
campaña?
R - Básicamente para cada campaña se tienen dos miradas, la primera los pedidos
efectivos realizados por las Consejeras, esto muestra la aceptación de los
productos ofrecidos en dicha campaña; la otra mirada es evaluando lo que
realmente se pudo abastecer a la Consejeras, ya que esto refleja el nivel de
respuesta y por ende los beneficios de la empresa.
P – ¿Cuáles son las variables que se miden en cuanto a resultados?
R – Los beneficios de la empresa se miden en tres variables directas y tres
variables indirectas que son:
Variables Directas
Utilidades
Unidades Vendidas
Pedidos Efectivos
Variables Indirectas
PPO (Productividad por Orden)
NPU (Precio neto por unidad)
UPR (Unidades por revendedora)
P – ¿Con qué frecuencia se necesitan tener estas informaciones?
R – Por la dinámica de la venta directa a través de catálogos, es fundamental
contar con información diariamente, ya que es de vital importancia para decidir
los cambios de rumbo de ser necesarios.
P – ¿Que otro análisis se realiza a una campaña?
R – Existe una gran cantidad de análisis que se pueden realizar basándose en las
variables antes mencionadas, se puede observar que nivel de aceptación tienen
nuestros productos tanto en Capital como así también en el Interior del país, de
igual manera, es interesante conocer quiénes de nuestras promotoras están
vendiendo más, de modo tal a emular esas técnicas en los lugares donde las ventas
Page 161
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 161
están bajando, además de poder tener una mirada con respecto al nivel de
abastecimiento que tenemos para con nuestras consejeras.
P – ¿Actualmente, con qué frecuencia se obtienen esas informaciones?
R – El proceso para obtener esas informaciones es el siguiente, se realiza un
pedido (a través de una comunicación telefónica o del envió de un correo
electrónico) al departamento de T.I., el cual prepara una consulta en S.Q.L., que se
aplica a la base de datos, el resultado se exporta a un archivo CSV, el cual puede
ser abierto luego con algún procesador de hojas de cálculo.
P – ¿Es decir que actualmente no se cuenta con un módulo que genere los reportes
de forma directa?
R - No, los informes se realizan por pedido de las partes interesadas, con las
dificultades que esto conlleva, como ser, que varias personas necesiten sus
informes al mismo instante, que la persona que realiza estas consultas se
encuentre muy atareado en sus labores principales, que el interlocutor halla
interpretado correctamente el informe que se necesitaba, etc.
Gerente de Ventas del Grupo Flayp
P - ¿Cómo realiza la evaluación de una campaña?
R – Desde la mirada del departamento de Ventas, los resultados de una campaña
se miden en función a la cantidad de pedidos que realizan nuestras consejeras, ya
que esto nos muestra el nivel de cobertura de nuestra fuerza de ventas.
P – ¿Entonces es importante conocer en donde se venden los productos?
R – Es fundamental conocer qué y donde se venden nuestros productos, de
manera a poder fortalecer los puntos flojos con estrategias de motivación a las
consejeras, poder determinar que productos se venden mejor en la capital y cuales
en el interior del país.
P – ¿Existen objetivos trazados en cuanto a ventas?
R – Si, al inicio del año, se trazan objetivos para los Gerentes Divisionales, en
cuanto a crecimiento en cuanto a órdenes y productividad de las mismas, también
en sintonía con esto, se trazan objetivos a las Promotoras, se definen niveles de
crecimiento en cuanto a órdenes, unidades y facturación, en ambos casos, el llegar
Page 162
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 162
a estos objetivos tiene como recompensa una variedad de premios, y la no
concreción conlleva sus consecuencias.
P – ¿Existe algún un monitoreo de la concreción de estos objetivos?
R – Existe, pero es muy dificultosa, ya que para obtener los informes que nos
indiquen la cantidad de Promotoras que están llegando a los objetivos, se deben
pedir al departamento de T.I., y esto lleva su tiempo.
P - ¿Serviría de algo tener estos informes en forma más directa y optima?
R – Realmente seria de muchísima ayuda, se utilizaría para poder indicarle a
nuestras Promotoras que están lejos de los objetivos, que deben esforzarse más
tratando de alentar su crecimiento, usando a las mejores como guía.
P – ¿Es importante conocer el nivel de cumplimiento con las Consejeras?
R – Es fundamental, ya que el incumplimiento es la causa principal de la
deserción de nuestras Consejeras, un mal servicio genera frustración, primero en
los clientes consumidores y luego en las Consejeras, es por esto que si se puede
tener claro el panorama, se pueden buscar distintas estrategias, tanto para buscar
evitar la fuga de Consejeras, como así también buscar el reingreso de quienes se
alejaron en su momento.
Miembro del directorio del Grupo Flayp
P – ¿Cómo es el manejo de las empresas dentro del Grupo?
R – Las empresas son financiera, económica y operativamente independientes,
cada una de ellas tiene completa autonomía, pero son controladas por el
Directorio, que es el nivel más alto de autoridad.
P – ¿Es importante conocer el nivel de aporte que tiene cada empresa?
R – Es muy importante, al ser un grupo multiempresarial, se debe conocer cuál de
las empresas está siendo más redituable para el Grupo, y cuál de ellas necesita un
cambio de rumbo si hiciese falta.
P – ¿Esto para una evaluación individual, y en cuanto al rendimiento de ambas
empresas en conjunto?
R – También es de vital importancia poder tener informes que indiquen a nivel
macro el desempeño de las empresas del Grupo, porque al final de cuentas, esa
mirada macro es la que nos demuestra el nivel de beneficios que se está
Page 163
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 163
obteniendo, por ello es tan importante un análisis individual como así también un
análisis en conjunto.
P – ¿El Grupo cuenta en la actualidad con un sistema de informes consolidado de
ambas empresas?
R – La manera en la que se obtienen estos informes es generando en forma
individual los resultados de cada empresa y luego haciendo un resumen donde se
totalizan los resultados de las empresas. Con el riesgo que esto representa, cuando
hablamos de muchas variables y muchos números, se corre el riesgo de cometer
algún tipo de error involuntario, que puede llegar a pasar inadvertido hasta una
etapa muy avanzada, si es que es descubierto obviamente.
P – ¿Cuál sería desde su opinión una forma más óptima de obtener estos
resultados?
R – Lo ideal sería, que de alguna manera podamos contar con los informes de
cada campaña, sin la necesidad de intermediarios, y al momento de precisarlos,
tanto los informes de cada empresa en forma particular, como así también
informes con una mirada macro de la situación de resultado del grupo al cierre de
cada jornada.
P – ¿El grupo empresarial cuenta con profesionales en su departamento de TI?
R – Así es, el grupo cuenta con un gerente de TI, dos analistas de sistemas, y un
amplio plantel de desarrolladores de sistemas.
P - ¿En el caso de llevar adelante algún tipo de solución propuesto, aceptarían que
estos profesionales forme parte del mismo?
R – Mi opinión es que sería la mejor opción, ya que serán ellos quienes tendrán
que mantenerlo en funcionamiento óptimo luego de la puesta en funcionamiento.
Y que mejor alternativa que sean los mismos empleados del grupo, quienes
participen del desarrollo y estén totalmente empapados del tema.
P – ¿Se podría contar con los servicios de estos profesionales en tiempo
completo?
R – Se podrían tratar de compatibilizar las agendas, pero también es importante
tener en cuenta, que no podrían dedicarles el 100% de su tiempo, ya que deben
continuar con sus tareas habituales. Pero seguramente se llegara a una solución
óptima.
Page 164
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 164
Esquema de Observación de Gestión Procesos y Sistemas
Gestión de los Procesos:
Estructura Organizacional.
o Organigrama.
o Infraestructura en Oficinas.
Proceso de Pedidos.
o Formulario de Pedidos.
o Carga de Pedidos en Sistema.
Proceso de Facturación:
o Formulario de Facturas.
o Generar Facturas.
o Imprimir Facturas.
o Guardar Facturas.
o Anular Facturas.
Proceso de Generación de Informes.
o Herramienta Utilizada.
o Tipo de Informes.
o Tiempo empleado.
Marketing por Campaña.
o Tipo de Promociones y Estrategias empleadas.
o Información requerida, para crear promociones.
Tecnologías Empleadas en los Procesos:
Pedidos.
o Módulo de Pedidos del Sistema Operacional.
Captura de Datos (formatos).
Facturación
o Módulo de Facturación del Sistema Operacional.
Captura de Datos (formatos).
Estructura de Datos
o Formato de almacenamiento de los datos.
o Gestor de Base de Datos Utilizado.
Equipos Informáticos
o Equipos utilizados como Servidores de los Sistemas.
o Equipos utilizados para el Sistema Operacional (Pedidos y
Facturación).
Redes
Page 165
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 165
o Topología Física de Red.
o Dispositivos de Redes (características).
Herramientas utilizados para Informes
o Tiempo de Respuesta.
o Limitaciones.
o Bondades.
o Facilidad de Uso.
o Confiabilidad.
o Desempeño.
Plataforma de Software
o Tipo de Sistema Operativo utilizados
Page 166
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 166
Anexo 3
Estructura de Datos Actual
Entidad Descripción
Clientes Clientes
Clientes-Divisiones División Comercial
Clientes-Zonas Zonas Comercial
Clientes-Deptos Departamentos
Pedidos Cabecera de Pedidos
Pedidos-Detalle Detalle de Pedidos
Ventas Cabecera de Facturas
VentasDetalle Detalle de Facturas
Artículos Artículos
Articulos-Categoria Categoría de los Artículos
Articulos-SubCategoria Subcategoria de los Artículos
CampañasActuales Campañas en vigencia
Entidades utilizadas.
Nombre SubModelo Nombre Entidad del Sub Modelo
Clientes
Clientes
Clientes-Divisiones
Clientes-Zonas
Clientes-Departamentos
Pedidos Pedidos
Pedidos-Detalle
Facturas Ventas
VentasDetalle
Artículos Articulos
CampañasActuales CampañasActuales
Sub-Modelado de Entidades utilizadas
Page 167
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 167
Nombre Entidad Atributo Descripción de Atributo
Clientes
Contrato Identificador del contrato
Zona Código de zona
Dpto. Código del Departamento del Cliente
Zonas
codZona Identificador interno de la zona
Zona Código de zona
Encargado Nombre de la encargada de la zona
Teléfono Nmo telefónico de la encargada
Lugar Dirección de cobertura de la zona
Grupos Código de grupo
Rural Identificador si la zona es de capital o interior
promoRepre Identificador si es promotora o representante
codAgencia Código de la agencia a la que pertenece la zona
codDivision Código de división a la que pertenece la zona
Clase Código de la clase
Situación Código de la situación
codDepartamento Código del depto al que pertenece la zona
Divisiones
codDivision Código de la división
División Descripción de la división
Gerente Nombre del gerente de la división
Mostrar Indicador si la división se debe mostrar
Borrado Estado de la división
Departamentos
codDepartamento Código del depto al que pertenece la zona
Código Identificador del departamento
Departamento Descripción del departamento
Borrado Estado del departamento
SubModelo Detallado de Clientes - Entidad/Atributo/Descripción Atributo
DER – Entidad Clientes
Page 168
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 168
Nombre Entidad Atributo Descripción de Atributo
Pedidos
codPedido Identificador de pedido
Año Año de folleto
Campaña Campaña del folleto
Zona Código de la zona del cliente
Fecha Fecha del pedido
numCliente Identificador del cliente
PedidosDetalle
codPedido Identificador del pedido
fsCode Identificador del articulo
Cantidad Cantidad en unidades
Precio Precio unitario del articulo
SubModelo Detallado de Pedidos - Entidad/Atributo/Descripción Atributo
DER – Entidad Pedidos
nombre entidad nombre atributo descripción
Ventas
numDocumento Identificador de la factura
Año Año del folleto de la venta
Campaña Campaña del folleto de la venta
fechaDocumento Fecha de la venta
Zona Código de la zona del cliente
Contrato Numero de contrato del cliente
Ventas Detalle
numDocumento Identificador de la factura
codArticulo Identificador del articulo
Cantidad Cantidad en unidades
Precio Precio unitario del articulo
SubModelo Detallado de Ventas - Entidad/Atributo/Descripción Atributo
Page 169
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 169
DER – Entidad Facturas
Nombre Entidad Atributo Descripcion de Atributo
Articulos
codArticulo Identificador interno del articulo
fsCode Identificador del articulo
codCategoria Código de la categoría del articulo
codSubCategoria Código de la sub categoría del articulo
codLinea Código de la línea del articulo
codEstado Código del estado del producto
Referencia Referencia del artículo
Descripción Descripción del articulo
Volumen Volumen del articulo
codImpuesto Código del tipo de impuesto
codProveedor Código del proveedor
codOrigen Código del país de procedencia
stockMinimo Stock mínimo aceptable del articulo
Stock Stock actual del articulo
fechaAlta Fecha en la que se ingresó al sistema el articulo
codEmbalaje Codigo del embalaje del articulo
unidadesCaja Cantidad de unidades por caja
Observaciones Observaciones
codidoBarras Código de barras del articulo
Borrado Estado del articulo
codUsuario Usuario que ingreso el articulo al sistema
Ip IP de la maquina donde se registró el articulo
fechaRegistro Fecha de registro del articulo
SubModelo Detallado de Artículos - Entidad/Atributo/Descripción Atributo
Page 170
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 170
Nombre Entidad Atributo Descripción de Atributo
Categorias codCategoria Identificador de la categoría
Categoria Descripción de la categoría
Nombre Entidad Atributo Descripción de Atributo
SubCategorias codSubCategoria Identificador de la subcategoria
SubCategoria Descripción de la subcategoria
SubModelo Categorias/Subcategorias - Entidad/Atributo/Descripción Atributo
DER – Entidad Artículos
Nombre Entidad Atributo Descripcion de Atributo
Campañas_Actua
les
Orden Orden de la campaña
Campaña Identificador de la campaña
FechaInicio Fecha de inicio del período de la campaña
FechaFin Fecha de fin del período de la campaña
SubModelo Detallado de Campañas_Actuales - Entidad/Atributo/Descripción
Atributo
Page 171
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 171
Anexo 4
Presupuesto del servidor propuesto
Page 172
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 172
Anexo 5
-- phpMyAdmin SQL Dump
-- version 3.2.4
-- http://www.phpmyadmin.net
--
-- Servidor: localhost
-- Tiempo de generación: 26-11-2012 a las 20:20:48
-- Versióndel servidor: 5.1.41
-- Versiónde PHP: 5.3.1
SET SQL_MODE="NO_AUTO_VALUE_ON_ZERO";
/*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */;
/*!40101 SET @OLD_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS */;
/*!40101 SET @OLD_COLLATION_CONNECTION=@@COLLATION_CONNECTION */;
/*!40101 SET NAMES utf8 */;
--
-- Base de datos: `dw_tesis`
--
-- --------------------------------------------------------
--
-- Estructura de tabla para la tabla `campañas_actuales`
--
CREATE TABLE IF NOT EXISTS `campañas_actuales` (
`orden` int(11) NOT NULL,
`campaña` int(11) NOT NULL,
`nombrearchivo` text NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- --------------------------------------------------------
--
Page 173
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 173
-- Estructura de tabla para la tabla `clonado_dbf_viru`
--
CREATE TABLE IF NOT EXISTS `clonado_dbf_viru` (
`CAMPA` varchar(4) DEFAULT NULL,
`CODIGO` int(11) DEFAULT NULL,
`PRODU` varchar(7) DEFAULT NULL,
`PRECIO` bigint(20) DEFAULT NULL,
`ZONA` varchar(3) DEFAULT NULL,
`CONTRATO` bigint(20) DEFAULT NULL,
`ESTADO` char(1) DEFAULT NULL,
`CANTIDAD` bigint(20) DEFAULT NULL,
`SERIE` char(1) DEFAULT NULL,
`SUCURSAL` varchar(3) DEFAULT NULL,
`TIMBRADO` varchar(3) DEFAULT NULL,
`DOC` bigint(20) DEFAULT NULL,
`TIPO` varchar(2) DEFAULT NULL,
`SUBTIPO` varchar(2) DEFAULT NULL,
`FECHA` datetime DEFAULT NULL,
`OTRODOC` varchar(20) DEFAULT NULL,
`OTROFEC` datetime DEFAULT NULL,
`OTROHOR` varchar(11) DEFAULT NULL,
`VENDEDOR` varchar(3) DEFAULT NULL,
`FECHADOC` datetime DEFAULT NULL,
`IMPRESO` char(1) DEFAULT NULL,
`COSTO` bigint(20) DEFAULT NULL,
`IMPUESTO` char(1) DEFAULT NULL,
`PREMIO` char(1) DEFAULT NULL,
`EXPREMIO` char(1) DEFAULT NULL,
`FOLLETO` varchar(10) DEFAULT NULL,
`C_UNIDADES` bigint(20) DEFAULT NULL,
`C_VENTAS` bigint(20) DEFAULT NULL,
`C_CAJA` bigint(20) DEFAULT NULL,
`VERIFI` char(1) DEFAULT NULL,
`RESULT` char(1) DEFAULT NULL,
`BRASIL_1` char(1) DEFAULT NULL,
`BRASIL_2` char(1) DEFAULT NULL,
`COLUMNA` int(11) DEFAULT NULL,
`GRUPO` varchar(8) DEFAULT NULL,
Page 174
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 174
`OPERADOR` varchar(3) DEFAULT NULL,
`PAGINA` int(11) DEFAULT NULL,
`FSCODE` bigint(20) DEFAULT NULL,
`C_CLIENTES` bigint(20) DEFAULT NULL,
`C_SUSTITU` char(1) DEFAULT NULL,
`C_PACKIN` char(1) DEFAULT NULL,
`XXUSR` varchar(15) DEFAULT NULL,
`XXFECHA` datetime DEFAULT NULL,
`XXHORA` varchar(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
-- --------------------------------------------------------
--
-- Estructura de tabla para la tabla `dw_articulos`
--
CREATE TABLE IF NOT EXISTS `dw_articulos` (
`codArticulo` int(5) unsigned zerofill NOT NULL,
`idArticulo` int(6) unsigned zerofill NOT NULL,
`codEmpresa` int(1) NOT NULL,
`Descripcion` varchar(100) CHARACTER SET utf8 NOT NULL,
`Categoria` varchar(30) NOT NULL,
`sub_categoria` varchar(30) NOT NULL,
PRIMARY KEY (`idArticulo`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
-- --------------------------------------------------------
--
-- Estructura de tabla para la tabla `dw_campañas`
--
CREATE TABLE IF NOT EXISTS `dw_campañas` (
`Campaña` int(2) unsigned zerofill NOT NULL,
`Año` int(4) unsigned zerofill NOT NULL,
`Quarter` varchar(20) CHARACTER SET latin1 NOT NULL,
PRIMARY KEY (`Campaña`,`Año`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
Page 175
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 175
-- --------------------------------------------------------
--
-- Estructura de tabla para la tabla `dw_clientes`
--
CREATE TABLE IF NOT EXISTS `dw_clientes` (
`contrato` int(11) NOT NULL,
`zona` int(11) NOT NULL,
`division` varchar(30) NOT NULL,
`departamento` varchar(30) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- --------------------------------------------------------
--
-- Estructura de tabla para la tabla `dw_consolidado`
--
CREATE TABLE IF NOT EXISTS `dw_consolidado` (
`campaña` int(11) NOT NULL,
`año` int(11) NOT NULL,
`codEmpresa` int(11) NOT NULL,
`Pedidos` int(11) NOT NULL,
`Unidades` int(11) NOT NULL,
`Facturacion` int(11) NOT NULL
) ENGINE=MyISAM DEFAULT CHARSET=latin1;
-- --------------------------------------------------------
--
-- Estructura de tabla para la tabla `dw_empresa`
--
CREATE TABLE IF NOT EXISTS `dw_empresa` (
`codEmpresa` int(11) NOT NULL AUTO_INCREMENT,
`Empresa` varchar(10) NOT NULL,
PRIMARY KEY (`codEmpresa`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1 AUTO_INCREMENT=3 ;
Page 176
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 176
-- --------------------------------------------------------
--
-- Estructura de tabla para la tabla `dw_hechospedidos`
--
CREATE TABLE IF NOT EXISTS `dw_hechospedidos` (
`campaña` int(2) unsigned zerofill DEFAULT NULL,
`año` int(4) unsigned zerofill NOT NULL,
`codEmpresa` int(11) NOT NULL,
`codArticulo` int(11) DEFAULT NULL,
`idArticulo` int(11) DEFAULT NULL,
`codCliente` int(11) DEFAULT NULL,
`cantidad` int(11) DEFAULT NULL,
`monto` int(11) DEFAULT NULL,
KEY `codCampaña` (`campaña`),
KEY `codCliente` (`codCliente`),
KEY `codEmpresa` (`codEmpresa`),
KEY `codArticulo` (`codArticulo`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
-- --------------------------------------------------------
--
-- Estructura de tabla para la tabla `dw_hechosventas`
--
CREATE TABLE IF NOT EXISTS `dw_hechosventas` (
`Campaña` int(2) unsigned zerofill DEFAULT NULL,
`Año` int(4) unsigned zerofill NOT NULL,
`codEmpresa` int(11) NOT NULL,
`numfactura` bigint(11) NOT NULL,
`codArticulo` int(11) DEFAULT NULL,
`idArticulo` int(11) DEFAULT NULL,
`codCliente` int(11) DEFAULT NULL,
`cantidad` int(11) DEFAULT NULL,
`monto` int(11) DEFAULT NULL,
KEY `codCampaña` (`Campaña`),
KEY `codCliente` (`codCliente`),
Page 177
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 177
KEY `codEmpresa` (`codEmpresa`),
KEY `codArticulo` (`codArticulo`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
-- --------------------------------------------------------
--
-- Estructura de tabla para la tabla `dw_proyeccion`
--
CREATE TABLE IF NOT EXISTS `dw_proyeccion` (
`campaña` int(2) unsigned zerofill NOT NULL,
`año` int(4) unsigned zerofill NOT NULL,
`codEmpresa` int(11) NOT NULL,
`Pedidos` int(11) NOT NULL,
`Unidades` int(11) DEFAULT NULL,
`Facturacion` decimal(12,0) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- --------------------------------------------------------
--
-- Estructura de tabla para la tabla `inter_articulos_viru`
--
CREATE TABLE IF NOT EXISTS `inter_articulos_viru` (
`codArticulo` int(5) unsigned zerofill NOT NULL,
`Descripcion` varchar(100) CHARACTER SET utf8 NOT NULL,
`Categoria` varchar(30) NOT NULL,
`sub_categoria` varchar(30) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
-- --------------------------------------------------------
--
-- Estructura de tabla para la tabla `inter_pedido_avon`
--
CREATE TABLE IF NOT EXISTS `inter_pedido_avon` (
Page 178
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 178
`campaña` int(2) unsigned zerofill NOT NULL,
`año` int(4) unsigned zerofill NOT NULL,
`codCliente` int(11) DEFAULT NULL,
`codArticulo` int(11) DEFAULT NULL,
`idArticulo` int(11) DEFAULT NULL,
`cantidad` int(11) DEFAULT NULL,
`monto` int(11) DEFAULT NULL,
`codEmpresa` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
-- --------------------------------------------------------
--
-- Estructura de tabla para la tabla `inter_pedido_viru`
--
CREATE TABLE IF NOT EXISTS `inter_pedido_viru` (
`campaña` int(2) unsigned zerofill NOT NULL,
`año` int(4) unsigned zerofill NOT NULL,
`codCliente` int(11) DEFAULT NULL,
`codArticulo` int(11) DEFAULT NULL,
`idArticulo` int(11) DEFAULT NULL,
`cantidad` int(11) DEFAULT NULL,
`monto` int(11) DEFAULT NULL,
`codEmpresa` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
-- --------------------------------------------------------
--
-- Estructura de tabla para la tabla `inter_ventas_avon`
--
CREATE TABLE IF NOT EXISTS `inter_ventas_avon` (
`numDocumento` int(11) NOT NULL,
`Campaña` int(2) unsigned zerofill NOT NULL,
`Año` int(4) unsigned zerofill NOT NULL,
`codCliente` int(11) NOT NULL,
`codArticulo` int(11) DEFAULT NULL,
Page 179
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 179
`idArticulo` int(11) DEFAULT NULL,
`cantidad` int(11) NOT NULL,
`monto` int(11) NOT NULL,
`codEmpresa` int(11) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
-- --------------------------------------------------------
--
-- Estructura de tabla para la tabla `inter_ventas_viru`
--
CREATE TABLE IF NOT EXISTS `inter_ventas_viru` (
`CAMPA` bigint(20) DEFAULT NULL,
`AÑO` smallint(4) DEFAULT NULL,
`PRODU` varchar(7) DEFAULT NULL,
`idArticulo` int(11) DEFAULT NULL,
`PRECIO` bigint(20) DEFAULT NULL,
`CONTRATO` bigint(20) DEFAULT NULL,
`CANTIDAD` bigint(20) DEFAULT NULL,
`DOC` bigint(20) DEFAULT NULL,
`codEmpresa` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
DELIMITER $$
--
-- Procedimientos
--
CREATE DEFINER=`root`@`localhost` PROCEDURE `carga_consolidado`()
BEGIN
insert into dw_consolidado select `dw_hechosventas`.`campaña` AS
`campaña`,`dw_hechosventas`.`año` AS
`año`,`dw_hechosventas`.`codEmpresa` AS `codEmpresa`,count(distinct
`dw_hechosventas`.`codCliente`) AS
`Pedidos`,sum(`dw_hechosventas`.`cantidad`) AS
`Unidades`,sum(`dw_hechosventas`.`monto`) AS `Facturacion` from
`dw_hechosventas` group by
`dw_hechosventas`.`codEmpresa`,`dw_hechosventas`.`campaña`,`dw_hec
hosventas`.`año`;
Page 180
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 180
END$$
CREATE DEFINER=`root`@`localhost` PROCEDURE `limpiar_clonado_viru`()
begin
truncate table clonado_dbf_viru;
end$$
CREATE DEFINER=`root`@`localhost` PROCEDURE `limpiar_hechospedidosAvon`()
begin
delete from dw_hechospedidos where codEmpresa=1 and año*100+campaña in (select campaña
from campañas_actuales where orden in(1,2,3));
end$$
CREATE DEFINER=`root`@`localhost` PROCEDURE `limpiar_hechospedidosViru`()
begin
delete from dw_hechospedidos where codEmpresa=2 and año*100+campaña in (select campaña
from campañas_actuales where orden in(1,2,3));
end$$
CREATE DEFINER=`root`@`localhost` PROCEDURE `limpiar_hechosventasAvon`()
begin
delete from dw_hechosventas where codEmpresa=1 and año*100+campaña in (select campaña
from campañas_actuales where orden in(1,2,3));
end$$
CREATE DEFINER=`root`@`localhost` PROCEDURE `limpiar_hechosventasViru`()
begin
delete from dw_hechosventas where codEmpresa=2 and año*100+campaña in (select campaña
from campañas_actuales where orden in(1,2,3));
end$$
CREATE DEFINER=`root`@`localhost` PROCEDURE `regresion_lineal`()
BEGIN
DECLARE _promedioX DECIMAL(20,10);
DECLARE _promedioY DECIMAL(20,10);
DECLARE _stdY DECIMAL(20,10);
DECLARE _varY DECIMAL(20,0);
DECLARE _maxY DECIMAL(20,10);
DECLARE _pendiente DECIMAL(20,10);
Page 181
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 181
DECLARE _intercepto DECIMAL(20,10);
DECLARE _empresa INT;
DECLARE _campa INT;
SET _empresa = 1;
regresion_lineal: LOOP
SELECT AVG(Unidades) INTO _promedioY FROM view_consolidado WHERE codEmpresa =
_empresa;
SELECT AVG(Pedidos) INTO _promedioX FROM view_consolidado WHERE codEmpresa =
_empresa;
SELECT STD(Unidades) INTO _stdY FROM view_consolidado WHERE codEmpresa =
_empresa;
SELECT POW(STD(Unidades),2) INTO _varY FROM view_consolidado WHERE codEmpresa
= _empresa;
SELECT MAX(Unidades) INTO _maxY FROM view_consolidado WHERE codEmpresa =
_empresa;
SELECT SUM((Unidades-_promedioY)*(Pedidos-_promedioX))/SUM(POW((Pedidos-
_promedioX),2)) INTO _pendiente
FROM view_consolidado WHERE codEmpresa = _empresa;
SET _intercepto:= _promedioY-_pendiente*_promedioX;
UPDATE dw_proyeccion SET Unidades = _pendiente * Pedidos + _intercepto WHERE
codEmpresa = _empresa;
SELECT AVG(Facturacion) INTO _promedioY FROM view_consolidado WHERE codEmpresa
= _empresa;
SELECT AVG(Pedidos) INTO _promedioX FROM view_consolidado WHERE codEmpresa =
_empresa;
SELECT STD(Facturacion) INTO _stdY FROM view_consolidado WHERE codEmpresa =
_empresa;
SELECT POW(STD(Facturacion),2) INTO _varY FROM view_consolidado WHERE
codEmpresa = _empresa;
SELECT MAX(Facturacion) INTO _maxY FROM view_consolidado WHERE codEmpresa =
_empresa;
SELECT SUM((Facturacion-_promedioY)*(Pedidos-_promedioX))/SUM(POW((Pedidos-
_promedioX),2)) INTO _pendiente
FROM view_consolidado WHERE codEmpresa = _empresa;
Page 182
Inteligencia de Negocios Tesis de Grado Ingeniería en Informática
Universidad del Cono Sur de las Américas 182
SET _intercepto:= _promedioY-_pendiente*_promedioX;
UPDATE dw_proyeccion SET Facturacion = _pendiente * Pedidos + _intercepto WHERE
codEmpresa = _empresa;
SELECT MAX(año*100+campaña) INTO _campa FROM view_consolidado WHERE
codEmpresa = _empresa;
DELETE FROM dw_proyeccion WHERE (año*100+campaña) <= _campa AND codEmpresa =
_empresa;
SET _empresa = _empresa + 1;
IF _empresa > 2 THEN
LEAVE regresion_lineal;
END IF;
END LOOP regresion_lineal;
END$$
DELIMITER ;
/*!40101 SET CHARACTER_SET_CLIENT=@OLD_CHARACTER_SET_CLIENT */;
/*!40101 SET CHARACTER_SET_RESULTS=@OLD_CHARACTER_SET_RESULTS */;
/*!40101 SET COLLATION_CONNECTION=@OLD_COLLATION_CONNECTION */;